








1.

代码示例:
# ========================== 1 num_samples=0
flag = 0
# flag = 1
if flag:
# train_dir = os.path.join("..", "data", "rmb_split", "train")
train_dir = os.path.join("..", "..", "data", "rmb_split", "train")
train_data = RMBDataset(data_dir=train_dir)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
2.
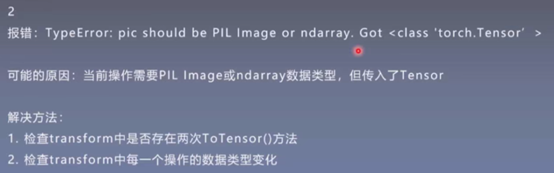
代码示例:
# ========================== 2
# TypeError: pic should be PIL Image or ndarray. Got <class 'torch.Tensor'>
flag = 0
# flag = 1
if flag:
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.FiveCrop(200),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# transforms.ToTensor(),
# transforms.ToTensor(),
])
train_dir = os.path.join("..", "..", "data", "rmb_split", "train")
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data, label = next(iter(train_loader))
3.

代码示例:
# ========================== 3
# RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0
flag = 0
# flag = 1
if flag:
class FooDataset(Dataset):
def __init__(self, num_data, data_dir=None, transform=None):
self.foo = data_dir
self.transform = transform
self.num_data = num_data
def __getitem__(self, item):
size = torch.randint(63, 64, size=(1, )) #[63,64)]
fake_data = torch.zeros((3, size, size))
fake_label = torch.randint(0, 10, size=(1, ))
return fake_data, fake_label
def __len__(self):
return self.num_data
foo_dataset = FooDataset(num_data=10)
foo_dataloader = DataLoader(dataset=foo_dataset, batch_size=4)
data, label = next(iter(foo_dataloader))
4.

代码示例:
# ========================== 4
# Given groups=1, weight of size 6 3 5 5, expected input[16, 1, 32, 32] to have 3 channels, but got 1 channels instead
# RuntimeError: size mismatch, m1: [16 x 576], m2: [400 x 120] at ../aten/src/TH/generic/THTensorMath.cpp:752
flag = 0
# flag = 1
if flag:
class FooDataset(Dataset):
def __init__(self, num_data, shape, data_dir=None, transform=None):
self.foo = data_dir
self.transform = transform
self.num_data = num_data
self.shape = shape
def __getitem__(self, item):
fake_data = torch.zeros(self.shape)
fake_label = torch.randint(0, 10, size=(1, ))
if self.transform is not None:
fake_data = self.transform(fake_data)
return fake_data, fake_label
def __len__(self):
return self.num_data
# ============================ step 1/5 数据 ============================
channel = 3 # 1 3
img_size = 32 # 36 32
train_data = FooDataset(num_data=32, shape=(channel, img_size, img_size))
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10)
# ============================ step 5/5 训练 ============================
data, label = next(iter(train_loader))
outputs = net(data)
5.

代码示例:
# ========================== 5
# AttributeError: 'DataParallel' object has no attribute 'linear'
flag = 0
# flag = 1
if flag:
class FooNet(nn.Module):
def __init__(self):
super(FooNet, self).__init__()
self.linear = nn.Linear(3, 3, bias=True)
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(5)
def forward(self, x):
return 1234567890
net = FooNet()
for layer_name, layer in net.named_modules():
print(layer_name)
net = nn.DataParallel(net)
for layer_name, layer in net.named_modules():
print(layer_name)
print(net.module.linear) #Parallel后需要采用module来调用
6.

代码示例:
# ========================== 6
# RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False.
# If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu')
# to map your storages to the CPU.
flag = 0
# flag = 1
if flag:
path_state_dict = "./model_in_multi_gpu.pkl"
state_dict_load = torch.load(path_state_dict)
# state_dict_load = torch.load(path_state_dict, map_location="cpu")
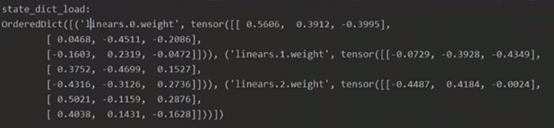
7.

代码示例:
# ========================== 7
# AttributeError: Can't get attribute 'FooNet2' on <module '__main__' from '
# flag = 0
flag = 1
if flag:
path_net = os.path.join(BASE_DIR, "foo_net.pkl")
# save
class FooNet2(nn.Module):
def __init__(self):
super(FooNet2, self).__init__()
self.linear = nn.Linear(3, 3, bias=True)
def forward(self, x):
return 1234567890
#
# net = FooNet2()
# torch.save(net, path_net)
# load
net_load = torch.load(path_net)
8.

代码示例:
# ========================== 8
# RuntimeError: Assertion `cur_target >= 0 && cur_target < n_classes' failed.
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 0, 1], dtype=torch.long) #[0, 0, 2]会报错,因为是二分类任务。,只有0,1
criterion = nn.CrossEntropyLoss()
loss = criterion(inputs, target)
9.

代码示例:
# ========================== 9
# RuntimeError: expected device cuda:0 and dtype Long but got device cpu and dtype Long
flag = 0
# flag = 1
if flag:
x = torch.tensor([1]) #x默认在cpu
w = torch.tensor([2]).to(device) #y to到gpu
# y = w * x
x = x.to(device) #x to到gpu
y = w * x
10.

代码示例:
# ========================== 10
# RuntimeError: Expected object of backend CPU but got backend CUDA for argument #2 'weight'
# flag = 0
flag = 1
if flag:
def data_loader(num_data):
for _ in range(num_data):
img_ = torch.randn(1, 3, 224, 224)
label_ = torch.randint(0, 10, size=(1,))
yield img_, label_
resnet18 = models.resnet18()
resnet18.to(device)
for inputs, labels in data_loader(2):
# inputs.to(device) #tensor的to操作不是inplace操作,需要赋值
# labels.to(device)
# outputs = resnet18(inputs)
inputs = inputs.to(device)
labels = labels.to(device)
outputs = resnet18(inputs)
print("outputs device:{}".format(outputs.device))

完整代码
common_errors.py
# -*- coding: utf-8 -*-
"""
# @file name : common_errors.py
# @brief : 常见errors
"""
import os
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.models as models
from torch.utils.data import DataLoader
from tools.my_dataset import RMBDataset
from torch.utils.data import Dataset
from model.lenet import LeNet
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# ========================== 1 num_samples=0
flag = 0
# flag = 1
if flag:
# train_dir = os.path.join("..", "data", "rmb_split", "train")
train_dir = os.path.join("..", "..", "data", "rmb_split", "train")
train_data = RMBDataset(data_dir=train_dir)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
# ========================== 2
# TypeError: pic should be PIL Image or ndarray. Got <class 'torch.Tensor'>
flag = 0
# flag = 1
if flag:
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.FiveCrop(200),
transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),
# transforms.ToTensor(),
# transforms.ToTensor(),
])
train_dir = os.path.join("..", "..", "data", "rmb_split", "train")
train_data = RMBDataset(data_dir=train_dir, transform=train_transform)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
data, label = next(iter(train_loader))
# ========================== 3
# RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0
flag = 0
# flag = 1
if flag:
class FooDataset(Dataset):
def __init__(self, num_data, data_dir=None, transform=None):
self.foo = data_dir
self.transform = transform
self.num_data = num_data
def __getitem__(self, item):
size = torch.randint(63, 64, size=(1, )) #[63,64)]
fake_data = torch.zeros((3, size, size))
fake_label = torch.randint(0, 10, size=(1, ))
return fake_data, fake_label
def __len__(self):
return self.num_data
foo_dataset = FooDataset(num_data=10)
foo_dataloader = DataLoader(dataset=foo_dataset, batch_size=4)
data, label = next(iter(foo_dataloader))
# ========================== 4
# Given groups=1, weight of size 6 3 5 5, expected input[16, 1, 32, 32] to have 3 channels, but got 1 channels instead
# RuntimeError: size mismatch, m1: [16 x 576], m2: [400 x 120] at ../aten/src/TH/generic/THTensorMath.cpp:752
flag = 0
# flag = 1
if flag:
class FooDataset(Dataset):
def __init__(self, num_data, shape, data_dir=None, transform=None):
self.foo = data_dir
self.transform = transform
self.num_data = num_data
self.shape = shape
def __getitem__(self, item):
fake_data = torch.zeros(self.shape)
fake_label = torch.randint(0, 10, size=(1, ))
if self.transform is not None:
fake_data = self.transform(fake_data)
return fake_data, fake_label
def __len__(self):
return self.num_data
# ============================ step 1/5 数据 ============================
channel = 3 # 1 3
img_size = 32 # 36 32
train_data = FooDataset(num_data=32, shape=(channel, img_size, img_size))
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True)
# ============================ step 2/5 模型 ============================
net = LeNet(classes=2)
# ============================ step 3/5 损失函数 ============================
criterion = nn.CrossEntropyLoss()
# ============================ step 4/5 优化器 ============================
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9) # 选择优化器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10)
# ============================ step 5/5 训练 ============================
data, label = next(iter(train_loader))
outputs = net(data)
# ========================== 5
# AttributeError: 'DataParallel' object has no attribute 'linear'
flag = 0
# flag = 1
if flag:
class FooNet(nn.Module):
def __init__(self):
super(FooNet, self).__init__()
self.linear = nn.Linear(3, 3, bias=True)
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(5)
def forward(self, x):
return 1234567890
net = FooNet()
for layer_name, layer in net.named_modules():
print(layer_name)
net = nn.DataParallel(net)
for layer_name, layer in net.named_modules():
print(layer_name)
print(net.module.linear) #Parallel后需要采用module来调用
# ========================== 6
# RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False.
# If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu')
# to map your storages to the CPU.
flag = 0
# flag = 1
if flag:
path_state_dict = "./model_in_multi_gpu.pkl"
state_dict_load = torch.load(path_state_dict)
# state_dict_load = torch.load(path_state_dict, map_location="cpu")
# ========================== 7
# AttributeError: Can't get attribute 'FooNet2' on <module '__main__' from '
# flag = 0
flag = 1
if flag:
path_net = os.path.join(BASE_DIR, "foo_net.pkl")
# save
class FooNet2(nn.Module):
def __init__(self):
super(FooNet2, self).__init__()
self.linear = nn.Linear(3, 3, bias=True)
def forward(self, x):
return 1234567890
#
# net = FooNet2()
# torch.save(net, path_net)
# load
net_load = torch.load(path_net)
# ========================== 8
# RuntimeError: Assertion `cur_target >= 0 && cur_target < n_classes' failed.
flag = 0
# flag = 1
if flag:
inputs = torch.tensor([[1, 2], [1, 3], [1, 3]], dtype=torch.float)
target = torch.tensor([0, 0, 1], dtype=torch.long) #[0, 0, 2]会报错,因为是二分类任务。,只有0,1
criterion = nn.CrossEntropyLoss()
loss = criterion(inputs, target)
# ========================== 9
# RuntimeError: expected device cuda:0 and dtype Long but got device cpu and dtype Long
flag = 0
# flag = 1
if flag:
x = torch.tensor([1]) #x默认在cpu
w = torch.tensor([2]).to(device) #y to到gpu
# y = w * x
x = x.to(device) #x to到gpu
y = w * x
# ========================== 10
# RuntimeError: Expected object of backend CPU but got backend CUDA for argument #2 'weight'
# flag = 0
flag = 1
if flag:
def data_loader(num_data):
for _ in range(num_data):
img_ = torch.randn(1, 3, 224, 224)
label_ = torch.randint(0, 10, size=(1,))
yield img_, label_
resnet18 = models.resnet18()
resnet18.to(device)
for inputs, labels in data_loader(2):
# inputs.to(device) #tensor的to操作不是inplace操作,需要赋值
# labels.to(device)
# outputs = resnet18(inputs)
inputs = inputs.to(device)
labels = labels.to(device)
outputs = resnet18(inputs)
print("outputs device:{}".format(outputs.device))















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









