








- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾: 【论文精读】上交大、上海人工智能实验室等提出基于配准的少样本异常检测框架超详细解读(翻译+精读)
- 每日一言🌼: 人只有知道自己无知后,才能从骨子里谦和起来,不再恃才傲物,不再咄咄逼人。 – 莫言
0、前言:
- Map:每次对一行数据进行操作
- Reduce:对具有同一个
key的所有k-v进行操作
单选和多选略,已上传到资源
一、单选
二、多选
三、简答题
1. Hadoop启动的进程有哪些?
请列出正常工作的hadoop集群中Hadoop都分别需要启动哪些进程,他
们的作用分别是什么,尽可能的全面些。
- NameNode(维转):
1NameNode 是 HDFS 中的主节点,负责维护文件系统的元数据(如文件目录结构、文件块与 DataNode 的映射关系等)。2它不接受客户端的读写请求,而是将请求转发给DataNode,并协调数据的读写操作。 - SecondNameNode(冷备):冷备,对一定范围内数据做快照性备份
- Datanode(实存读写发心跳):
1DataNode 是 HDFS 中的从节点,负责存储实际的数据块。2客户端通过与 NameNode通信获取数据块的存储位置,然后直接与 DataNode 进行数据的读写操作。3DataNode 还会定期向 NameNode 发送心跳信息,以报告自身的状态和数据块的完整性。 - ResourceManager(资源管理调度又监控):
1资源管理:管理集群的计算资源;2任务调度:根据资源可用性和调度策略,将任务分配给合适的节点;3监控Applicationmager:监控其状态,并在其失败时重启它。 - NodeManager:是 yarn 中每个节点上的代理,它管理 hadoop 集群中单个计算节点,包括与 resoucemanager 保持通信,监督 container 的生命周期管理,监控每个 container 的资源使用(内存、cpu 等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务。
2. Hadoop调度器(schedular)
- FIFO Schedular先进先出(默认)
- Capacity Schedular:计算能力调度器,选择占用最小,优先级高的先执行
- Fair Schedular:公平调度,所有的Job具有相同的资源
3. 执行流程图
3.1Hdfs读流程
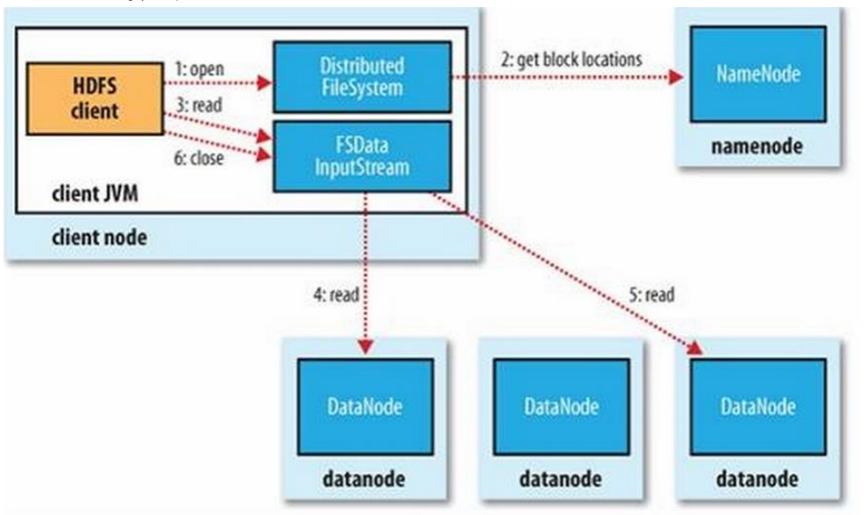
- 首先
1.open,客户端打开分布式文件系统 - 与Namenode交互
2.read:客户端像namenode发送请求,获取要读取文件的位置信息,包括组成该文件的所有数据块,以及它们的Datanode所在地址 3.read:得到文件数据块信息后,客户端会通过输入流和DataNode进行交互以读取数据4,5:客户端会并行地从多个DataNode读取数据,以提高读取效率;在本地重新组装文件,还原原始文件6.close:文件读取完毕后,客户端关闭与Datanode和NameNode的连接
3.2Hdfs写流程
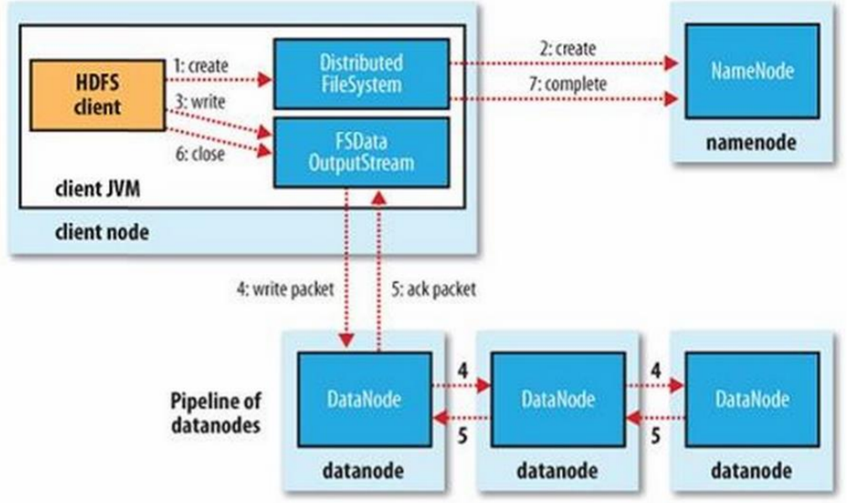
写:
1 客户端向NameNode发送写入文件的请求
2 NameNode响应请求:检查自身是否正常运行,判断要创建的文件是否存在、客户端是否拥有创建文件的权限。如果以上检查均通过,NameNode会在HDFS文件系统中创建一个空文件,并把这一操作记录在edits.log中。如果检查中有任何一项没有通过,则NameNode会向客户端抛异常,文件创建失败。
3 文件切分:客户端将待写入的文件分成固定大小的数据块(128M)。每个数据库都会被分配一个唯一的块标识符/
4 数据块副本选择:在写入数据块之前,客户端需要选择数据库的副本位置。这通常是基于HDFS的副本放置策略,旨在减少数据的传播的开销和延迟。
5 数据块写入:客户端将数据块分别发送给副本所在的DataNode。DataNode接收到数据块后,会将数据块暂存到本地磁盘的临时文件上。
6 数据块复制。一旦数据块被写入到了一个DataNode的临时文件中。该DataNode会将其复制到其他副本位置所在的DataNode上
7 副本确认:当所有副本都完成数据写入后,DataNode会向客户端发送副本确认信息。客户端收到所有副本确认信息后,将告知NameNode数据块写入完成
3.3Mapreduce的执行过程
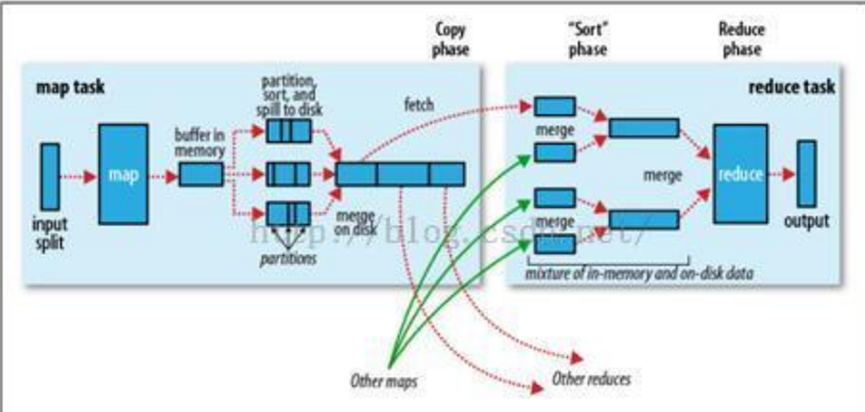
- Map任务,5个步骤:
- split 的目的是将一个原始文件分成多个文件,分别交由不同的 map 节点处理
- map
- buffer in memory内存溢出,写入磁盘
- partition sort and spill to disk
- combine:每个 map 任务执行过程中有可能会溢写生成多个文件,而 map 任务结束 后需要将结果传到 reduce 任务节点,为提高效率需在网络传输文件前将多个小文件 合并成大文件,combine 是 map 节点本地 reduce 过程。
⭐
- 输入阶段:MapReduce 作业从 HDFS 或其他输入源读取数据。
- Map 阶段:Map 任务将输入数据划分为多个键值对,并对其进行处理。处理结果作为中间键值对输出到本地磁盘。
- Shuffle 阶段:MapReduce 框架将 Map 任务输出的中间键值对按照键进行排序和分组,并将相同键的值传递给 Reduce 任务。
- Reduce 阶段:Reduce 任务接收 Shuffle 阶段传递过来的键值对,对它们进行聚合处理,并将结果输出到 HDFS 或其他输出源。
- 输出阶段:MapReduce 作业将 Reduce 任务输出的结果存储到 HDFS 或其他输出目标。
Reduce阶段:四个步骤Merge-----sort-------reduce-----output
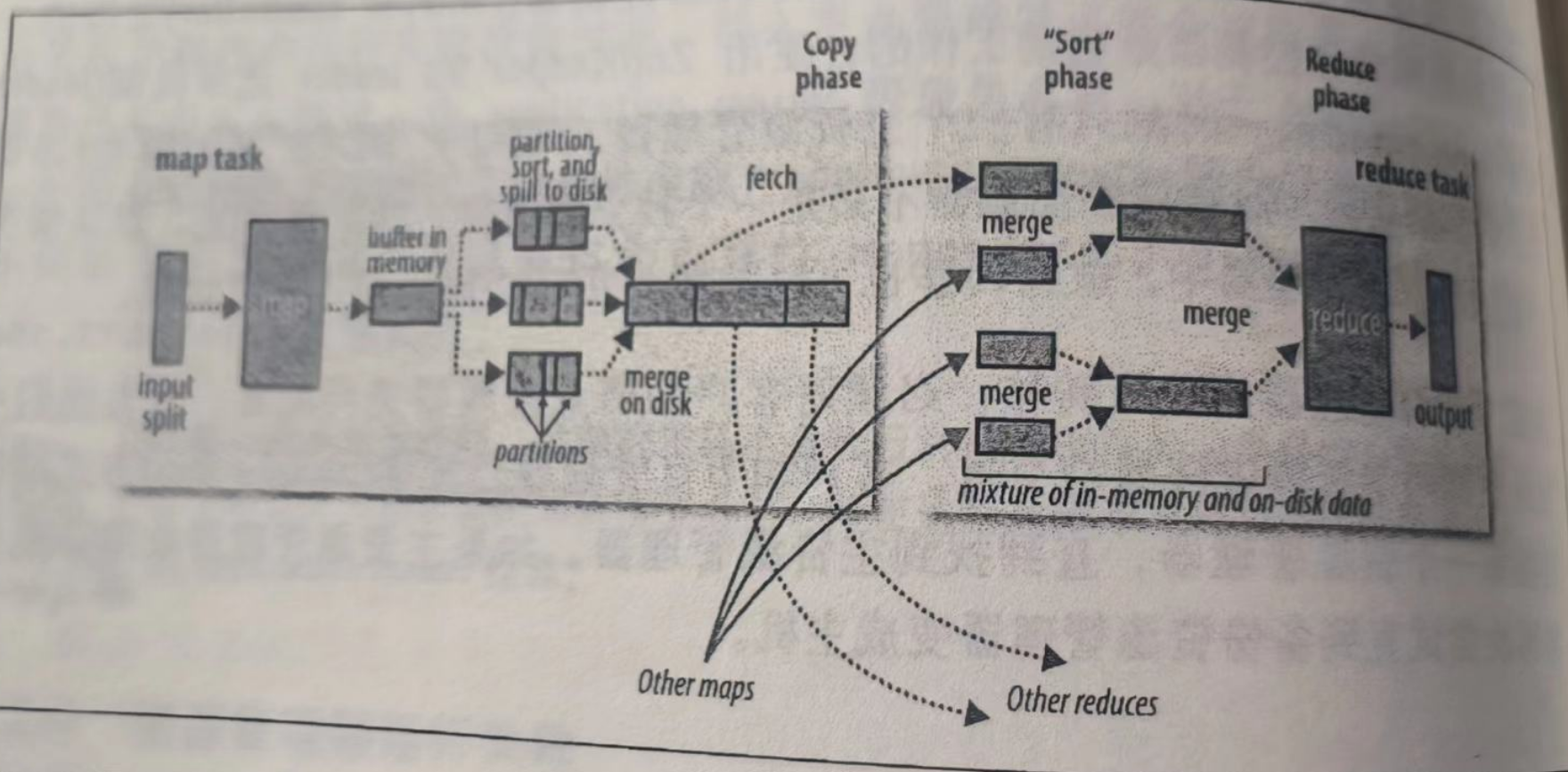
4.MapReduce中combiner,partition作用
- Partition(分区发送便聚合):分区,对Map输出的键值对结果根据键的哈希值或其他逻辑将数据划分进行分区,决定Mapper生成的中间结果中,每条记录应该送往哪个reducer节点。这种设计可以确保具有相同键的数据被发送到同一个 Reducer 进行处理,从而便于在 Reduce阶段进行聚合操作。
- Combiner(合并减宽减计算):相当于一个
Local Reducer,通常和Reduce的逻辑差不多,在Map输出阶段合并相同key对应的value。有两个作用- 减少网络带宽:减少从
Map到Reduce的数据传输量 - 减少Reduce计算量,提高执行效率
- 减少网络带宽:减少从
5. 内部表与外部表区别(从创建和删除的角度)。
- 创建表阶段:外部表创建表的时候,不会移动数到数据仓库目录中(/user/hive/warehouse),只会记录表数据存放的路径, 内部表会把数据复制或剪切到表的目录下。
- 删除表阶段:
外部表在删除表的时候只会删除表的元数据信息不会删除表数据,内部表删除时会将元数据信息和表数据同时删除
6.Hadoop 的 2 个主要组件及其功能
Hadoop 主要由两个核心组件组成:Hadoop Distributed File System (HDFS) 和 MapReduce。
- HDFS(管理存储主从架):Hadoop 的分布式文件系统,用于存储和管理大数据集。它采用主/从架构,包括一个 NameNode(主节点)和多个 DataNode(从节点)。NameNode 管理文件系统的元数据,而 DataNode 存储实际的数据块。
- MapReduce(编程架构处数据):Hadoop 的编程框架,用于处理存储在 HDFS 中的大数据。它将复杂的数据处理任务分解为两个主要阶段:Map 阶段和 Reduce 阶段。Map 阶段将数据划分为多个键值对,Reduce 阶段则对这些键值对进行聚合和输出。
7.NameNode 和 DataNode 分别承担什么角色?
-
NameNode(维转):
1NameNode 是 HDFS 中的主节点,负责维护文件系统的元数据(如文件目录结构、文件块与 DataNode 的映射关系等)。2它不接受客户端的读写请求,而是将请求转发给DataNode,并协调数据的读写操作。 -
Datanode(实存、读写、发心跳):
1DataNode 是 HDFS 中的从节点,负责存储实际的数据块。2客户端通过与 NameNode通信获取数据块的存储位置,然后直接与 DataNode 进行数据的读写操作。3DataNode 还会定期向 NameNode 发送心跳信息,以报告自身的状态和数据块的完整性。
8.单点故障问题
Hadoop 集群中的 NameNode 单点故障问题可以通过设置 NameNode 的高可用(HA) 来解决。HA 配置使用两个 NameNode 实例,一个处于活动状态(Active),另一个处于备用状态(Standby)。当活动 NameNode 出现故障时,备用 NameNode 会自动接管其工作,从而确保集群的连续性和可用性。
此外,还可以使用 Zookeeper 等分布式协调服务来监控和管理 NameNode 的状态和切换过程。
9.述 Hadoop 在大数据处理中的优势——凌晨扩容
- 可扩展性:Hadoop 能够处理 PB 级甚至更大的数据集,通过增加节点可以轻松地扩展集群的处理能力。
- 容错性:Hadoop 采用分布式存储和计算的方式,将数据分散存储在多个节点上,并通过数据冗余和故障恢复机制保证数据的高可用性。
- 灵活性:Hadoop 支持多种编程语言和工具进行数据处理,如 Java、Python 等,同时提供了丰富的 API 和生态系统供开发者使用。
- 成本效益:Hadoop 运行在普通硬件上,相比传统的高性能计算集群具有更低的成本。同时,Hadoop 的开源特性使得用户可以免费获取和使用它。
10. FsImage 镜像文件和 EditLog 日志文件 HDFS 中提供的 Secondary NameNode 节点的职责。
-
存整命息:FsImage 镜像文件用于存储整个文件系统命名空间的信息
-
持久记录元变化:EditLog 日志文件用于持久化记录文件系统元数据发生的变化。
-
周期合并减大小;缩短重启保完整:Secondary NameNode 节点主要是周期性的把 NameNode 中的 EditLog 日志文件合并到FsImage 镜像文件中,从而减小 EditLog 日志文件的大小,缩短集群重启时间,并且也保证了 HDFS 系统的完整性。
11Hadoop 中的 Block 是什么?为什么需要它?
- Hadoop 中的 Block 是 HDFS 中数据存储的基本单位,通常大小为 128MB(可配置)。HDFS将数据划分为多个 Block,并将它们分散存储在集群中的多个 DataNode 上。
- 这种设计提高了数据的可靠性和可扩展性,因为每个 Block 都有多个副本存储在不同的节点上,并且可以通过增加节点来扩展存储能力。
12. Yarn提交作业的流程

- 作业提交:(集群、RM)(1~4)
- 提作业,请ID:Client(客户端)调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业。Client 向 ResourceManager(RM)申请一个作业 ID。
- 反作业,反ID:RM 给 Client 返回该 job 的资源提交路径和作业 ID。
- 提Jar、切、配:Client 提交 jar 包、切片信息和配置文件到指定的资源提交路径。
- 申请运行:Client 提交完资源后,向 RM 申请运行 MRAppMaster(MapReduce 应用程序主)。
- 作业初始化:(RM)(5~7)
- job加入容量器:当 RM 收到 Client 的请求后,将该 job 添加到容量调度器中。
- NM领Job,创container,产程序主:某一个空闲的 NodeManager(NM)领取到该 Job。该 NM 创建 Container,并产生 MRAppMaster。
- 下资到本地:下载 Client 提交的资源到本地
- 资源分配:(MRAppMaster,RM的Application Manager)(8)
- 程序主和程序管理器交互获资源:MRAppMaster 与 RM 的应用程序管理器(Application Manager)进行交互,协商以获取运行作业所需的资源。
- RM调度器依策略分资源:RM 的调度器根据集群的资源情况和配置的调度策略(如容量调度、公平调度等),将源分配给 MRAppMaster。
- 任务执行:(9-11)
- 细分资源:MRAppMaster 将获取到的资源分配给各个 NM。(9~10)
- 执行MRtask:NM 上的 Executor(执行器)根据分配到的资源和作业的具体任务,开始执行 Map Task 或Reduce Task。(11)
- 作业监控和完成:(RM,MRAppMAster)
-
监控:RM 的应用程序管理器负责监控 MRAppMaster 的运行状态,并在必要时进行重启。
-
通知完成:当所有任务执行完毕后,MRAppMaster 通知 RM 作业已完成。
-
取结果:Client 通过 RM 获取作业完成状态,并获取结果。
四、编程题
1.
1.当前日志采样格式为:
• a,b,c,d
• b,b,f,e
• a,a,c,f • 请用你最熟悉的语言编写一个map/reduce程序,计算第四列每个元素出现
的个数。
public void map(Object key, Text value, Context context){
IntWritable one = new IntWritable(1);//输出的value
Text fourthElement = new Text(); //输出的key
//使用StringTonkenizer对该行文本进行切分
StringTokenizer itr = new StringTokenizer(value.toString(),",");
int colCount = 0;
for(itr.hasMoreTokens()) {
String token = itr.nextToken();
colCount++;
if(colCount == 4) {
fourthElement.set(token);
context.write(fourthElement, one);
}
}
}
public void reduce(Text key, Iterable <IntWritable> values, Context context) {
//输出结果
IntWritable result = new IntWritable();
int sum = 0;
for(IntWritable val : values){
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
2.
原机器人发言文件:
• 08ERSADSWERDS 哈哈 0 我的宝,你好?
• 09FGSDASEWQDD 雷猴 1 http://127.0.0.1/aaa.jpg
• 08ERSADSWERDS 哈哈 0 我的宝怎么不说话?
• 7876DSADASDSA 嘻嘻 0 我们分手吧
• 第一列为机器人id。
• 第二列为机器人昵称。
• 第三列为发言的类型: 0-文字 1-图片。
• 第四列为发言内容。
• 2. 我们要统计每个机器人发言的文字条数, 图片条数。如:
• 哈哈 文字总条数:2 , 图片总条数:0
• 嘻嘻 文字总条数:1 , 图片总条数:0
• 雷猴 文字总条数:0 , 图片总条数:1
public void map(Object key, Text value, Context context) {
// 用于存储机器人昵称和发言类型的组合键
Text robotNickname = new Text();
Text messageType = new Text();
// 使用StringTokenizer将每行文本分割为列
StringTokenizer itr = new StringTokenizer(value.toString(), " ");
// 获取各列数据
String robotId = itr.nextToken();
String nickname = itr.nextToken();
String type = itr.nextToken();
String content = itr.nextToken();
// 设置机器人昵称
robotNickname.set(nickname);
// 设置消息类型
if ("0".equals(type)) {
messageType.set("text");
} else if ("1".equals(type)) {
messageType.set("image");
} else {
return; // 忽略其他类型
}
// 组合键:昵称 + 消息类型
context.write(robotNickname, messageType);
}
public void reduce(Text key, Iterable<Text> values, Context context) {
int textCount = 0;
int imageCount = 0;
// 遍历所有的值,统计文字条数和图片条数
for (Text val : values) {
if ("text".equals(val.toString())) {
textCount++;
} else if ("image".equals(val.toString())) {
imageCount++;
}
}
// 输出结果
String result = "文字总条数:" + textCount + ",图片总条数:" + imageCount;
context.write(key, new Text(result));
}
3.
- 需求: 有如下指定时间,指定手机号通话时长文件:
• 13632433234 15 2021-11-20
• 19832433234 10 2021-11-20
• 13632433234 12 2021-11-21
• 13986255437 41 2021-11-19
• 13632433234 分别在 20号通话15分钟,在21号通话12分钟。
• 我们要统计:每个手机号总通话时长,并且136开头的手机号统计到一个文
件,198开头也统计到另一个文件。。
public void map(Object key, Text value, Context context) {
Text phoneNumber = new Text(); //key
IntWritable duration = new Interatable(); // value
StringTokenizer itr = new StringTokenizer(value.toString(), " ");
String number = itr.nextToken();
int dur = Integer.parseInt(itr.nextToken());
phoneNumber.set(number);
duration.set(dur);
context.write(phoneNumber, duration);
}
public void reduce(Text key, Iterable<IntWritable> values, Context context) {
IntWritable result = new IntWritable();
int sum = 0;
for(IntWritable duration : values){
sum += duration.get();
}
result.set(sum);
context.write(key, result);
}
















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











