







Logistics Classification
Softmax function:
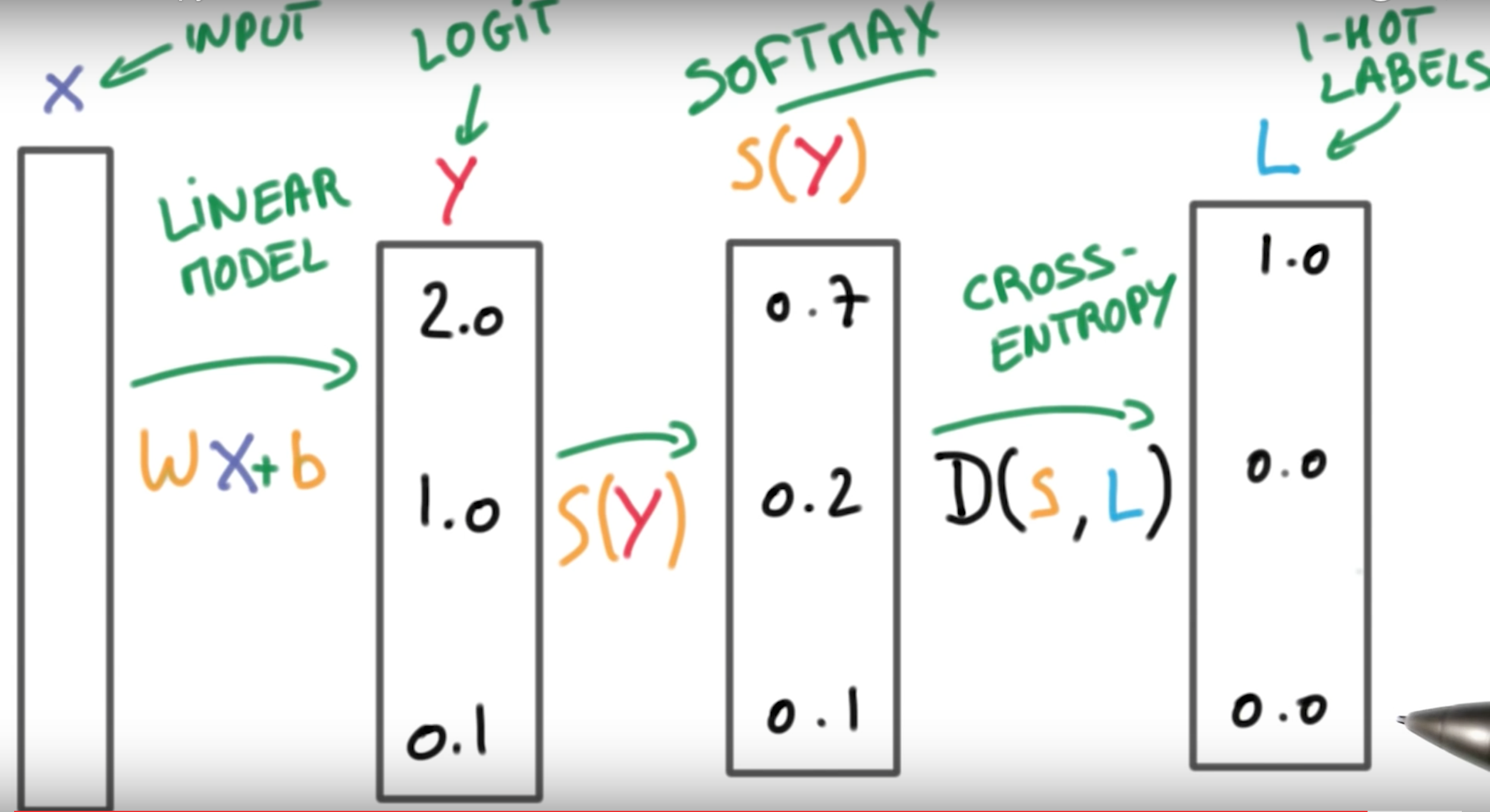
We have a linear function:
WX+b=y
where X is the input data and y is the score, our goal is to use machine learning to train the W and b to make the score very high for the correct label. The softmax function takes the scores and turns them into the proper probabilities. The higher probabilities correspond to the higher scores, of course the right label.
s(yi)=eyi∑jeyj
If you multiply the scores by 10, then the probabilities either go very close to 1 or go down very close to 0. Otherwise, if you divide the scores by 10, the probabilities turns out to be very close to each other and look like to be derived from the uniform distribution.
In another word, if you increase the size of your outputs, then the classifier becomes very confident about its predictions, while if you reduce the size of your outputs, your classifier becomes very insure. We want our classifier to be not so sure at the beginning. Overtime, it will gain confidence as it learns.- The codes are from the Udacity:
"""Softmax."""
scores = [3.0, 1.0, 0.2]
import numpy as np
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
prob_sum = np.exp(x).sum(axis=0)
return np.exp(x)/prob_sum
print(softmax(scores))
# Plot softmax curves
import matplotlib.pyplot as plt
x = np.arange(-2.0, 6.0, 0.1)
scores = np.vstack([x, np.ones_like(x), 0.2 * np.ones_like(x)])
plt.plot(x, softmax(scores).T, linewidth=2)
plt.show()Ways to label:
One-hot encoding:
e.g. [a, b, c] -> [1, 0, 0]Disadvantages When it comes to super large labels sets, say if you have 10,000 labels, then you’ll get large matrix which is super inefficient.
Advantages Easy to compare to our outputs by comparing two vectors.
- Ways to compare two vectors:
Cross Entropy:
D(S,L)=−∑Lilog(Si) where S is the output of the softmax function and L is the label
The cross entropy is not symmetric!! The entire steps: Multinomial Logistics Classification
D(S(WX+b),L)
Input Data X —> Logits Y –> Softmax Scores for each y_i –> Cross-Entropy Results Labels
Minimize cross-entropy:
Training Loss Function is the
Loss Function : loss(W,b)=1N∑iD(S(WXi+b),Li)Gradient Descent:
Step Chosen
step=−αΔL(w1,w2)
Above step is just calculated from two weights, but a typical Loss function might have thousands of weights.
Disadvantages
Adding small values to super big numbers can result in a lot of errors, e.g:a = 1000000000 b = 0.000001 for i in range(1000000): a += b print a-1000000000The result value is not 1.0 though. A good way to solve it is always to make the training variables(data) have zero mean and equal variances.
Weight Initialization
Use small σ to begin with, so that you’ll have an uncertain classifier. As time goes by, the classifier will gain confidence.
Then:
W=W−αΔWL
b=b−αΔbL
Loops .. until we reach the minimum of the loss function.
- Ways to compare two vectors:
TO BE CONTINUED. Thank You.















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









