







前言:
作为一个java攻程狮,本来是不需要了解到cpu cache这么底层的东西的。然而,如果想更好的理解java多线程的各种坑 ,了解
java多线程的精髓,又不得不了解一下,结合本人这阵子的学习,此文试图从一个小问题出发,讲讲多线程下cpu cache可能会带给我们什么“惊喜”!而为了解决这些惊喜,cpu又同时给我们提供了什么手段。
如果你想更好的了解java内存可见性,更好理解volatile,不妨花几分钟看一看本篇文章。
温馨提示: 不要太过于纠结本文讲的细节对与错,本文只想表达现实真的很复杂!这些内容也不是由我捏造出来的,是我在看了
多方面的资料后总结出来的。
问题: java中,有一个实例变量,如 public int count,然后有两个线程A和B,它们各自执行了一些动作,如下:
线程A:
count += 5;
线程B:
count += 2;
那么count最终结果会是7么?
脑洞大开:
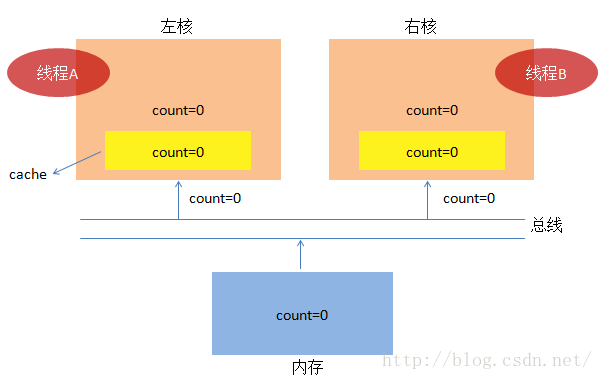
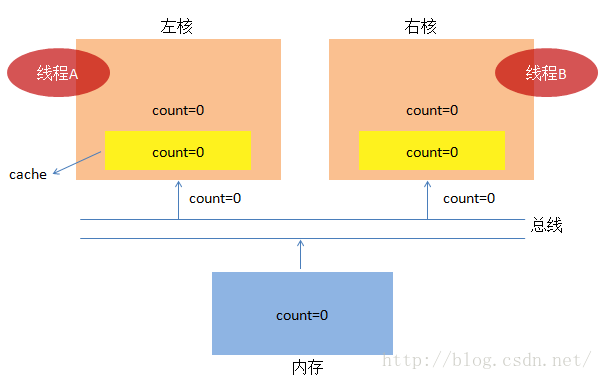
1. 咱们先回到原始社会,看看cpu可能是怎么工作的:
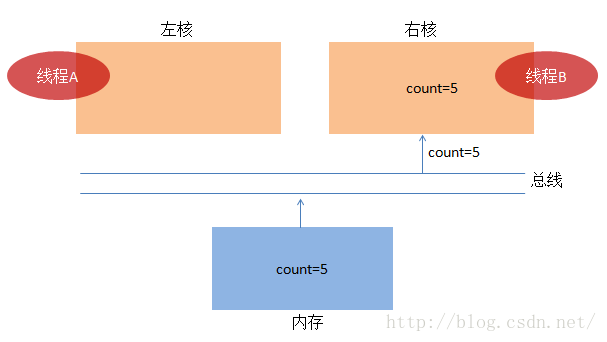
(1) 假设线程A先干完了活,然后线程B才开始干活。线程A从内存中把 count=0 加载到核内(比如寄存器),
一切准备就绪了,线程A要开始干活了。
![]()


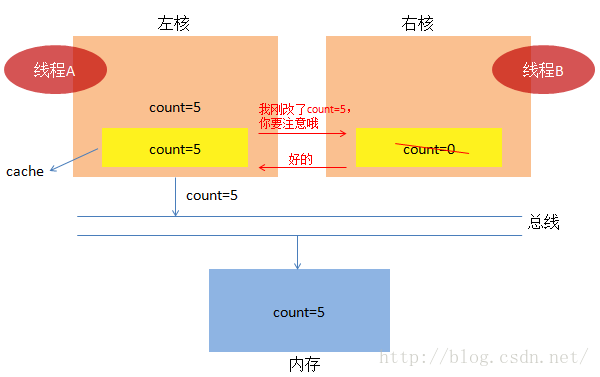
(3)我们前面说过,A干完了活,就轮到B干活了,B把值加载到右核中。
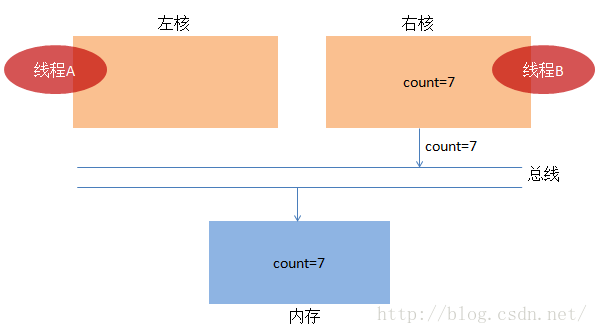
到这里,内存中值为7,已经达到大家的期望了。有没有感觉到一切好像太顺利了,好吧,我随口一问,
如果左核计算完count=5后不把值存入内存中,还是放在寄存器中,这时候右核进行计算,还能够
得出结论为7吗?
2. 社会总在进步,特别是左右两核,一直在竞争,进步特别快,计算能力加强得特别夸张。然而内存这
小子进步太慢了,为了达到一种平衡,这会多了一个叫cache的小伙伴,我们来看看。这一次,咱们假设
线程A和线程B同时干活了。
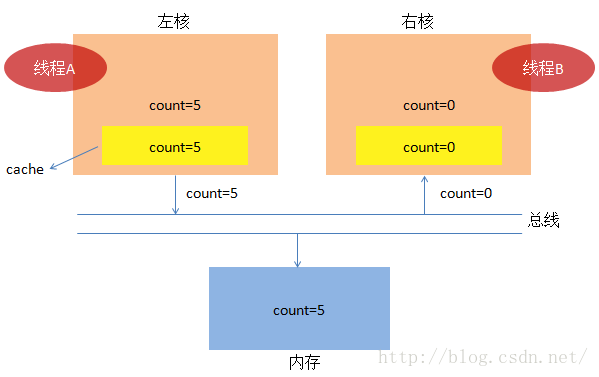
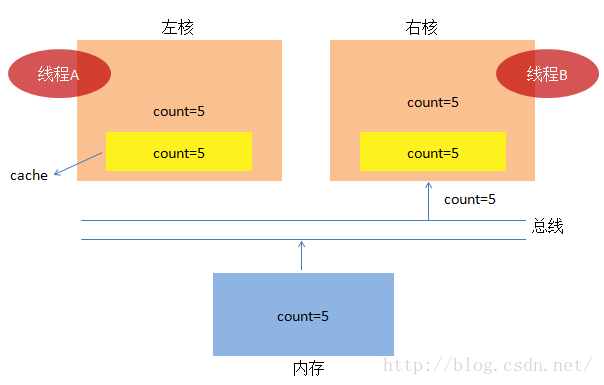
(1) 首先,两个核都想加载count的值,它们各自去黄色块cache中找count,发现找不到,结果都去内存中
加载count=0,并把值存储到黄色cache中(cache读起来非常快)。

(2) 为了一切更加顺利的进行,便于我们说明问题,我们假设线程B这时候休息了一下,线程A开始干活,
3.
到这里,你是不是想说,右核太傻了,内存值都被改为5了,你就
不可以把cache废除,重新加载 count=5再做计算么?这样结果会是7,不就OK了。为了满足这个小小的要求,
于是乎历史再次上演了。
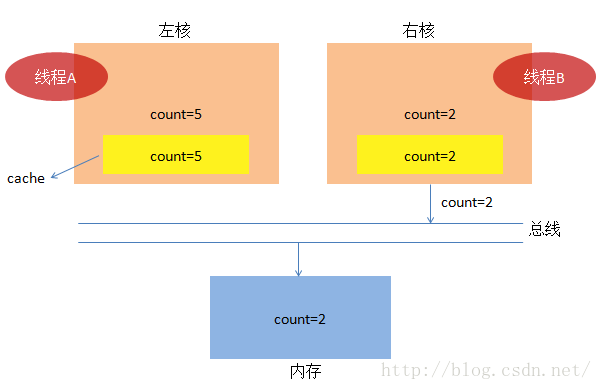
(1) 我们依然假定线程A和线程B同时执行,起初,他们又同时把count=0加载到核内,同时放入cache中。
(3)又轮到线程B上场了,B发现cache中的count失效了,于是乎从内存中加载了最新的count=5,
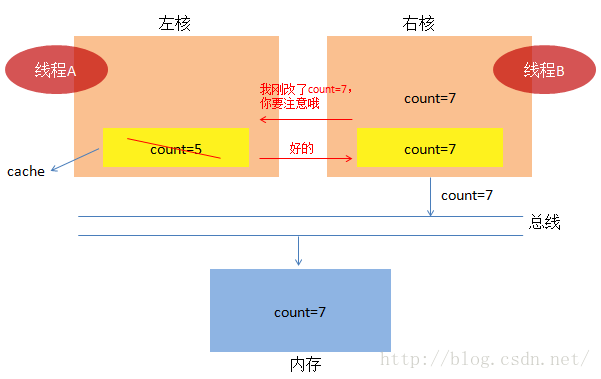
4. 初步看,cache间加上了通知机制(实则为类MESI缓存一致性协议),一切好像朝着美好的方向前进着,
然而,伟大的设计师们觉得通知来通知去,效率太低了,继续改改改,于是乎咱们就再来一次吧。
(1) 我们依然假定线程A和线程B同时执行,起初,他们又同时把count=0加载到自己的缓存中。
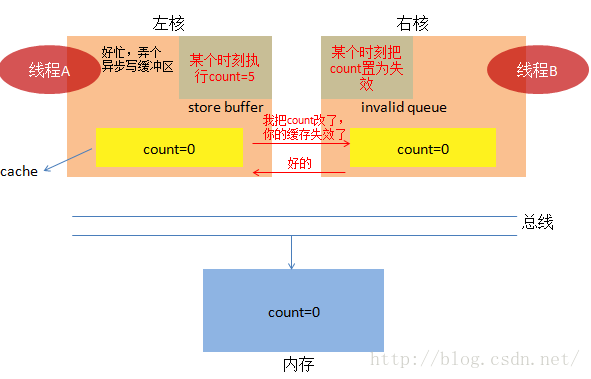
这一次,左核支出新招了,整了个叫store buffer的写缓存区,为啥呢?写操作太慢了呗,受不了啦。每当
有内存写操作,它通知一下右核,比如,它告诉右核,count值我改了,你的cache失效了,右核听到消息后,
会说,好的,你放心干吧。然后左核把写操作放到异步队列中,异步慢慢的执行。
而右核呢,也耍小聪明了,它并没有直接把它cache中的count立即改为失效,它只是把这个动作放到一个称
为invalid queue的队列,等着异步再慢慢执行。
(3) 就是因为大家都耍了小把戏,结果你看到了,事情已经很复杂了。不管怎样,线程B还是得接着干活。
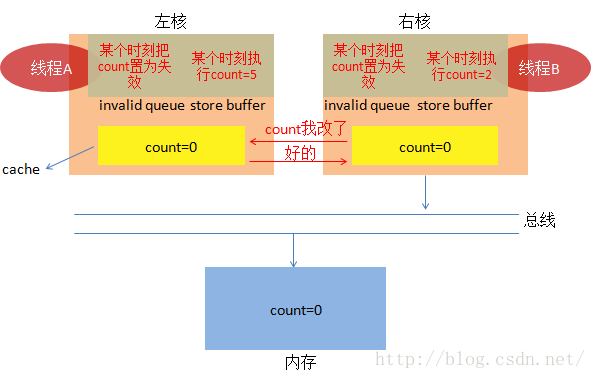
脑洞大开的后话:
你看到了,我作了很多的假设,就已经得出了这么复杂的情况,如果映射到多种实际的平台,那又会是怎样混乱
的场面呢。也许,有同学想反驳我,我讲的也许不太对,但我想说的是,事实比我讲的要更加多样化、复杂化,我只是
进行了几种可能的抽象,为了引出多线程中我们可能会遇到的棘手的问题。怎么确保原子操作,怎么确保共享变量
在多线程中的可见性?显然cpu的设计者们也知道多线程下有很多未知的可能,于是乎,他们提供了一些方案,
用于控制这种混乱的局面。在这里,我把它归为两类:lock前缀和内存屏障。
lock前缀 和 内存屏障
关于这个话题,各种地方一搜,都有好多好多介绍的文章。所以本文不会罗列太多理论的东西。我们先来看看
lock前缀。
现实中,在intel cpu中,是存在 lock前缀的,所谓 lock前缀指的是在某些特定汇编指令中,添加上一个lock标识,
就会拥有神奇的功能,比如:
1) 执行lock前缀汇编指令的cpu会对外宣称指定内存地址的主权,如果有其它核也想操作指定内存地址,不好意思,请等待,先
让我忙完再说,而且总能拿到最新的内存的值。
2) 看看前面提到的store buffer,lock前缀能够确保把 store buffer的指令全部执行完了,使其结果对其它核所见。这里我理解是
其它核不一定会立即把cache置为失效,因为有 invalid queue的存在。这也就是说 lock前缀并不是万能的,还是可能
会有共享变量可见性问题。这种情况得借助牛B轰轰的内存屏障了。
3)lock前缀指令一出现,cpu便不会把lock前缀指令两边的指令进行重排,从而能够保证一些可见性。
再来简单看看内存屏障,内存屏障可以认为是一些特殊的汇编指令,它有一些特殊的功效,简要概括之:
1) 内存屏障有多种,咱们暂且归为 写屏障,读屏障两种。
2) 写屏障指令一出现,cpu必须确保屏障两边的写指令不可以跨越屏障调整执行顺序,而且有些写屏障指令强大到可以号令cpu,
在屏障执行完之前,store buffer的所有指令必须先执先完毕,这样其他cpu cache才可以感知到(由于invalid queue的存在,
感知到却不一定会立即处理),所以一般写屏障得结合读屏障才有效果。
3)由2我们知道,即使有强大的写屏障功能,但是类似invalid queue之类的存在,还是影响到其他cpu对共享变量最新值的获取,
那该怎么办呢?这时候强大的读屏障指令出现了。读屏障,你可以认为有两个功效,一个仍然是阻止cpu乱改读指令的顺序,另
一个就是可以让cpu把invalid queue的消息先处理完了,再继续干活。一旦cpu把invalid queue中的消息处理完了,即意味着
该cpu会把该作废的缓存作废,下次读一个新的共享变量时,就可以“见到”共享变量的最新值了。
4) 作为java攻城狮,我想你一定会了解到什么是volatile写和volatile读,你会发现跟内存读写屏障的语义真像。
由于cpu本身的不确定性和复杂性,在多线程模型下,很多时候,事情的发生往往出人意料。编译器,CPU为了优化,采用了
各种我们难以察觉的措施,但是他们能够承诺的是,如果我们的程序全部跑在单线程中,一切都会按我们所想所思去执行,但
一旦涉及到多线程,不好意思,程序完全杂乱无章了。这时候,我们只能借助如lock和内存屏障之类强大的武器来处理变量的可
见性以及程序的原子性和正确性。
讲得有点多了,为了让大家更好消化,什么指令重排之类的就不再多说了,好多地方都有相应的参考资料,只不过很多时候,
他们没有把cpu cache这种隐藏得很深的问题给抛出来而已,所以这也是我写本篇的目的,结合这阵子的学习,既是一个总结,
也希望能够给看客一点启发和思路。















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









