







书生·浦语大模型全链路开源体系
大模型成为发展通用人工智能的重要途径
专用模型:针对特定任务,一个模型解决一个问题
通用大模型:一个模型应对多种任务、多种模态
书生浦语大模型开源历程
2023.6.7:InternLM千亿参数语言大模型发布
2023.7.6:InternLM千亿参数大模型全面升级,支持8K语境、26种语言。
全面开源,免费商用:InternLM-7B模型、全链条开源工具体系
2023.8.14:书生万卷1.0多模态预训练语料库开源发布
2023.8.21:升级版对话,模型InternLM-Chat-7B v1.1发布,开源智能体框架Lagent,支持从语言模型到智能体升级转换
2023.8.28:InternLM千亿参数模型参数量升级到123B
2023.9.20:增强型InternLM-20B开源,开源工具链全线升级
书生浦语20B开源大模型性能
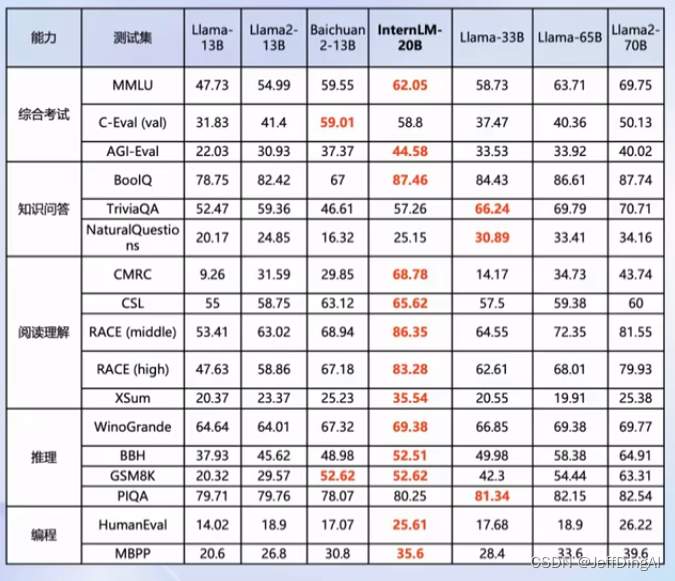
- 全面领先相近量级的开源模型(包括Llama-33B、Llama2-13B以及国内主流的7B、13B开源模型)
- 以不足三分之一的参数量、达到Llama2-70B水平
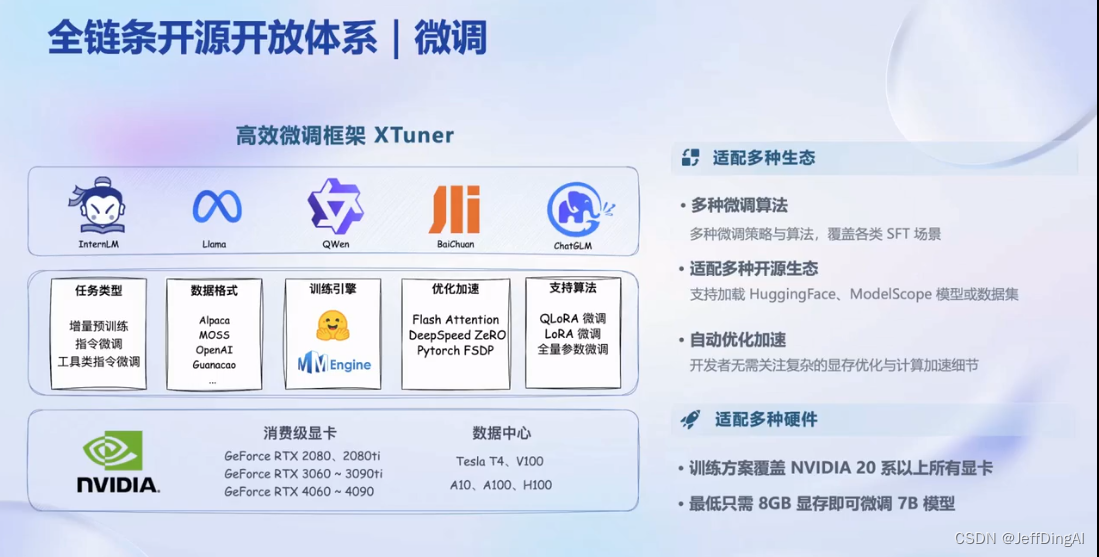
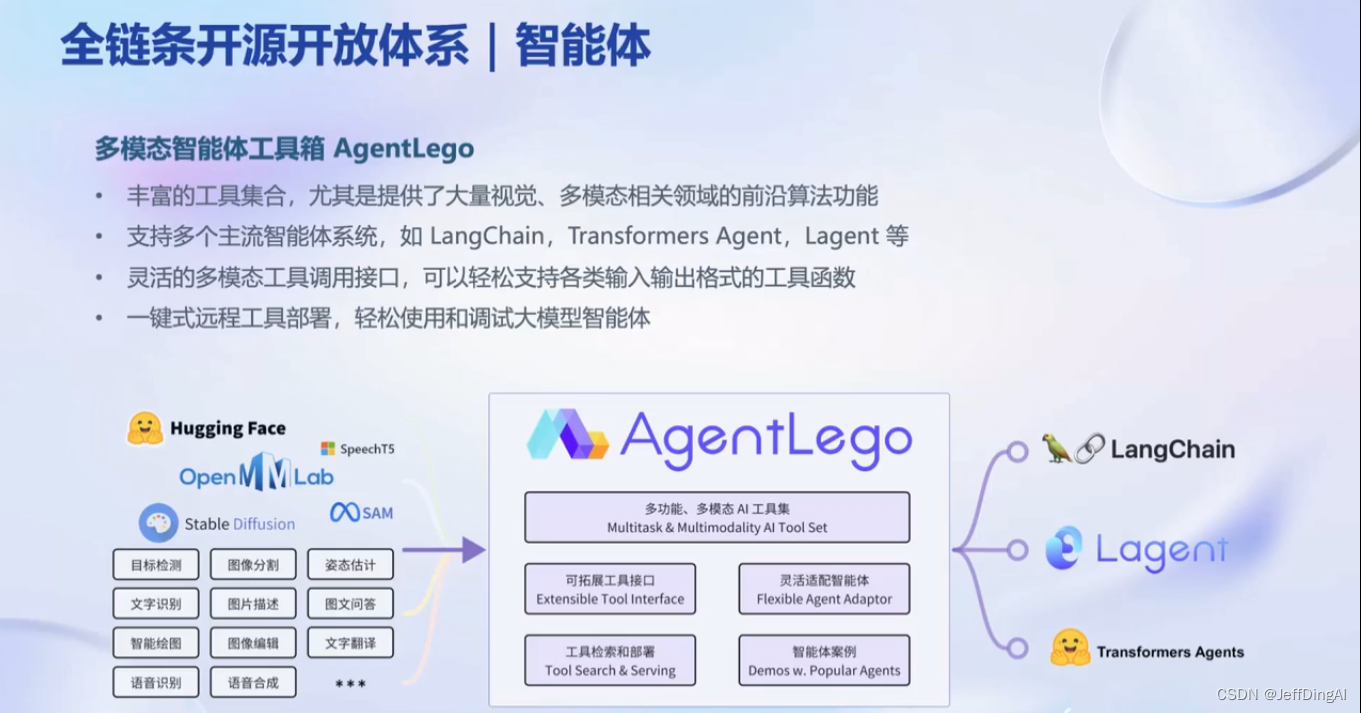
书生浦语全链条开源开放体系
数据:书生万卷 2TB数据,覆盖多种模态与任务

预训练:InternLM-Train 并行训练、极致优化速度达到3600tokens/sec/gpu

微调:XTuner 支持全参数微调,支持LoRA等低成本微调
部署:LMDeploy 全链路部署、性能优先,每秒生成2000+ tokens

评测:OpenCompass 全方位评测,性能可复现,80套评测集,40万道题目

应用:AgenitLego 支持多种智能体,支持代码解释器等多种工具















 1465
1465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









