







在上一章节中讨论了为什么深度神经网络网络会很难训练。这一节就谈谈是如何克服那些困难的,开始正式讨论深度学习(Deep Learning)。
希望通过这样一步一步地介绍能够对深度学习有一个比较清楚的脉络。
卷积网络的介绍-Introducing convolutional networks
正是因为前面介绍深度神经网络训练起来会有各种问题,所以针对图像领域,提出了一个卷积神经网络。卷积神经网络(Convolutional neural networks )使用了三个基本的策略:局部接受区域(local receptive fields)、共享权重(shared weights)和池化(pooling)。
下面来逐一介绍这三部分。
local receptive fields
在前面介绍的神经网络中,神经元是 fully-connected,每一像素对应一个输入神经元。在CNN中却不是这样的。首先为了方便描述,将输入想象成是一个28x28的神经元方阵,每一个神经元对应图像的一个像素。如下图所示:

同样,要将输入层的神经元和隐藏层的神经元连接起来,但是不像之前那样把每一个像素都连接到隐藏层的每一个神经元(fully-connected),而是把输入图像的一个小区域连在一起共同连接到一个神经元。
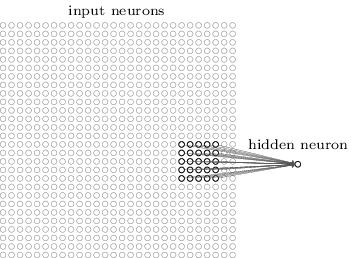
用图来说明,隐藏层的每一个神经元将会和输入神经元的一个小区域相连,比如5x5的小区域就对应25个像素。输入图像的这样一个区域就叫是隐藏层神经元的局部接收域(local receptive field),每一个这样的连接就要学习一个权重,当然隐藏层的神经元也要学习偏置。可以想象到,每一个隐藏层的神经元只学习一个局部的输入信息。


这样,逐像素滑动local receptive field的窗口,每一个窗口下的local receptive field都对应一个隐藏层的神经元,这样就将所有的像素和隐藏层的神经元连接起来了。
如上所示,建立了第一个隐藏层。注意如果输入图像是28x28,5x5的局部接收域,那么第一个隐藏层会有24x24个神经元。
前面的local receptive field的窗口大小是5x5的,并且是逐像素移动的。有时候可以使用不同的步长,比如一次移动2个像素。
Shared weights and biases
前面说了每一个隐藏层的神经元和对应的Shared weights and biases都有一个偏置和5x5权重,事实上对24x24的神经元来说,每一个神经元都是用的相同的偏置和权重。换句话说,对第
j
层的第
k
个神经元,输出为:
上式中 wl,m 是一个5x5的共享权重, b 是一个共享的偏置,
这一点是很重要的!因为这样的话,同样一个特征,不管出现在图像的哪个位置,都能够重复地检测出来并成功学习!
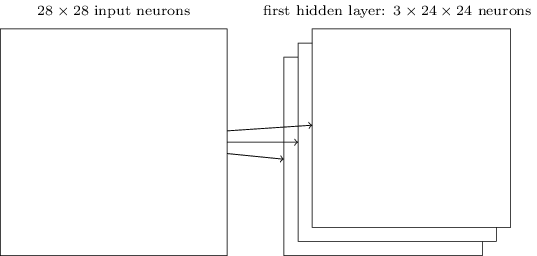
前面的网络结构的第一层隐藏层只能学习一个特征,通常需要学习多个特征,那么就需要有多个不同的核,如上所示,有3个核,就可以学习到三个特征。
共享权重和偏置的一个好处是极大地减少了卷积网络中要学习的参数。
池化层-Pooling layers
池化层通常跟在卷积层之后,池化层是为了简化卷积层的输出的信息。
例如,池化层的每一个神经元要总结卷积层的一个小区域(比如2x2)的信息。比如很常用的max-pooling,是将卷积层的小区域(2x2)中最大一个保留下来。如下所示:

这样的话,对一个24x24的卷积层,池化层就有12x12个神经元。
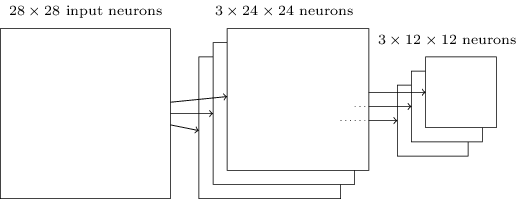
如前所述,通常会有多个卷积层,对每一个卷积层单独使用max-pooling,所以如果有三个卷积层,将会有三个池化层。
除了max-pooling,还有L2 pooling,即取元素的平方和的平方根。
构造卷积神经网络
把上面所述的结构整合在一起,就可以构造一个简单的卷积神经网络了:
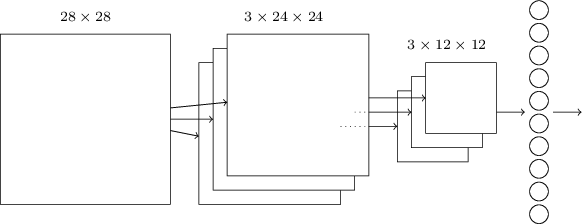
输出层代表每一种可能的输出(0-9),最后一层是全连接的( fully-connected ),输出层的每一个神经元和最后一个池化层的每一个神经元都连接起来。
这样的一个卷积神经网络和之前的网络有相似的地方,当然也有不同的地方,所以在前面使用的反向传播的算法中,需要做一定的修改。















 6953
6953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









