









Bayesian GAN
1.简介
贝叶斯 GAN(Saatchi 和 Wilson,2017)是生成对抗网络(Goodfellow,2014)的贝叶斯公式,我们在其中学习生成器参数 θ g \theta_g θg 和鉴别器参数 θ d \theta_d θd 的分布,而不是优化 用于点估计。 贝叶斯方法的优点包括在参数空间中灵活地建模多模态,以及在最大似然(非贝叶斯)情况下防止模式崩溃的能力。
我们通过称为“随机梯度哈密顿蒙特卡罗(SGHMC)”的近似推理算法来学习贝叶斯 GAN,这是一种基于梯度的 MCMC 方法,其样本近似于 θ g \theta_g θg 和 θ d \theta_d θd 的真实后验分布。
贝叶斯 GAN 训练过程从固定分布(通常是标准 d-dim 正态分布)中采样噪声 z z z 开始。 噪声被馈送到生成器,其中参数 θ g \theta_g θg 从后验分布 p ( θ g ∣ D ) p(\theta_g | D) p(θg∣D) 中采样。 给定参数 θ g \theta_g θg ( G ( z ∣ θ g ) G(z|\theta_g) G(z∣θg)) 生成的图像以及真实数据呈现给鉴别器,其参数是从其后验分布 p ( θ d ∣ D ) p(\theta_d|D) p(θd∣D) 中采样的 。 我们使用梯度 ∂ log p ( θ g ∣ D ) ∂ θ g \frac{\partial \log p(\theta_g|D) }{\partial \theta_g } ∂θg∂logp(θg∣D) 和 ∂ log p ( θ d ∣ D ) ∂ θ d \frac{\partial \log p(\theta_d|D) }{\partial \theta_d } ∂θd∂logp(θd∣D) 更新后验与随机梯度哈密顿蒙特卡罗 (SGHMC)。
SGHMC 通过优化噪声损失
首先,观察到除了噪声 n \boldsymbol{n} n 之外,更新规则与动量 SGD 类似。 事实上,如果没有 n \boldsymbol{n} n,这相当于执行动量 SGD,损失为 − ∑ i = 1 J g ∑ k = 1 J d log posterior - \sum_{i=1}{J_g} \sum_{k=1}^{J_d} \log \text{posterior} −∑i=1Jg∑k=1Jdlogposterior。 为了简单起见,我们将描述 J g = J d = 1 J_g = J_d=1 Jg=Jd=1 的情况。
我们使用主要损失
L
=
−
log
p
(
θ
∣
.
.
)
\mathcal{L} = - \log p(\theta | ..)
L=−logp(θ∣..) 并添加噪声损失
L
noise
=
1
η
θ
⋅
n
\mathcal{L}_\text{noise} = \frac{1}{\eta } \theta \cdot \boldsymbol{n}
Lnoise=η1θ⋅n 其中
n
∼
N
(
0
,
2
α
η
I
)
\boldsymbol{n} \sim \mathcal{N}(0, 2 \alpha \eta I)
n∼N(0,2αηI) 从而优化损失函数
L
+
L
noise
\mathcal{L} + \mathcal{L}_\text{noise}
L+Lnoise 与动量 SGD 相当于执行 SGHMC 更新步骤。

2. 算法
下面(公式 3 和 4)是后验概率,其中每个误差项对应其负对数概率。

其中
K
K
K表示对象的总类别的数量。
D
(
x
(
i
)
=
y
(
i
)
;
θ
d
)
D(x^{(i)} = y^{(i)}; \theta_d)
D(x(i)=y(i);θd) 表示辨别器认为样本
x
(
i
)
x^{(i)}
x(i) 属于
y
(
i
)
y^{(i)}
y(i) 类的概率。
2.1 对于鉴别器
errD = errD_real + errD_fake + err_sup + errD_prior + errD_noise
不知道 errD_noise是个啥
2.1.1 errD_real
需要保证无监督学习的差异性(优化分类)
errD_real
=
∏
i
=
1
n
d
∑
y
=
1
K
D
(
x
(
i
)
=
y
;
θ
d
)
\text{errD\_real}=\prod_{i=1}^{n_d}\sum_{y=1}^KD(x^{(i)}=y;\theta_d)
errD_real=i=1∏ndy=1∑KD(x(i)=y;θd)
只需要输出 size = * × number of classs
errD_real = criterion_comp(output)
2.1.2 errD_fake
需要保证能够鉴别出假数据(优化鉴别)
errD_fake
=
∏
i
=
1
n
g
D
(
G
(
z
(
i
)
;
θ
g
)
=
0
;
θ
d
)
\text{errD\_fake}=\prod_{i=1}^{n_g}D(G(z^{(i)};\theta_g)=0;\theta_d)
errD_fake=i=1∏ngD(G(z(i);θg)=0;θd)
需要辨别器以及标签全为0
output = netD(fake.detach())
labelv = Variable(torch.LongTensor(fake.data.shape[0]).cuda().fill_(fake_label))
errD_fake = criterion(output, labelv)
2.1.3 errD_sup
(优化监督分类)
errD_sup
=
∏
i
=
1
n
s
∑
y
=
1
K
D
(
x
s
(
i
)
=
y
s
(
i
)
;
θ
d
)
\text{errD\_sup}=\prod_{i=1}^{n_s}\sum_{y=1}^KD(x^{(i)}_s=y_s^{(i)};\theta_d)
errD_sup=i=1∏nsy=1∑KD(xs(i)=ys(i);θd)
output_sup = netD(input_sup_v)
err_sup = criterion(output_sup, target_sup_v)
2.2.4 errD_prior
p ( θ d ∣ α d ) p(\theta_d|\alpha_d) p(θd∣αd)
errD_prior = dprior_criterion(netD.parameters())
errD_prior.backward()
errD_noise = dnoise_criterion(netD.parameters())
errD_noise.backward()
2.2 生成器
2.2.1 errG
errG = ∏ i = 1 n g ∑ y = 1 K D ( z s ( i ) = y ; θ d ) \text{errG}=\prod_{i=1}^{n_g}\sum_{y=1}^KD(z^{(i)}_s=y;\theta_d) errG=i=1∏ngy=1∑KD(zs(i)=y;θd)
output = netD(fake)
errG = criterion_comp(output)
2.2.2 errG_prior
if opt.bayes:
for netG in netGs:
errG += gprior_criterion(netG.parameters())
errG += gnoise_criterion(netG.parameters())
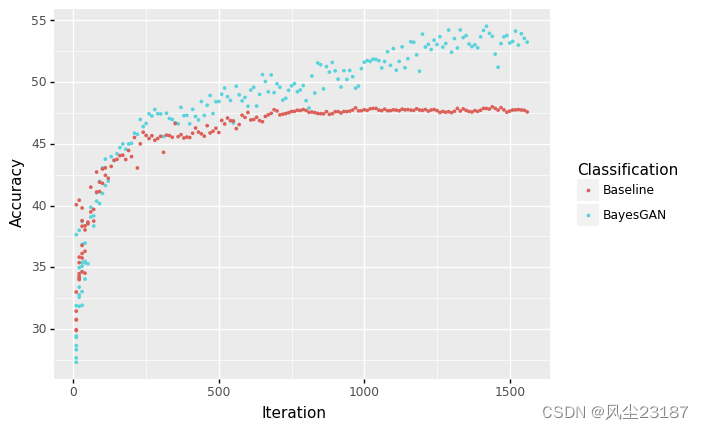
第三个链接中得到了如下图像。证明了用生成数据能够提升模型的泛化能力。接下来将详细分析泛化能力的来源
iteration = 0
for epoch in range(opt.niter):
top1 = AverageMeter()
top1_weakD = AverageMeter()
for i, data in enumerate(dataloader):
iteration += 1
#######
# 1. real input
netD.zero_grad()
_input, _ = data
batch_size = _input.size(0)
if opt.cuda:
_input = _input.cuda()
input.resize_as_(_input).copy_(_input)
label.resize_(batch_size).fill_(real_label)
inputv = Variable(input)
labelv = Variable(label)
output = netD(inputv)
errD_real = criterion_comp(output)
errD_real.backward()
# calculate D_x, the probability that real data are classified
D_x = 1 - torch.nn.functional.softmax(output,dim=1).data[:, 0].mean()
#######
# 2. Generated input
fakes = []
for _idxz in range(opt.numz):
noise.resize_(batch_size, opt.nz, 1, 1).normal_(0, 1)
noisev = Variable(noise)
for _idxm in range(opt.num_mcmc):
idx = _idxz*opt.num_mcmc + _idxm
netG = netGs[idx]
_fake = netG(noisev)
fakes.append(_fake)
fake = torch.cat(fakes)
output = netD(fake.detach())
labelv = Variable(torch.LongTensor(fake.data.shape[0]).cuda().fill_(fake_label))
errD_fake = criterion(output, labelv)
errD_fake.backward()
D_G_z1 = 1 - torch.nn.functional.softmax(output,dim=1).data[:, 0].mean()
#######
# 3. Labeled Data Part (for semi-supervised learning)
for ii, (input_sup, target_sup) in enumerate(dataloader_semi):
input_sup, target_sup = input_sup.cuda(), target_sup.cuda()
break
input_sup_v = Variable(input_sup.cuda())
# convert target indicies from 0 to 9 to 1 to 10
target_sup_v = Variable( (target_sup + 1).cuda())
output_sup = netD(input_sup_v)
err_sup = criterion(output_sup, target_sup_v)
err_sup.backward()
prec1 = accuracy(output_sup.data, target_sup + 1, topk=(1,))[0]
top1.update(prec1.item(), input_sup.size(0))
if opt.bayes:
errD_prior = dprior_criterion(netD.parameters())
errD_prior.backward()
errD_noise = dnoise_criterion(netD.parameters())
errD_noise.backward()
errD = errD_real + errD_fake + err_sup + errD_prior + errD_noise
else:
errD = errD_real + errD_fake + err_sup
optimizerD.step()
# 4. Generator
for netG in netGs:
netG.zero_grad()
labelv = Variable(torch.FloatTensor(fake.data.shape[0]).cuda().fill_(real_label))
output = netD(fake)
errG = criterion_comp(output)
# print(errG)
if opt.bayes:
for netG in netGs:
errG += gprior_criterion(netG.parameters())
errG += gnoise_criterion(netG.parameters())
errG.backward()
D_G_z2 = 1 - torch.nn.functional.softmax(output,dim=1).data[:, 0].mean()
for optimizerG in optimizerGs:
optimizerG.step()
# 5. Fully supervised training (running in parallel for comparison)
netD_fullsup.zero_grad()
input_fullsup = Variable(input_sup)
target_fullsup = Variable((target_sup + 1))
output_fullsup = netD_fullsup(input_fullsup)
err_fullsup = criterion_fullsup(output_fullsup, target_fullsup)
optimizerD_fullsup.zero_grad()
err_fullsup.backward()
optimizerD_fullsup.step()
# 6. get test accuracy after every interval
if iteration % opt.stats_interval == 0:
# get test accuracy on train and test
netD.eval()
get_test_accuracy(netD, iteration, label='semi')
get_test_accuracy(netD_fullsup, iteration, label='sup')
netD.train()
# 7. Report for this iteration
cur_val, ave_val = top1.val, top1.avg
log_value('train_acc', top1.avg, iteration)
print('[%d/%d][%d/%d] Loss_D: %.2f Loss_G: %.2f D(x): %.2f D(G(z)): %.2f / %.2f | Acc %.1f / %.1f'
% (epoch, opt.niter, i, len(dataloader),
errD.data.item(), errG.item(), D_x, D_G_z1, D_G_z2, cur_val, ave_val))
# after each epoch, save images
vutils.save_image(_input,
'%s/real_samples.png' % opt.outf,
normalize=True)
for _zid in range(opt.numz):
for _mid in range(opt.num_mcmc):
idx = _zid*opt.num_mcmc + _mid
netG = netGs[idx]
fake = netG(fixed_noise)
vutils.save_image(fake.data,
'%s/fake_samples_epoch_%03d_G_z%02d_m%02d.png' % (opt.outf, epoch, _zid, _mid),
normalize=True)
for ii, netG in enumerate(netGs):
torch.save(netG.state_dict(), '%s/netG%d_epoch_%d.pth' % (opt.outf, ii, epoch))
torch.save(netD.state_dict(), '%s/netD_epoch_%d.pth' % (opt.outf, epoch))
torch.save(netD_fullsup.state_dict(), '%s/netD_fullsup_epoch_%d.pth' % (opt.outf, epoch))
接下来我们将借鉴此框架,融合这篇论文训练生成视频的算法。并用于视频分类。















 2093
2093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











