







摘要
本文介绍了DeepSeek-R1这一新一代推理模型,旨在通过强化学习(RL)来提升大规模语言模型(LLMs)的推理能力。我们提出了两个版本的模型:DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero是通过大规模强化学习训练,而不依赖任何监督学习的初步微调,取得了令人惊讶的推理能力。然而,它在可读性和语言混合等方面仍存在挑战。为了解决这些问题,我们引入了DeepSeek-R1,它在强化学习之前加入了冷启动数据,并通过多阶段训练进一步提升推理表现。DeepSeek-R1在推理任务上的表现与OpenAI的o1-1217模型相当。此外,我们还展示了如何通过将DeepSeek-R1的推理能力提炼到较小的模型中,从而让这些小模型也能表现出强大的推理能力。
我们开源了DeepSeek-R1-Zero、DeepSeek-R1及六个从DeepSeek-R1提炼的小型模型(1.5B、7B、8B、14B、32B、70B),以便支持更广泛的研究。
1. 引言
近年来,大型语言模型(LLMs)在各个任务上的表现不断取得突破,接近了人工通用智能(AGI)的水平。特别是在推理任务方面,OpenAI的o1系列模型通过增加**思维链(CoT)**的推理长度,实现了在数学、编程和科学推理等任务上的显著提升。然而,在测试时如何有效地扩展推理能力仍然是一个未解难题。
以往的研究尝试了多种方法,包括基于过程的奖励模型、强化学习(RL)以及搜索算法等。然而,没有一种方法能够在推理能力上与OpenAI的o1系列模型相媲美。
本文的目标是通过纯强化学习来提高大规模语言模型的推理能力,不依赖任何监督学习数据。具体来说,我们使用DeepSeek-V3-Base作为基础模型,并通过GRPO(Group Relative Policy Optimization)这一强化学习框架,推动模型在推理任务上的表现不断提升。经过数千步的强化学习训练,DeepSeek-R1-Zero展现出了非常强大的推理能力,在AIME 2024和Codeforces等基准测试中取得了令人瞩目的成绩。
Group Relative Policy Optimization(GRPO)摒弃了通常与策略模型大小相同的评论模型,改为通过群组得分来估计基准。具体而言,对于每个问题 𝑞,GRPO 从旧策略 𝜋𝜃𝑜𝑙𝑑 中采样一组输出 {𝑜1,𝑜2,··· ,𝑜𝐺},然后通过最大化以下目标来优化策略模型 𝜋𝜃:
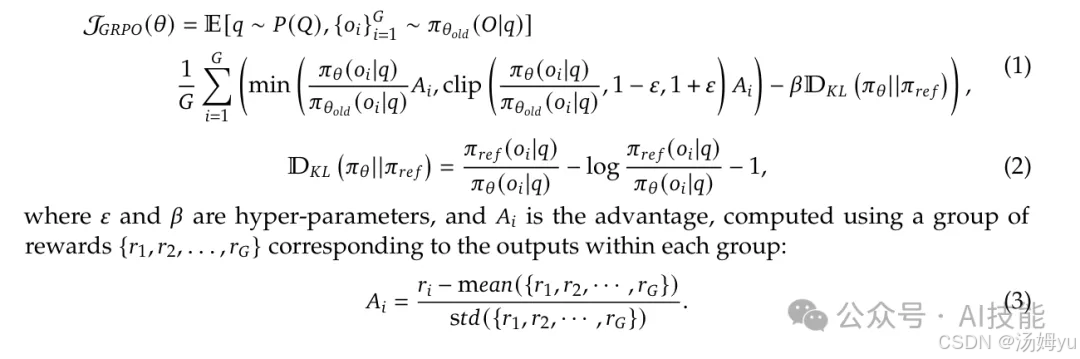
然而,DeepSeek-R1-Zero在可读性和语言混合问题上仍面临挑战。为了解决这些问题并进一步提升推理表现,我们推出了DeepSeek-R1,通过引入冷启动数据和多阶段训练,解决了这些问题,使其推理能力更加健全。
此外,我们还展示了模型蒸馏(Distillation)的效果,将DeepSeek-R1的推理能力提炼到小型模型中,这些小模型虽然在参数量上较少,但同样能够进行强力的推理。
1.1 主要贡献
1.1.1 后期训练:通过强化学习提升基础模型
-
DeepSeek-R1-Zero:我们首次通过纯强化学习对基础模型进行训练,完全不依赖监督学习。DeepSeek-R1-Zero通过强化学习自主发展出强大的推理行为,如自我验证、反思和生成长思维链等。这一突破性成果验证了在没有监督数据的情况下,通过强化学习来激励模型的推理能力。
-
DeepSeek-R1:我们提出了一个多阶段训练流程,结合冷启动数据和强化学习,通过两轮强化学习和两轮监督微调(SFT),进一步提升了模型的推理能力。经过训练,DeepSeek-R1的推理能力已经与OpenAI的o1-1217模型相当,且在多个任务上表现优异。
1.1.2 模型蒸馏:赋予小模型推理能力
-
模型蒸馏:我们展示了通过将大模型的推理模式提炼到小型模型中,可以在较小的计算资源下也实现出色的推理表现。这个过程不仅提升了小模型的推理能力,还提高了其在多个基准测试中的成绩。
-
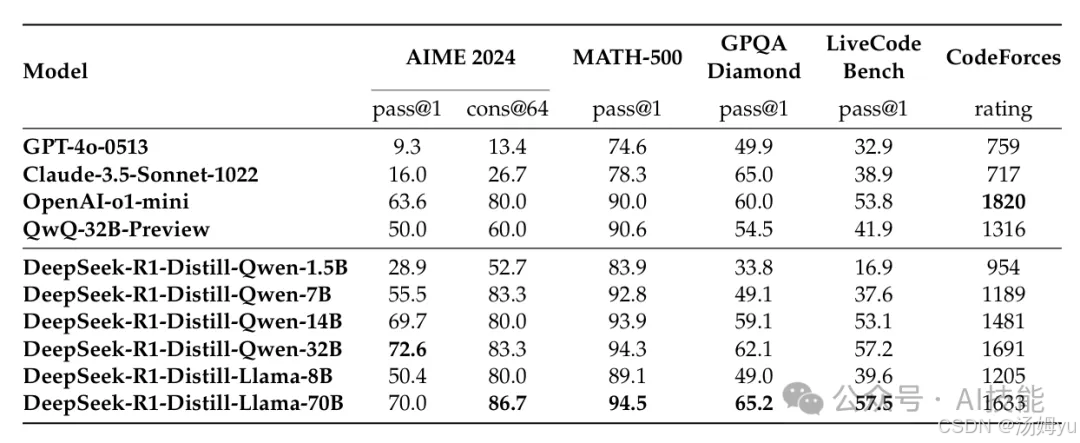
我们将DeepSeek-R1蒸馏成多个较小的模型,如DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Llama-70B,这些模型在AIME 2024、MATH-500等测试中取得了超越现有模型的好成绩。
1.1.3 开源共享
-
我们将DeepSeek-R1、DeepSeek-R1-Zero及六个蒸馏模型(从1.5B到70B)开源,并提供了API接口,方便研究人员进一步开发和应用这些模型。
-
1.2 评估结果总结
-
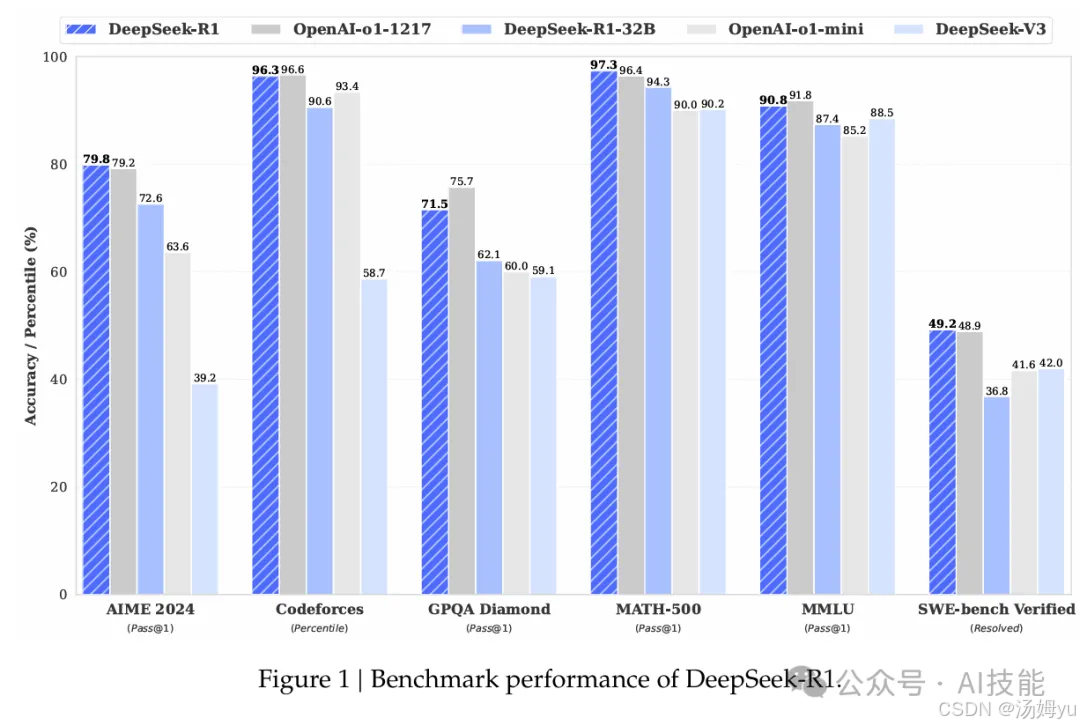
推理任务:DeepSeek-R1在AIME 2024上的Pass@1为79.8%,稍微超过了OpenAI-o1-1217。在MATH-500上,它达到了97.3% Pass@1,远超其他模型。同时,在编程相关任务中,DeepSeek-R1也表现出了专业水准,在Codeforces上达到了2,029 Elo评分,超过了96.3%的竞争者。
-
知识任务:在MMLU、MMLU-Pro和GPQA Diamond等知识类基准测试中,DeepSeek-R1也取得了优秀成绩,表现略低于OpenAI-o1-1217,但优于其他闭源模型,显示出其在教育类任务中的竞争力。
-
其他任务:DeepSeek-R1在非考试类任务(如创意写作、问题回答、摘要等)中同样表现强劲,AlpacaEval 2.0和ArenaHard的胜率分别为87.6%和92.3%,展示了其在开放性问题回答上的强大能力。
-
长上下文任务表现:DeepSeek-R1在需要长上下文理解的任务上,如AlpacaEval 2.0和LiveCodeBench,表现明显超越了DeepSeek-V3。
2. 方法
2.1 概述
传统上,许多方法都依赖大量的监督数据来提升模型的推理能力。本文提出的方法表明,通过强化学习就能够显著提升推理能力,而不依赖于监督学习数据。我们的工作可以分为两个阶段:
-
DeepSeek-R1-Zero:直接在基础模型上应用强化学习,不依赖任何冷启动数据或监督学习。
-
DeepSeek-R1:通过冷启动数据、监督微调(SFT)和强化学习的多阶段训练,进一步精炼推理能力。
此外,我们还通过蒸馏方法,将DeepSeek-R1的推理能力提炼到小型模型中,达到在较小计算资源下也能进行强力推理的效果。
2.2 DeepSeek-R1-Zero:基础模型的强化学习
强化学习算法:我们采用了**Group Relative Policy Optimization(GRPO)**来进行强化学习训练,通过避免使用传统的评估模型,改为基于输出群体评分来估算基线。这种方法可以有效降低训练成本,优化模型的推理表现。
奖励建模:我们使用基于规则的奖励系统,包含两种主要奖励类型:
-
准确性奖励:用于判断模型回答的准确性。
-
格式奖励:强制模型在推理过程中将思维过程置于特定标签(例如
<think>和</think>)之间,以便提高可读性。
2.2.4 DeepSeek-R1-Zero的表现、自我进化过程和“顿悟时刻”
表现:在强化学习训练过程中,DeepSeek-R1-Zero表现出显著的性能提升。以AIME 2024为例,Pass@1从15.6%提高到71.0%,采用多数投票后,成绩进一步提升至86.7%,超越了OpenAI的o1-0912。
自我进化:模型通过强化学习训练,逐渐学会处理更复杂的推理任务。DeepSeek-R1-Zero表现出内在的推理进化能力,通过延长测试计算时间,生成更深入的推理过程。
顿悟时刻:在训练过程中,出现了“顿悟时刻”,即模型开始重新评估自己的初步推理方法,主动分配更多的思考时间,解决问题时展现出了新的推理策略。
2.3 DeepSeek-R1:带冷启动的强化学习
为了提升可读性和避免语言混合,我们引入了冷启动数据,在DeepSeek-R1的训练中,通过微调基础模型来进行冷启动,从而提高了模型的推理质量和可读性。
3、结论与未来工作
我们展示了通过强化学习提升推理能力的可行性,DeepSeek-R1在多项推理任务中表现出色,且通过蒸馏技术,成功将其推理能力转移到小型模型中。未来的研究将专注于提升DeepSeek-R1在更多领域(如多轮对话、复杂角色扮演等)中的表现,解决语言混合问题,并进一步优化推理模型在软件工程任务中的效率。


















 1400
1400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











