







 本文详细介绍了NVMe子系统的组成,包括Controller的不同类型、LBArange、Namespace的管理与共享、NVMSet的作用,以及NVMe队列模型、寻址方法和数据保护策略。重点讲解了NVMe命令集、行政队列和IO队列的工作原理及实例分析。
本文详细介绍了NVMe子系统的组成,包括Controller的不同类型、LBArange、Namespace的管理与共享、NVMSet的作用,以及NVMe队列模型、寻址方法和数据保护策略。重点讲解了NVMe命令集、行政队列和IO队列的工作原理及实例分析。
1 相关概念
1.1 Controller控制器
Controller是NVM子系统和主机host之间通信的接口,有三种类型的Controller:
- I/O controller
- discovery controller
- administrative controller
Controller和主机host之间通过队列对来通信。Controller执行主机host下发到Submission Queue中的命令,执行完毕后将命令的执行结果放到Completion Queue中。所有的三种类型Controller都实现了一个Admin Submission Queue和一个Admin Completion Queue。
如果传输层使用的是PCIe协议,那么一个Controller其实就是一个PCIe Function。
I/O Controller
实现了IO Submission Queue和IO Completion Queue,允许主机访问NVM存储介质。
Discovery Controller
只在NVMeOF中使用,允许host检索Discovery Log Page,但是没有实现IO Submission Queue和IO Completion Queue,因此不提供访问NVM存储介质的能力。
Administrative Controller
1.2 LBA range
由起始逻辑块地址(start LBA)和逻辑块数量指定的一块连续的逻辑块集合。
1.3 NVM子系统
NVM子系统就是一个包含了NVM存储介质,NVMe控制器,PCIe接口的系统。
1.4 Namespace命名空间
对于一块SSD来说,它暴露出来的只有一整块的闪存空间,可以把整个闪存空间划分成若干个独立的逻辑空间暴露给主机。每个逻辑空间的逻辑块地址是 [0, N - 1] ,每个逻辑空间都有一个唯一的ID,叫做NSID,主机在读写SSD时,必须要在命令中指定NSID,表明要访问的Namespace。如下图所示,主机将NVM子系统划分成了两个Namespace。
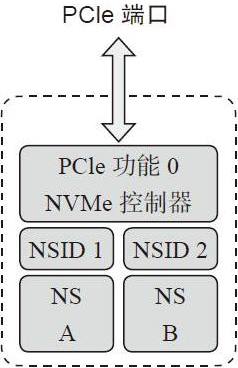
主机负责创建和维护Namespace,在创建Namespace时,主机会创建一个4KB大小的数据结构,来描述这个Namespace的相关信息。在主机端看来,一个Namespace就是一个独立的SSD,Namespace之间是相互不会影响的。每个名称空间都支持单独的格式化、擦除等操作,甚至有些驱动还支持在不同的名称空间中可以使用不同的逻辑块大小和格式。
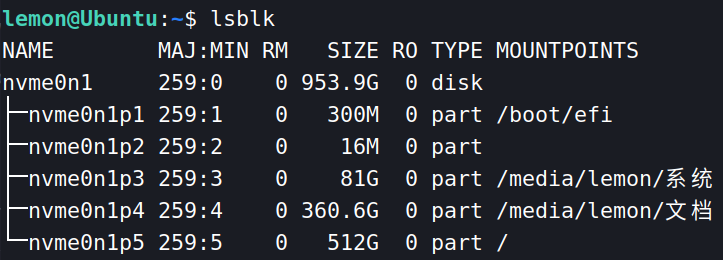
在Linux下使用 lsblk 命令查看系统下挂载的块设备信息,可能可以看到 nvme0n1 这样的设备,这就代表控制器0下的Namespace1。如下图所示:
使用命令 nvme id-ns /dev/nvme0n1 可以查看该命名空间的相关信息,如下图所示:
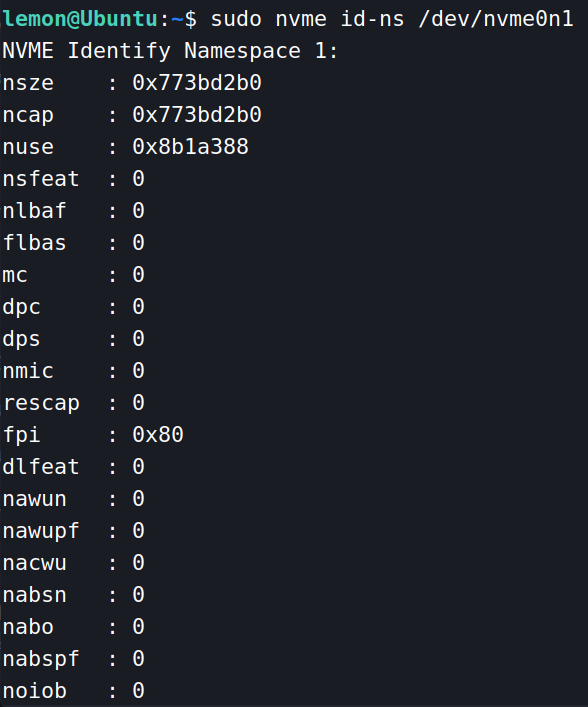
比如 nsze 表示该命名空间的大小(即所包含的逻辑块数量)。 ncap 表示同一时间可以被分配的逻辑块数量。nuse 表示已经被使用的逻辑块数量。这些信息具体表示什么意思可以在NVMe规范的5.15.2节找到。
共享命名空间
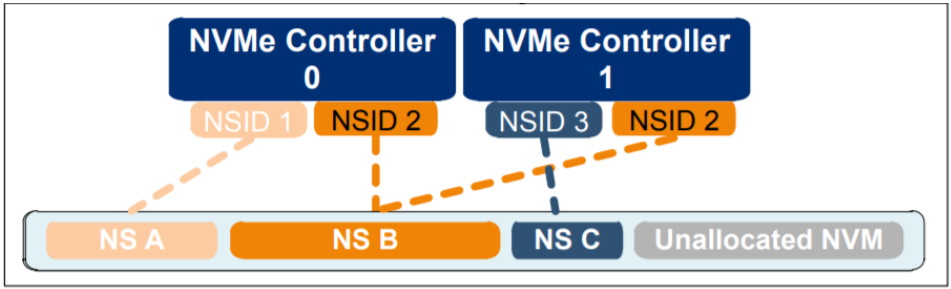
一个namespace可以专属于一个controller,也可以被多个controller所共享。比如下图,namespaceA和namespaceC分别私有于Controller 0和Controller 1的,但是namespaceB是共享的。注意:**每个命名空间都被看做是一个单独的可独立操作的设备。**多个主机可以通过不同的Controller来访问同一个共享的命名空间,注意,当并发访问共享命名空间时,主机之间需要某种机制来同步这些操作,NVMe并不规定如何同步这些并发操作。
命名空间的管理
主机可以使用两类命令集用来管理命名空间:
- Management 命令:
Create、Modify、Delete。 - Attachment 命令:
Attach、Detach。
使用 Create 命令创建完成命名空间后,此时的命名空间是不可见的,还不能对其进行读写操作,只用使用 Attach 将其关联到 Controller 后,才能正常访问该命名空间。
1.5 NVM Set
NVM set是命名空间namespace上面的一层,一个namespace只能属于一个NVM set。一个NVM set可以包含多个namespace。如下图所示:
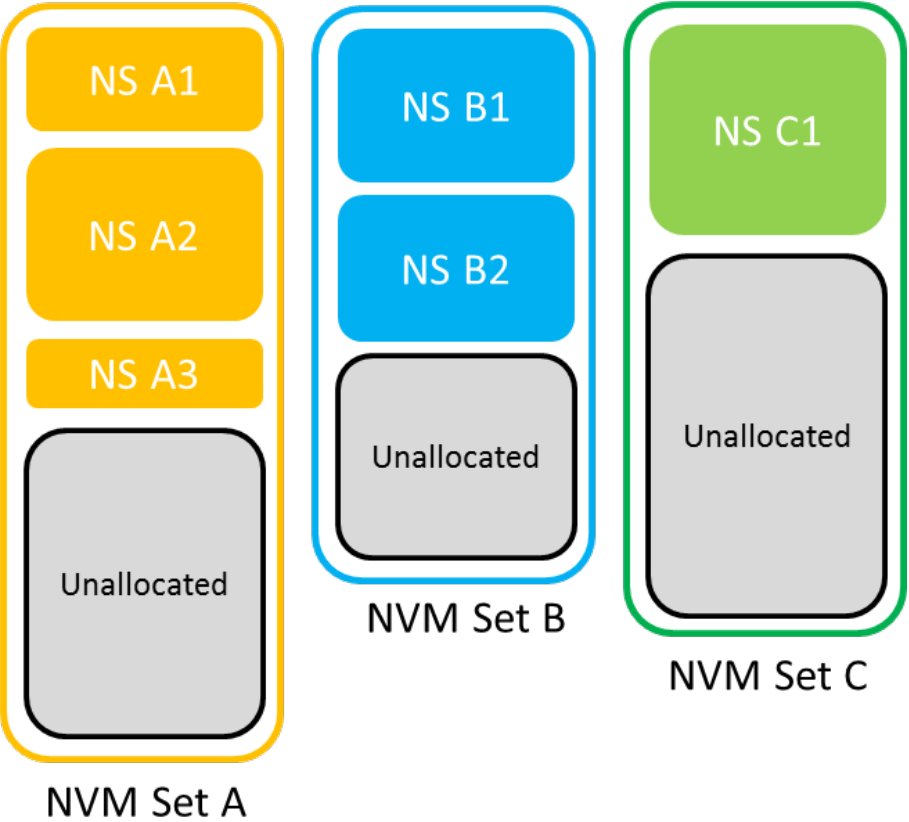
每当创建一个namespace时,需要制定其所属的NVM set,该namespace会继承NVM set的属性。每个NVM set都有一个ID,ID不能为0,是无效的ID。
2. NVMe队列机制
2.1 NVMe命令集
NVMe将命令分为Admin Command和IO Command。Admin Command用于主机管理和控制SSD,IO Command用于主机和SSD进行数据传输。
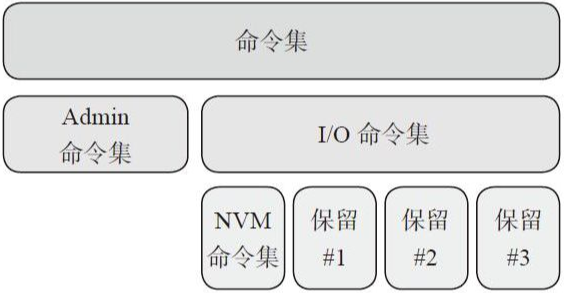
2.2 NVMe队列
Host与NVMe Controller之间利用队列来进行通信。Host将命令放到Submission Queue(简称SQ)中。NVMe Controller取出命令执行完成后,将命令执行结果放到Completion Queue(简称CQ)中。Submission Queue和Completion Queue在一起配合工作,被称为队列对。
因为NVMe的命令分为两种类型,因此会有两种类型的队列对:Admin SQ/CQ和IO SQ/CQ。
系统中只有一对Admin SQ/CQ,但IO SQ/CQ可以有最多64K对。Admin SQ和CQ是一对一的,而IO SQ和CQ可以一对一,也可以多对一。需要注意的是,这些队列都放在Host端的内存中,它们在内存中实际上就是一段环状缓冲区。
对于SQ,主机Host是生产者,Controller是消费者;对于CQ,Controller是生产者,主机Host是消费者;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YvgbMMhy-1652521953934)(C:\Users\17509\AppData\Roaming\Typora\typora-user-images\image-20220509231407017.png)]
在创建SQ之前,必选要先创建CQ,同样,在删除CQ之前,必须先删除与之相关的所有SQ。
在NVMe队列模型中,有四个寄存器比较重要,(1) Submission Queue Tail Doorbell (2) Completion Queue Head Doorbell 。
Submission Queue Head Pointer
Submission Queue Tail Doorbell
它存放的是SQ的队尾指针,位于Controller里面,每一个SQ都对应有这么一个寄存器。通过内存映射的方式可以映射到host的内存空间,这样host就可以像读写内存一样对其进行操作了。host通过更新此寄存器的值来通知controller有新的命令被提交到SQ中。
Completion Queue Head Doorbell
它存放的是CQ的队头指针,位于Controller里面,每一个CQ都对应有这么一个寄存器。也是通过内存映射的方式可以映射到host的内存空间。host通过更新此寄存器的值来表明有新的CQ被host端处理了。
Completion Queue Tail Pointer
上面这四个寄存器全部都位于Controller侧,而且对于主机Host来说只有 Submission Queue Tail Doorbell 和 Completion Queue Head Doorbell 是可见的。
Host负责写入SQ,所以它自己会维护一个SQ的队尾指针,Controller负责消费SQ,它会维护一个Submission Queue Head Pointer,来记录队头信息,但是对于Host来说Submission Queue Head Pointer是不可见的,那么Host如何知道SQ的队头?
Controller把当前的SQ的队头信息放入了CQ报文中的SQ Head Pointer字段,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rGuLJDCg-1652521953935)(C:\Users\17509\AppData\Roaming\Typora\typora-user-images\image-20220510102553580.png)]
同样的Host只负责消费CQ,所以它自己会维护一个CQ的队头指针,Controller负责生产CQ,它会维护一个Completion Queue Tail Pointer,来记录队尾信息,但是对于Host来说Completion Queue Tail Pointer是不可见的,那么Host如何知道CQ的队尾?
通过CQ报文中的P字段。(留有疑问,没看懂)
2.3 NVMe命令执行流程
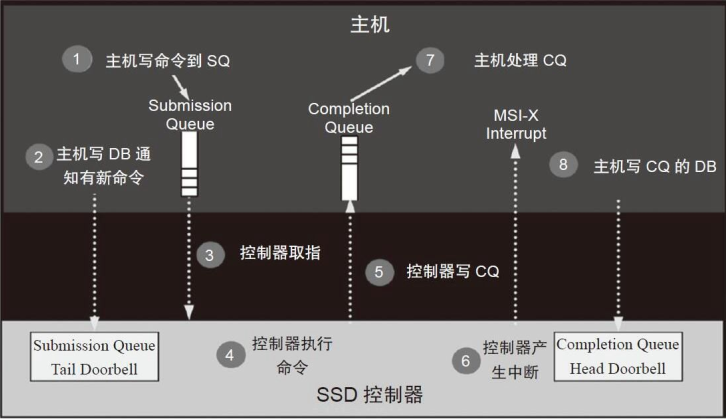
- Host提交新的Command到Host内存的SQ中。
- Host更新在Controller内部的寄存器SQ Tail Doorbell,通知控制器有新命令。
- Controller从SQ中提取Command,然后更新SQ Head Pointer寄存器中的值。
- Controller执行命令。Command的执行顺序并不是严格按照Host提交到SQ中的顺序来处理的。而且这一步Controller需要与Host进行许多次PCIe TLP包的交互(Controller从主机侧内存中取数据,或者将自己SSD中的数据放到主机侧内存中),只不过图上没有画出来。
- 命令执行完毕,Controller更新CQ Tail Pointer的值。
- 产生中断,通知Host命令处理完毕。
- Host处理CQ中的CQE。
- Host处理CQ完毕,更新Controller内部的CQ Head Doorbell。
2.4 Completion Queue Entry
Completion Queue Entry最少为16bytes,其结构如下图:

SQ Identifier
只有在多个SQ都绑定到同一个CQ时,才使用这个字段,用来标志该命令完成所对应的SQ。由于NVMeOF中,一个SQ只能对应一个CQ,所以它是保留位。
SQ Head Pointer
指示当前的SQ头指针。这只是在Controller产生一个CQE时,SQ头指针的值。
Status Field
命令的完成状态。0表示成功执行,如果执行出错,由
P
Phase Tag。用来传递CQ的队尾信息,但是没看懂咋操作的。
Command Identifier
命令的ID。指示该CQE对应于哪一条命令。SQ Identifier和Command Identifier结合在一起可以唯一的指定一条Command。
2.5 Controller Memory Buffer
位于控制器侧的内存缓冲区。控制器设置CAP寄存器的CMBS位为1表示自己支持Controller Memory Buffer。Host设置CMBMSC寄存器的CRE位为1表示自己想要使用Controller Memory Buffer。控制器设置自己的CMBLOC与CMBSZ寄存器来设置Controller Memory Buffer的一些属性。
2.4 端到端的数据保护
2.4.1 Metadata
Host与SSD之间的数据交互,除了用户数据,还有携带了一些元数据Metadata。Metadata一个最重要的角色就是传递端对端(E2E, End to End)的数据保护信息。
有两种方式来在主机和SSD之间传输Metadata。在格式化Namespace时,应该选定一种Metadata的传输方式,此后就只能用这种方式传输Metadata。
1. Metadata作为逻辑块的扩展
元数据在相关的逻辑块的末尾被传输,形成一个扩展的逻辑块。

2. Metadata作为独立的数据缓冲
Metadata作为一个单独的数据缓冲区。在这种情况下,由NVMe命令中的**Metadata Pointer (MPTR)段指定元数据的位置,而逻辑块数据用NVMe命令中的Data Pointer (DPTR)**指向。
如果使用PRP来传输逻辑块中的用户数据,那么**Metadata Pointer (MPTR)**应该指向一块连续的物理区域,并且是四字节对齐。

在NVMe协议中,多个IO Submission Queue可以映射对应一个IO Completion Queue,但是在NVMeOF中, IO Submission Queue与IO Completion Queue是一一对应的。
相比于NVMe,NVMeOF有自己的IO Queue的方式,它使用Connect command和Disconnect command来创建、销毁IO Completion Queue和IO Submission Queue。
NVMeOF不支持Completion Queue的流量控制,在发布新的命令之前,Host需要确保Completion Queue有足够的空间。
NVMeOF支持Submission Queue的流量控制,但是这个功能是可以被禁用的。
NVMeOF分层结构:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u29D9byj-1652521953937)(/media/lemon/系统/Users/17509/AppData/Roaming/Typora/typora-user-images/image-20220505111034684.png)]
2.3 NVMe寻址模型
如果host想往SSD中写入数据,数据是在host端内存中的,SSD怎么拿到这些数据?
有两种方法,第一种是直接把数据封装到命令报文中,这种方法效率太低,因为数据需要先从源内存地址拷贝一次,拷贝到SQ中,而且当数据量太大时,一条报文还放不下,数据还要拆解,到了SSD后,数据还要在组装回来。
第二种方法是在命令报文中放置要写入数据的地址,SSD解析这条命令后,直接通过DMA的方式去主机内存中拉取数据。NVMe就是使用的这种方法,具体有两种不同的实现,(1)PRP,(2)SGL。
在NVMe的命令中,用PSDT(PRP or SGL for Data Transfer)来指示此次IO交互使用的寻址模型是PRP还是SGL,PSDT具体有下面几种取值:
| 值 | 解释 |
|---|---|
| 00b | 此次传输使用PRP进行寻址 |
| 01b | 此次传输使用SGL进行寻址 |
| 10b | 此次传输使用SGL进行寻址 |
| 11b | 保留 |
1.3.1 PRP(Physical Region Page Entry)
PRP模型比较简单,一个PRP Entry就是一个64位的物理内存地址,一个PRP Entry描述的是一个物理页。具体物理页大小是多少由操作系统决定,操作系统通过写Controller Configuration寄存器的MPS位来告诉NVM子系统物理页大小是多少。NVMe规定,物理页大小应该在 4KB 到 128MB 之间。
在NVMe over PCIe协议中,PRP既可以用在Admin命令中,也可以用在IO命令中。
一个PRP Entry的结构如下图所示:

Page Base Address表示页基地址,Offset表示页内偏移地址。Offset占多少位,完全取决于物理页有多大。如果一个物理页是4KB,那么Offset就占12位。注意:PRP Entry是四字节对齐的,因此Offset的最低两位必须为0。
PRP Entry能够描述一块内存,这块内存从PRP Entry所指示的地址开始,到这一页的页尾结束,因此,PRP Entry最大能够表示一个物理页的内存空间(此时Offset部分为全0)。
NVMe的命令报文中,有一个16byte的空间DPTR(Data Pointer),当PSDT的取值为00b时,这里面存放的就是PRP,如下图所示:

16byte的空间最多存放两条PRP Entry。这样,两个PRP Entry最多只能表示两个物理页,如果这次数据传输所传输的数据大于两个物理页怎么办?此时,PRP Entry 2便不再指向一个普通的物理页,而是会指向一个PRP List。(有个疑问,Controller如何确定PRP Entry 2是一个普通的PRP Entry还是PRP List?)
PRP List的结构如下图所示:

PRP List存在于host端内存物理页中连续的一段内存中。(所以一个PRP List最多包含多少个PRP Entry?答案是:物理页大小/PRP Entry大小8Byte)这样,Controller会先DMA取PRP List,然后根据PRP List中所描述的地址,在进行一次DMA,去取真正的数据。如果一个PRP List还不足以描述所传输的数据量,那么这个PRP List的最后一个PRP Entry依然会指向一个PRP List。(同样的疑问,Controller如何确定PRP List的最后一个PRP Entry是一个普通的PRP Entry还是PRP List?)
1.3.2 SGL(Scatter Gather List)
SGL是内存中用来描述一段数据缓冲区的数据结构。这段缓冲区可以是源缓冲区,也可以是目的缓冲区。
一个SGL是一个链表,它包含多个SGL segment,一个SGL segment包含一个SGL descriptor数组。SGL descriptor的大小是16字节,如下所示:

SGL描述符的数据格式如下所示:

在SGL描述符中,使用SGL Descriptor Type和SGL Descriptor Sub Type两个字段来描述SGL描述符的类型。
在NVMe1.4中,SGL Descriptor Type有下面几种取值:
| 取值 | 描述符类型 |
|---|---|
| 0h | SGL Data Block descriptor |
| 1h | SGL Bit Bucket descriptor |
| 2h | SGL Segment descriptor |
| 3h | SGL Last Segment descriptor |
| 4h | Keyed SGL Data Block descriptor |
| 5h | Transport SGL Data Block descriptor |
| 6h ~ Eh | 保留 |
| Fh | 由厂商规定 |
SGL Descriptor Sub Type有下面几种取值:
| SGL Descriptor Type取值 | SGL Descriptor Sub Type取值 | 解释说明 |
|---|---|---|
| 0h,2h,3h,4h | 0h | SGL描述符中的address字段描述的是物理内存的起始地址。 |
| 0h,2h,3h | 1h | SGL描述符中的address字段描述的是要传输的数据在NVMeOF报文中的偏移量。 |
| 任意值 | Ah ~ Fh | NVMe传输层协议所特有的。 |
在 NVMe over PCIe 协议中,SGL Descriptor Sub Type只取0h,在 NVMe over Fabric 中,可以取1h,也可以取0h。后面的 NVMe over Fabric 协议还会具体讲解SGL Descriptor Sub Type取值为1h的含义是什么。
SGL Data Block descriptor

SGL Data Block descriptor指示的是内存中的一块数据块。在读或写SSD的时候,应该包含这块数据块。
当SGL Descriptor Sub Type取不同的值时,Address有两种含义,参见上面关于SGL Descriptor Sub Type取值的表格描述。
注意,Address + Length不能超过1_00000000_00000000h。
SGL Bit Bucket descriptor

只有在Controller往Host端写数据时,它才是有意义的。它告诉Controller,接下来的指定Length的逻辑块不应该传递到Host端的内存中。
SGL Segment descriptor

它指向下一个SGL segment。Address指向下一个SGL segment的首地址,Length指示下一个SGL segment的字节长度,一个SGL descriptor占16byte,所以Length应该是16的倍数,并且Address + Length不能超过1_00000000_00000000h。
当SGL Descriptor Sub Type取不同的值时,Address有两种含义,参见上面关于SGL Descriptor Sub Type取值的表格描述。
SGL Last Segment descriptor
它和SGL Segment descriptor只有一个区别,就是它指向的这个SGL segment应该是此次数据传输所用到的最后一个SGL segment。(疑问?为什么要区分SGL Segment descriptor和SGL Last Segment descriptor?)
Keyed SGL Data Block descriptor

它和SGL Data Block descriptor差不多,只不过它包含了一个Key,这个Key是用于访问数据块的钥匙(猜想可能是为了安全?)。
Address + Length不能超过1_00000000_00000000h。
Transport SGL Data Block descriptor
它是NVMe Transport Binding协议中规范的一种SGL描述符类型。
SGL传输模型举例
下面是Host端使用SGL来读取SSD中数据的一个实例。逻辑块Logic Block大小是512B,可访问的逻辑块总长度是13KB,但是Host只需要11KB的数据。NVMe命令中的Number of Logical Blocks (NLB)字段应该被设为26。
如下所示,总共有三个SGL segment,第二个SGL segment里面有一个Bit Bucket descriptor,告诉Controller,接下来2KB的数据不用传输到Host端。


















 2173
2173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









