






检测模型 = 特征提取器+检测头
一、yolov2
1、基本概念
yolov1的检测速度快,但是预测框不准确,很多目标找不到
- 预测的框不准确
- 目标找不到
问题 1:预测的框不准确
yolov1直接预测的是目标框的坐标(x,y,w,h),yolov2改进预测的是目标框的偏移量。直接预测位置会导致神经网络在一开始训练时不稳定,使用偏移量会使得训练过程过程更加稳定,性能指标提升。
- 偏移量:
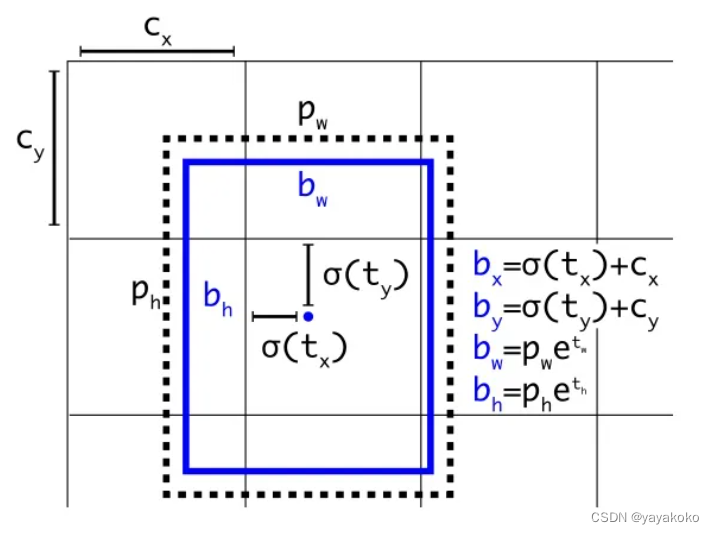
模型预测的值为:tx、ty、tw、th
模型最终的检测结果为:bx、by、bw、bh
cx、cy为grid左上角坐标,pw、ph为Anchor的宽高。
问题 2:很多目标找不到
将yolov1的 7 x 7 改为 13 x 13 区域,而且每个区域有5个Anchor(锚框),而且每个锚框对应一个类别。
1、为什么用Anchor
2、每个区域的5个Anchor是如何得到的呢
对训练集中的GT bounding box进行聚类,根据实验发现聚5类较合理。
anchor是从数据集中统计获得的,Faster-RCNN中的Anchor的宽高和大小是手动挑选的。
2、yolov2的网络结构
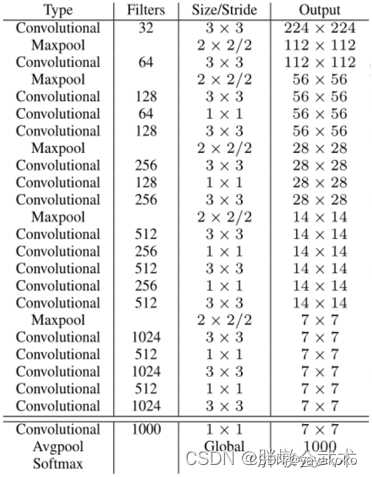
2. 1 网络模型(Darknet-19)
采用19个卷积层,5个池化层
2. 2 相对于yolov1的改进
(1)加入BN
解决梯度消失和爆炸,起到一定的正则化效果
(2)使用高分别率图像,微调分类模型
yolov1:训练使用224x224,测试:448x448
yolov2:保持v1不变,但是在原训练的基础上加上(10个epoch)的448x448高分别率样本进行微调,测试用448x448。
(3)聚类使用先验框
yolov2对训练集中所有标注的边界框进行聚类(5类),将每一类的中心中心实际值(w,h)作为先验Anchor
(4)相对偏移计算

(5)细粒度特性——提高对小目标的检测能力
对不同层的特征进行融合,高分别率的浅层进行拆分叠加到低分辨率的深层特征
(6)多尺度检测
每经过一定次数的迭代,可以进行输入图像尺度变化。
















 3367
3367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









