






第一次发布博客,主要记录我在学习视觉SLAM十四讲一书的理解和感悟。
第一章:初始SLAM。
这一章中的主要知识点有:(1)经典视觉SLAM框架;(2)SLAM问题的数学表述
(1)经典视觉SLAM框架
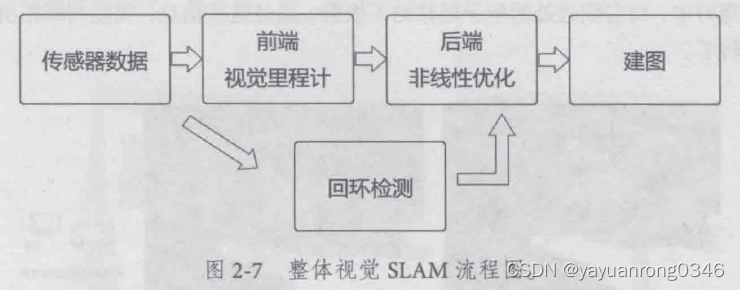 摘抄自《视觉SLAM十四讲 从理论到实践》
摘抄自《视觉SLAM十四讲 从理论到实践》
问题1:经典的视觉SLAM框架包括哪些部分? 各部分的作用是什么?
经典的视觉SLAM框架包括(a)传感器数据、(b)视觉里程计(前端)、(c)非线性优化(后端)、(d)回环检测、(e)建图五个部分。
各部分的作用是:(a)传感器数据采集周围环境的图像信息,并进行基础的图像预处理。(b)视觉里程计也被称作前端,主要功能在于相机位姿估计和建图。首先利用相邻帧图像中相同特征在像素坐标中分布位置的差异来估计相机的位姿(平移和旋转),然后基于估计的自身位姿和周围物体的图像,建立周围环境地图。如果相机对周围物理环境的成像过程完全真实,也就是不考虑误差的情况下,只需要通过视觉里程计即可建立真实的智能体运行轨迹以及周围环境的地图,但是实际情况下,相机的成像不可避免会受到干扰存在误差,因此仅使用视觉里程计来记录智能体运行轨迹以及周围环境的地图时会存在累计误差,导致运行轨迹建模与周围环境地图建立存在较大的累计误差。(c)非线性优化也称作后端,后端接收前段传递过来的相机位置信息,并通过回环检测提供的重合点位置信息,纠正估计得到的整个轨迹和地图。(d)回环检测则不断检测当前采集的图像和以往的图像是否相同,从而确定有没有经过相同地点,将相同地点信息传递给后端,让后端消除(减小)累计误差。
(2)SLAM问题的数学表述
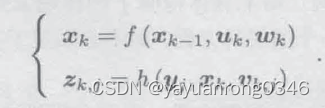
摘抄自《视觉SLAM十四讲 从理论到实践》
问题2:SLAM问题数学表示是如何实施的?
SLAM问题数学表示由运动方程和观测方程组成。其中运动方程的输入为k-1时刻相机的位姿,相机拍摄的图像(也就是运动传感器的参数uk),噪声wk。有了相机在k-1时刻的位姿,加上k时刻拍摄的图像uk和噪声wk,可以计算出k时刻相机的位姿。由于噪声wk是未知的,因此求xk的过程被称作估计。观测方程的输入为相机k时刻的位姿xk,第j个路标的真实位置yj,以及拍摄过程中的噪声,输出为zk,j,zk,j也是图像数据,希望根据相机k时刻的位姿xk,拍摄到的图像zk,j,确定路标yj的位置。















 150
150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









