







文章欢迎转载,但转载时请保留本段文字,并置于文章的顶部
作者:卢钧轶(cenalulu)
本文原文地址:http://cenalulu.github.io/linux/all-about-cpu-cache/
先来看一张本文所有概念的一个思维导图

为什么要有CPU Cache
随着工艺的提升最近几十年CPU的频率不断提升,而受制于制造工艺和成本限制,目前计算机的内存主要是DRAM并且在访问速度上没有质的突破。因此,CPU的处理速度和内存的访问速度差距越来越大,甚至可以达到上万倍。这种情况下传统的CPU通过FSB直连内存的方式显然就会因为内存访问的等待,导致计算资源大量闲置,降低CPU整体吞吐量。同时又由于内存数据访问的热点集中性,在CPU和内存之间用较为快速而成本较高的SDRAM做一层缓存,就显得性价比极高了。
为什么要有多级CPU Cache
随着科技发展,热点数据的体积越来越大,单纯的增加一级缓存大小的性价比已经很低了。因此,就慢慢出现了在一级缓存(L1 Cache)和内存之间又增加一层访问速度和成本都介于两者之间的二级缓存(L2 Cache)。下面是一段从What Every Programmer Should Know About Memory中摘录的解释:
Soon after the introduction of the cache the system got more complicated. The speed difference between the cache and the main memory increased again, to a point that another level of cache was added, bigger and slower than the first-level cache. Only increasing the size of the first-level cache was not an option for economical rea- sons.
此外,又由于程序指令和程序数据的行为和热点分布差异很大,因此L1 Cache也被划分成L1i (i for instruction)和L1d (d for data)两种专门用途的缓存。
下面一张图可以看出各级缓存之间的响应时间差距,以及内存到底有多慢!

什么是Cache Line
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes。假设我们有一个512字节的一级缓存,那么按照64B的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 = 8个。具体参见下图:

为了更好的了解Cache Line,我们还可以在自己的电脑上做下面这个有趣的实验。
下面这段C代码,会从命令行接收一个参数作为数组的大小创建一个数量为N的int数组。并依次循环的从这个数组中进行数组内容访问,循环10亿次。最终输出数组总大小和对应总执行时间。
#include "stdio.h"
#include <stdlib.h>
#include <sys/time.h>
long timediff(clock_t t1, clock_t t2) {
long elapsed;
elapsed = ((double)t2 - t1) / CLOCKS_PER_SEC * 1000;
return elapsed;
}
int main(int argc, char *argv[])
#*******
{
int array_size=atoi(argv[1]);
int repeat_times = 1000000000;
long array[array_size];
for(int i=0; i<array_size; i++){
array[i] = 0;
}
int j=0;
int k=0;
int c=0;
clock_t start=clock();
while(j++<repeat_times){
if(k==array_size){
k=0;
}
c = array[k++];
}
clock_t end =clock();
printf("%lu\n", timediff(start,end));
return 0;
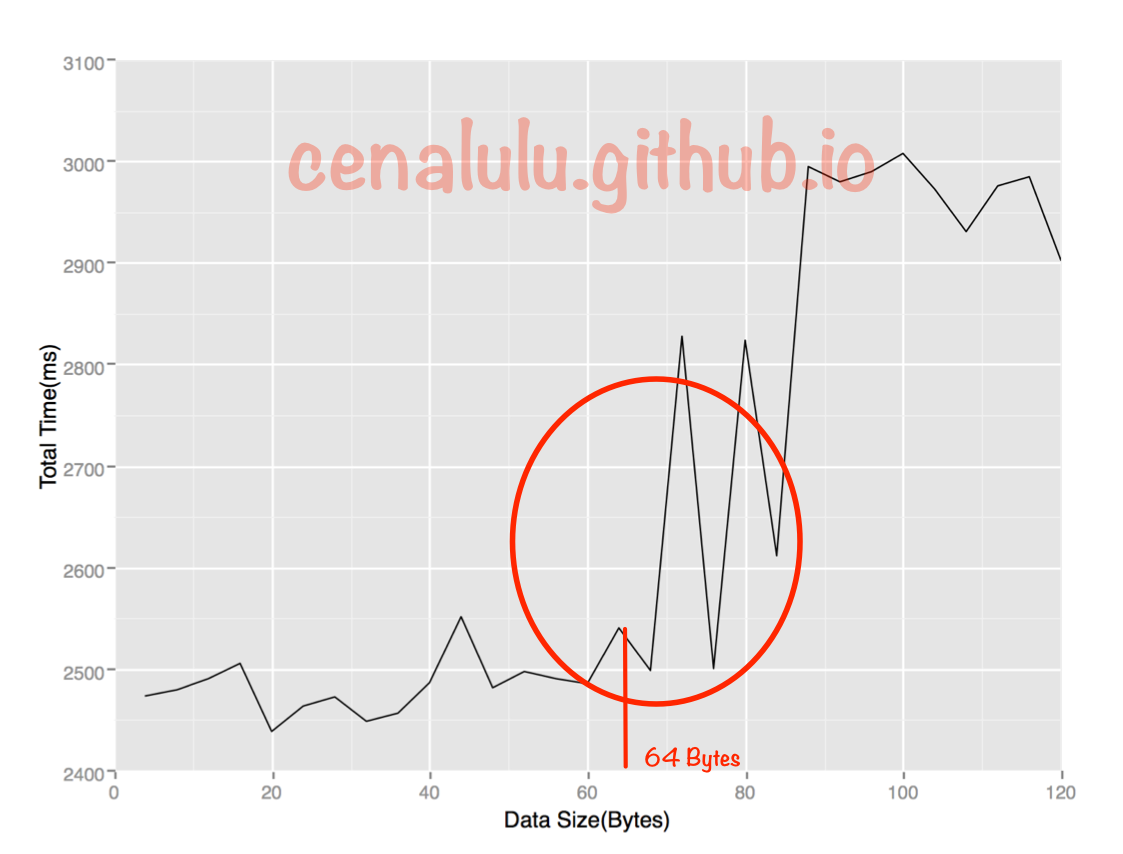
}如果我们把这些数据做成折线图后就会发现:总执行时间在数组大小超过64Bytes时有较为明显的拐点(当然,由于博主是在自己的Mac笔记本上测试的,会受到很多其他程序的干扰,因此会有波动)。原因是当数组小于64Bytes时数组极有可能落在一条Cache Line内,而一个元素的访问就会使得整条Cache Line被填充,因而值得后面的若干个元素受益于缓存带来的加速。而当数组大于64Bytes时,必然至少需要两条Cache Line,继而在循环访问时会出现两次Cache Line的填充,由于缓存填充的时间远高于数据访问的响应时间,因此多一次缓存填充对于总执行的影响会被放大,最终得到下图的结果
了解Cache Line的概念对我们程序猿有什么帮助?
我们来看下面这个C语言中常用的循环优化例子
下面两段代码中,第一段代码在C语言中总是比第二段代码的执行速度要快。具体的原因相信你仔细阅读了Cache Line的介绍后就很容易理解了。
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
int num;
//code
arr[i][j] = num;
}
}for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
int num;
//code
arr[j][i] = num;
}
}














 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









