







归档文件的再归档
1. 扫描归档文件列表,统计占用磁盘空间低于阈值的归档文件;
2. 根据归档文件大小配置参数,将统计所得归档文件分组;
3. 统计各分组归档文件涉及到的对象;
4. 将每个分组中的归档文件合并到一个归档文件;将归档文件中的有效对象数据合并到一个新的归档文件中;
5. 更新相关对象元数据信息表中的数据位置描述项;
6. 删除旧的归档文件;
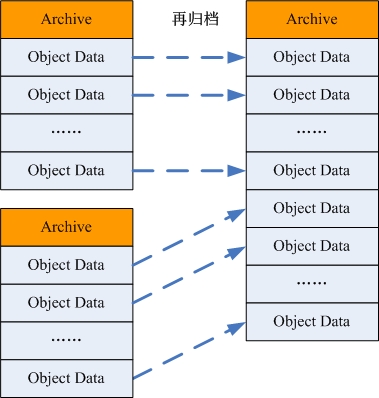
图 -8 归档文件的再归档
总结语
基于 Hadoop 实现类似 Amazon S3 的对象存储系统,有一定的先天优势,例如 Hadoop 的 HDFS 作为数据存储的容器,解决了数据冗余备份的问题; Hadoop 的半结构化的存储系统 HBase 可以支撑 MetaData 的存储,同时解决了 MetaData 存储层的可靠性和可扩展性等问题。 HDFS 天生不能适合存储大量小文件的缺陷,可以使用 MapReduce 处理架构在后台提供对象归档管理功能( Hadoop 已经有了 HAV 的功能,只是没有平台化),使得 HDFS 仍然存储自己喜欢的“大文件”。这种基于 Hadoop 实现的对象存储系统,并不能保证在现阶段达到和 Amazon S3 一样的服务效率,但随着 Hadoop 系统的不断完善(例如 HDFS 访问效率的提高, Append 功能的支持等),相信也能有不俗的表现。
来自:http://blog.csdn.net/Cloudeep/archive/2009/08/05/4412958.aspx















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









