







 本文介绍了如何使用Python进行网页爬取,重点学习了如何提取CSS选择器,从文件读取内容,以及使用BeautifulSoup库解析HTML。文中提到了两种读取文件的方法,并讲解了zip函数的用法,还提供了BeautifulSoup的使用技巧,如get_text()和get()函数。
本文介绍了如何使用Python进行网页爬取,重点学习了如何提取CSS选择器,从文件读取内容,以及使用BeautifulSoup库解析HTML。文中提到了两种读取文件的方法,并讲解了zip函数的用法,还提供了BeautifulSoup的使用技巧,如get_text()和get()函数。
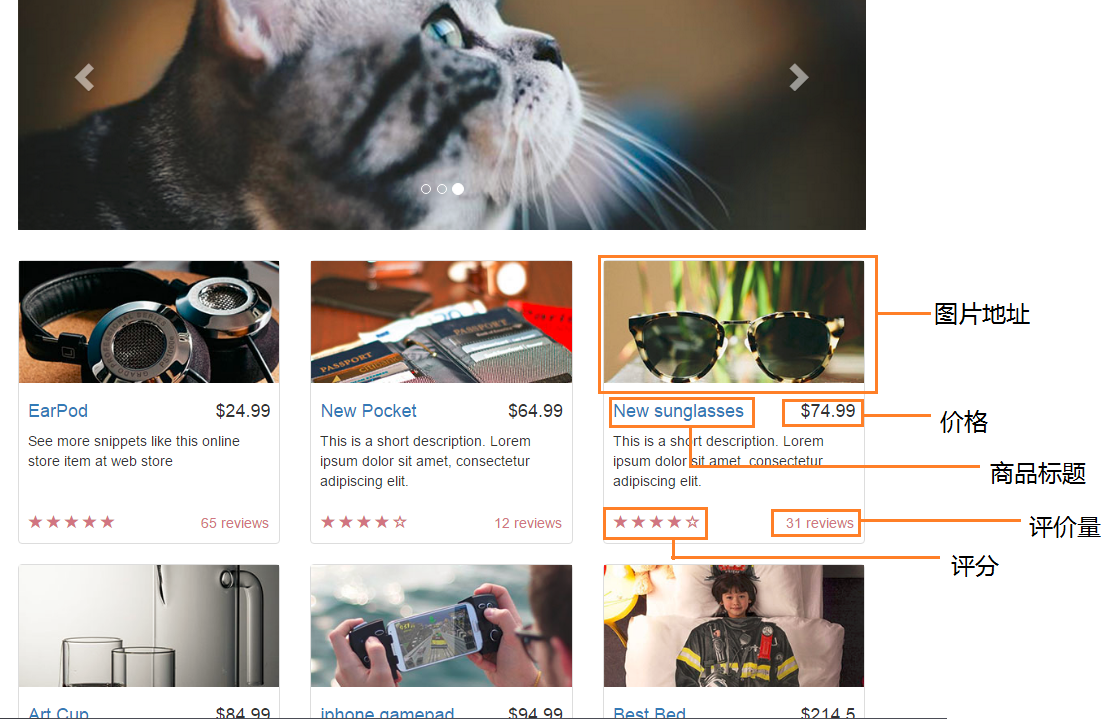
需要爬取的信息
代码
from bs4 import BeautifulSoup
import string
with open('C:/PythonPractice/Homework/Week1/1_2/1_2_homework/index.html','r') as web:
soup = BeautifulSoup(web,"lxml")
pics = soup.select('body > div > div > div.col-md-9 > div > div > div > img')
titles = soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4 > a')
prices = soup.select('body > div > div > div.col-md-9 > div > div > div > div.caption > h4.pull-right')
stars = soup.select('body > div > div > div.col-md-9 > div > div > div > div.ratings > p:nth-of-type(2) > span')
reviews = soup.select('body > div > div > div.col-md-9 > div > div > div > div.ratings > p.pull-right')
###将原先stars中的元素分成每5个为一列表,并存放在grades这个列表中
grades = [] # 设置一个空列表
while len(stars) != 0: # 循环条件长度不为0
e = stars[0:5] # 提取星星描述前五个元素,也就是一个商品的星级
grades.insert(1, e) # 把这五个商品星级的列表作为一个元素插入grades列表中
del stars[0:5] # 删除抓取到的描述列表的前五位
### 将grades列表中的各元素全部转换成 '★' or '☆'
stars_final = []
for grade in grades: #结构:[[grade11,grade12],[grade21,grade22],[grade31,grade32],[grade41,grade42]]
a = ""
for to_each_star in grade: #结构:[grade11,grade12], [grade21,grade22], [grade31,grade32]
to_each_star_string = str(to_each_star) #变成字符串
if (to_each_star_string == '<span class="glyphicon glyphicon-star"></span>'):
a = a + '★'
else:
a = a + '☆'
stars_final.append(a)
for pic, title, price, star_final, review in zip(pics,titles, prices, stars_final, reviews):
data = {
'pic':pic.get('src'),
'title':title.get_text(),
'price':price.get_text(),
'review':review.get_text(),
'star':star_final
}
print(data)
输出结果

总结
1、学习了怎么在浏览器中提取css selector 从文件读取内容的方式
- 第一种方式:
fs = open('文件地址','r')
print(fs.read())
fs.close()- 第二种方式:
with open('文件地址','r')as fs:
print(fs.read())2、关于zip的相关知识:
https://docs.python.org/2/library/functions.html#zip
3、BeautifulSoup库的使用
- html5lib是分析引擎名称,支持html.parser, html5lib, lxml
soup = BeautifulSoup(content,"html5lib")- get_text()函数得到中间文本内容
review = reviews.get_text()- get()函数得到属性文本内容
image_content = image.get("src")更多BeautifulSoup文档: https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#find-all















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









