









YOLOv8bug调试记录以及配置文件
Bug调试
1.UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\u03aa’ in position 3: illegal multibyte sequence
解决方式:
点到项目路径下的 yolo/utils/–init–.py下,找到第279行代码:
# Dump data to file in YAML format
with open(file, 'w',) as f:
yaml.safe_dump(data, f, sort_keys=False, allow_unicode=True)
将其改为:
# Dump data to file in YAML format
with open(file, 'w', encoding="gbk", errors='ignore') as f:
yaml.safe_dump(data, f, sort_keys=False, allow_unicode=True)
配置改动
1.模型权重的保存路径修改
解决方式:
ultralytics/yolo/engine/trainer.py下的92行:
# Dirs
project = self.args.project or Path(SETTINGS['runs_dir']) / self.args.task
# project = "D:\\Ultralytics\\runs\\segment"
name = self.args.name or f'{self.args.mode}'
将其改为:
# Dirs
# project = self.args.project or Path(SETTINGS['runs_dir']) / self.args.task
project = "D:\\Ultralytics\\runs\\segment"
name = self.args.name or f'{self.args.mode}'
就可以自己指定训练完后的模型权重保存路径了
2.自定义数据集路径的更改
用过v8的同学应该知道,由于v8底层代码的路径用的是项目的相对路径下的dataset,所以我们在放我们的数据集时,规定必须要放在这个路径下,我们确定数据集的函数为check_det_dataset(),该函数的路径在/ultralytics/yolo/data/utils.py。这里,我们会发现函数里面常出现一个参数:DATASET_DIR,当我们点进去看的时候会看到,作者已经将dataset的路径设置好了。那么当我们想自己决定数据集的位置时,我们只需要这样改动即可,首先给函数增加一个变量,即指定我们的数据集路径,然后将函数中的数据集的路径改成我们给定的这个参数的路径:
def check_det_dataset(dataset, data_path, autodownload=True):
"""Download, check and/or unzip dataset if not found locally."""
data = check_file(dataset)
# Download (optional)
extract_dir = ''
if isinstance(data, (str, Path)) and (zipfile.is_zipfile(data) or is_tarfile(data)):
new_dir = safe_download(data, dir=DATASETS_DIR, unzip=True, delete=False, curl=False)
data = next((DATASETS_DIR / new_dir).rglob('*.yaml'))
extract_dir, autodownload = data.parent, False
# Read yaml (optional)
if isinstance(data, (str, Path)):
data = yaml_load(data, append_filename=True) # dictionary
# Checks
for k in 'train', 'val':
if k not in data:
raise SyntaxError(
emojis(f"{dataset} '{k}:' key missing ❌.\n'train' and 'val' are required in all data YAMLs."))
if 'names' not in data and 'nc' not in data:
raise SyntaxError(emojis(f"{dataset} key missing ❌.\n either 'names' or 'nc' are required in all data YAMLs."))
if 'names' in data and 'nc' in data and len(data['names']) != data['nc']:
raise SyntaxError(emojis(f"{dataset} 'names' length {len(data['names'])} and 'nc: {data['nc']}' must match."))
if 'names' not in data:
data['names'] = [f'class_{i}' for i in range(data['nc'])]
else:
data['nc'] = len(data['names'])
data['names'] = check_class_names(data['names'])
# Resolve paths
path = Path(extract_dir or data.get('path') or Path(data.get('yaml_file', '')).parent) # dataset root
if not path.is_absolute():
path = (data_path / path).resolve()
data['path'] = path # download scripts
for k in 'train', 'val', 'test':
if data.get(k): # prepend path
if isinstance(data[k], str):
x = (path / data[k]).resolve()
if not x.exists() and data[k].startswith('../'):
x = (path / data[k][3:]).resolve()
data[k] = str(x)
else:
data[k] = [str((path / x).resolve()) for x in data[k]]
这里防止大家找不到,我将我改动的地方贴出来:
if not path.is_absolute():
path = (data_path / path).resolve()
这里的path路径本来是:DATASET_DIR/path
3.预测的结果保存
以检测为例子,找到\ultralytics\yolo\engine\predictor.py路径下的py文件,将get_save_dir()方法下的project变量改成自己想设置成的路径即可,就可以避免v8内部的默认路径配置了,这是一个大坑,因为我发现当我的电脑中拥有多个v8的项目时,尽管我在配置文件中设置好了路径,但是依旧会读写进意料之外的文件夹,就是因为在同一台电脑中,当我们运行了第一个v8项目之后,c盘下面就会生成一个默认的配置文件,导致你的第2个,第3个v8都是依照这个路径运行,这就很头疼:
def get_save_dir(self):
# project = self.args.project or Path(SETTINGS['runs_dir']) / self.args.task
project = f"E:\\MaxWell\\1MaxWell_algorithm\\7.yolov8实例分割-nncf量化\\Ultralytics\\runs\\{self.args.task}"
name = self.args.name or f'{self.args.mode}'
return increment_path(Path(project) / name, exist_ok=self.args.exist_ok)
这里我改成了我想要的项目路径。
当我训练完一个模型了,此时我想查看以下他的推理效果时,就可以运行predict.py这个demo,在ultralytics/yolo/cfg/default.yaml这个配置文件中,我们可以定义想要检测的源,输入0时,源就是我们的电脑摄像头,实现视频流的检测,当输入图片的文件夹路径时,源便是问价夹中的所有图片。source下面的show则是在我们运行predict时,是否实时展示结果的参数,默认设置为false:
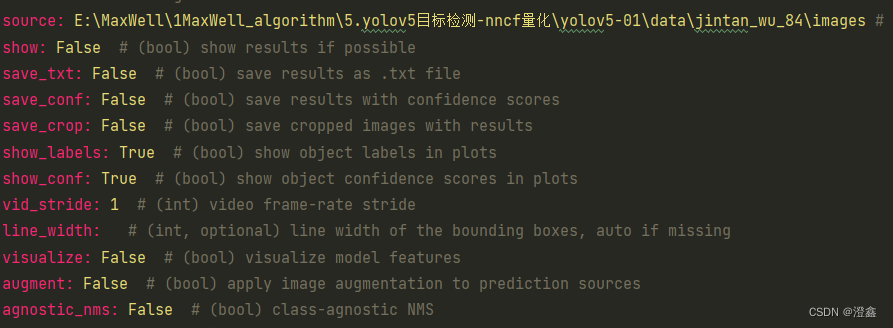
并且当我们进行目标检测的预测时,最好将最上面的task和mode参数也改成相应的需求,这样在我们去runs里面查看我们的训练结果和推理结果或者验证结果时能更加方便的找到:

4.验证配置的改动
验证环节可以直接将标注信息显示在数据集上的图片输出,和我们模型推理后的结果显示在数据集上输出,能够看到pr曲线,混淆矩阵等。验证环节已经和训练环节串行了,在代码中,当我们训练完一个模型,保存完权重之后,最后一步便是模型验证了。当我们想独立验证时,可以直接运行val.py文件,同样的,把路径改成了我想要的路径:

但是当我直接运行val.py时,却一直报self.args.xx没有这个distribute,然后令我很不解的是,明明配置文件default中有这些超参数,但是它还是显示找不到,后来我才发现,原来在validator.py中self.args的写法是这样的:
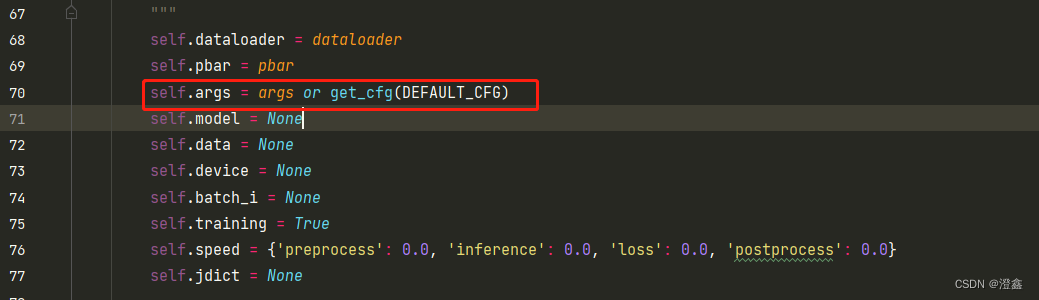
这里的args,应该就是在我们训练时,传入这个验证函数的超参数设置。按道理说这里是or,直接运行的话应该是可以读入后面的这个get_cfg()的。我尝试把args删除之后,发现这样直接运行val.py真的可以了,带来的问题就是在每次训练之后,验证环节会报错哈哈,不过无所谓了,2选一吧,反正都可以验证我们的模型。

对了,这里要注意的是 如果你需要单独验证你的模型,需要在default配置文件中,在model和data里面定义好超参数,如果是训练之后的验证,这里空着也没事,因为训练时的验证是直接读取的训练后保存的模型路径以及训练时的coco128.yaml数据配置文件的:

















 2717
2717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











