







Arm的新款Cortex-M55的独特之处
半导体行业观察 ·2020-06-21 12:13·半导体行业观察
阅读:2733
来源:内容翻译自 wikichip ,谢谢。
机器学习的工作量范围之广令人难以置信。用于执行这些工作负载的硬件越来越多,这也加剧了这场革命。除了传统的DSP以及最近的专用加速器之外,越来越多的客户正在使用CPU来处理ML。在嵌入式和微控制器领域,这些CPU通常是Arm Cortex-M系列。
即使将Cortex-M内核用于机器学习,现有的内核也不是特别擅长。除此之外,它们仍然基于较旧的ARMv7-M体系结构。当Arm 在 今年早些时候 推出Cortex-M55 时,大部分情况发生了变化。M55有点不寻常,因为尽管它打算取代Cortex-M4和M7,但它并不能直接替代两者。它确实提供了足够的新功能和增强功能,以吸引有兴趣将其Cortex M用于机器学习应用程序的芯片设计。要了解为什么会这样,我们必须更深入地研究新的Cortex-M55架构。
Arm已经有了一个称为Neon的向量扩展名,该扩展名已在所有最新的Cortex-A内核中广泛使用。该扩展的主要问题是功率和面积要求。Neon还需要一个更大的寄存器文件,这反过来又会影响微体系结构的其他机制,例如短中断延迟。这些是称为Helium(MVE)的新矢量扩展的主要动机。
Helium 是针对Cortex-M系列处理器设计的全新SIMD指令集扩展。该扩展程序提供了150多个新指令,其中130多个是矢量指令。 Helium 具有8个向量寄存器,每个向量寄存器均为128位宽。为了最大限度地利用区域,八个向量寄存器中的每一个都直接映射到四个FPU寄存器上。该扩展提供整数和浮点支持,提供8位,16位和32位整数运算以及半精度,单精度和双精度浮点运算。8位整数和半精度浮点数据类型对于Cortex-M领域都是新的。还需要指出的是, Helium 指令集分别针对整数和浮点指令提供了两种MVE-I和MVE-F。

在较高水平上, Cortex-M55 是符合ARMv8.1-M的内核,具有4级有序标量流水线。除了新的Helium ISA支持之外,该内核还引入了新的协处理器接口,并且是第一个提供自定义Arm指令支持的内核,尽管这种支持要到2021年才能实现。从Cortes-M4和M7都可以使用,但都不能完全替代。更长的流水线使M55的频率比M4高出大约15%,但与M7的能力相比却差强人意(具有两个附加级)。从技术上讲,M55能够解码两个相邻的16位T16指令,但是其余的流水线是单个问题,因此Arm并未将设计归类为超标量。相比之下,Cortex-M7是双重问题设计。Arm报告提供4.2的核心 CoreMark / MHz 将使它比M4高出约25%,但比M7低约20%。
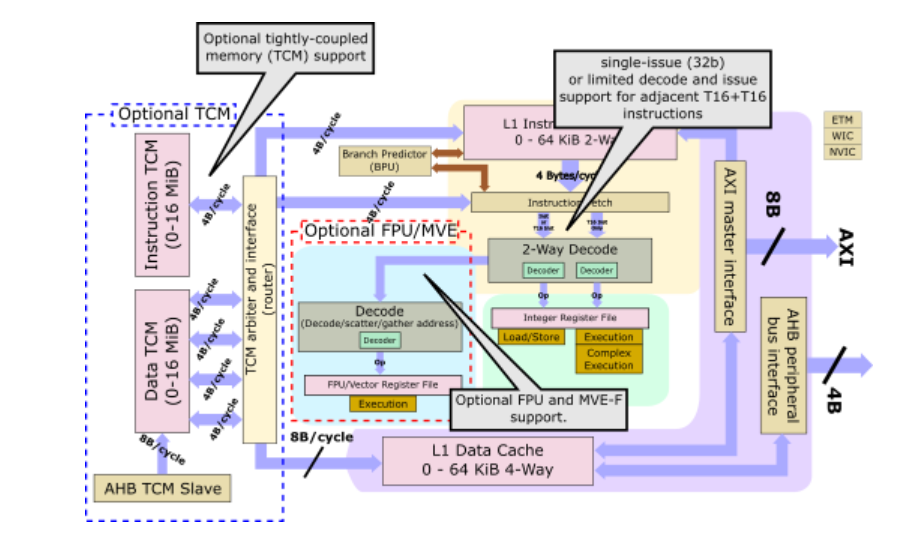
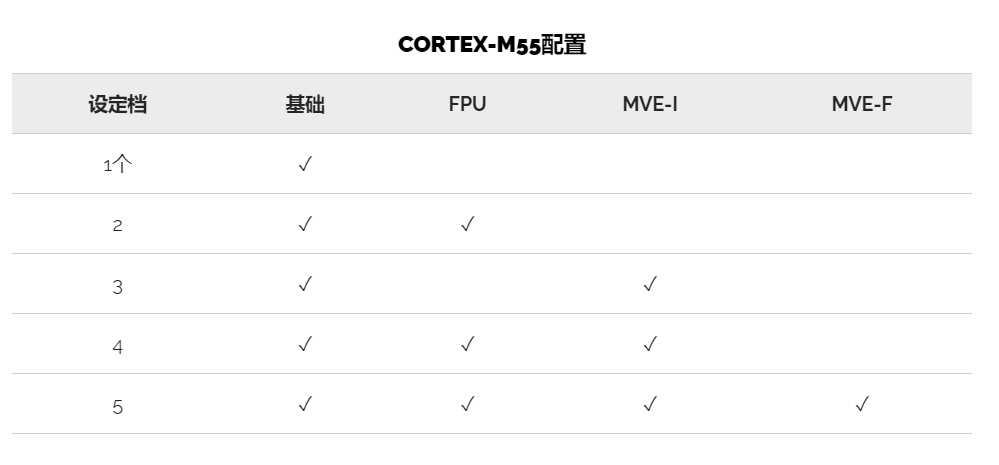
M55是一个完全可配置的内核。配置超出了缓存大小,并包括FPU和Helium扩展支持。由于Helium仅允许使用整数矢量指令或整数和浮点数,因此M55提供了两种选择作为配置。总共有六种主要的主要配置-基本整数管道,整数和FPU支持,以及用于整数,浮点数或两者的Helium的三种附加配置。没有Helium支持,M55最终只能提供成为ARMv8内核的优势。
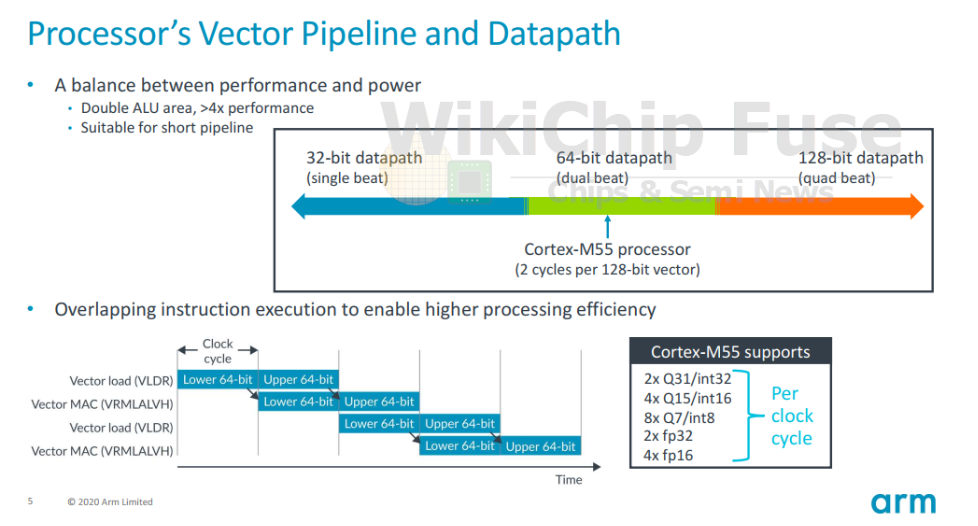
Helium定义了128位宽的操作,但它也定义了在设计人员需要平衡矢量支持与面积和功耗之间的权衡时,如何在32位,64位和128位数据路径系统上执行它们。在内部,M55具有带64位ALU和匹配的64位加载/存储操作的64位数据路径。相对于Helium,这意味着M55是双拍频系统。
在M55之类的双拍系统中,每个周期执行两次拍。Helium中的特殊架构规则允许双拍子系统重叠拍子。M55的双重问题执行功能充分利用了该功能。程序员可以这样做的是将128位向量加载操作与另一个128位向量操作(例如下面的幻灯片中的MAC)重叠。这在各种与DSP相关的算法(例如过滤)中很常见。当这样的指令交织时,M55能够加载64位值,同时以相同的时钟周期对先前加载的64位值执行MAC操作,从而分别维持64位加载和64位MAC周期。
Cortex-M55具有64位ALU。就原始MAC性能而言,Cortex-M55可以每周期执行2×32位,4×16位或8×8位MAC。在100 MHz下,您要在400 MHz下查看0.8 MOPS(Int8)或3.2 MOPS(Int8)。
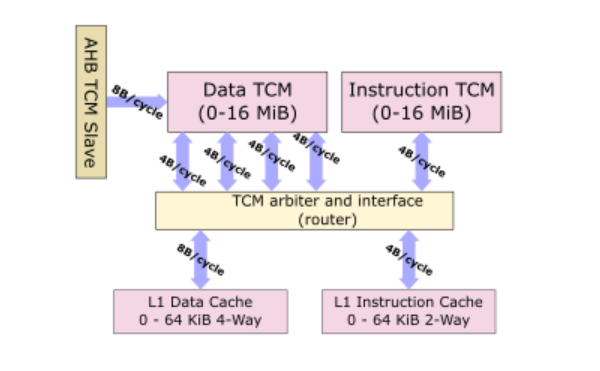
内存子系统是Cortex-M55的一个从Cortex-M7大量借用的区域。与M7一样,新的M55具有两级存储系统。它具有1级通用紫色高速缓存以及紧密耦合的内存块,用于实时低延迟应用程序。有一个可选的专用L1数据高速缓存和指令高速缓存。两种缓存的配置范围均为0到64 KiB。此外,Cortex-M55可以配置有指令TCM和数据TCM,并且两者都可以配置为几乎所需的任何实际大小,最大为16 MiB(两者合计为32 MiB)。
与Cortex-M7相比,由于Cortex-M55仅能维持4B /周期的指令提取,因此与I-TCM的接口已减半为32位。同样,Cortex-M7具有2个D-TCM的32位接口,而Cortex-M55将其倍增至64位以适应新的64位操作。值得指出的是,在实践中,M55内核每个周期只能生成64位数据流量,因此其他64位链接确实在那里支持DMA操作的功能,该功能独立于/从TCM传输数据到TCM 。换句话说,通过四个32位接口,Cortex-M55可以同时处理由于指令执行和基于DMA的64位数据传输而导致的64位数据传输。
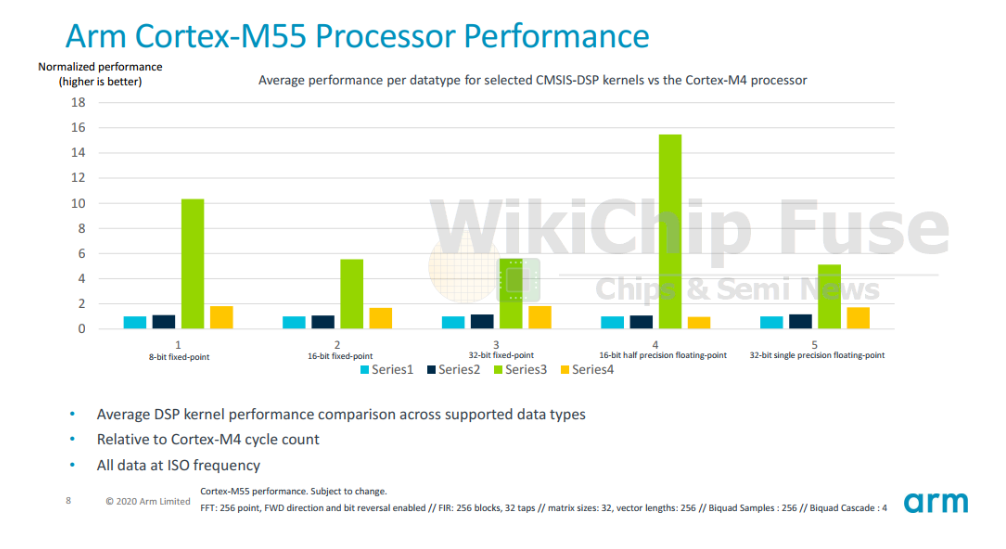
那么,这一切能为您带来什么呢?对于DSP和机器学习类型的工作负载,流行算法的时钟周期大约减少了5倍。下图将Cortex-M55与M4,M33和M7进行了比较,并将性能归一化为M4(今天仍然非常流行)。该性能适用于CMSIS的DSP库集合,其中包含各种内核,例如FIR,FFT,双二阶滤波器和跨各种数据类型的矩阵乘法。性能提升非常显着。关于此比较,需要注意的一件事是float16和int-8的高性能得到了惊人的提高(分别约为16x和11x)。这是在Cortex-M系列上引入了两种新数据类型的结果。以前,这两种数据类型本机不存在。
*免责声明:本文由作者原创。文章内容系作者个人观点,半导体行业观察转载仅为了传达一种不同的观点,不代表半导体行业观察对该观点赞同或支持,如果有任何异议,欢迎联系半导体行业观察。

















 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









