









文章转自公众号老刘说NLP
我们来看两个工作,关于大模型量化方法的一些总结以及EDC:大模型用于信息抽取框架。
会有一些收获。
里面提到23个主流的大模型推理框架以及新的知识图谱构建流程,很有意思
一、EDC:大模型用于信息抽取框架
关于大模型用于信息抽取,最近的工作《Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction》,https://arxiv.org/pdf/2404.03868v2,https://github.com/clear-nus/edc,这篇文章介绍了一个基于大模型的框架,用于从文本中自动构建知识图谱。这个框架被称为Extract-Define-Canonicalize(EDC),分为三个阶段:开放信息提取、模式定义和模式规范化。
我们可以看下其具体实现细节:

1、开放信息提取(Open Information Extraction):
利用大模型进行少量样本提示(few-shot prompting),从输入文本中识别并提取关系三元组([Subject, Relation, Object]),这个过程不依赖于任何特定的模式(schema)。

例如,给定文本“Alan Shepard was born on Nov 18, 1923 and selected by NASA in 1959. He was a member of the Apollo 14 crew”,LLMs会提取出三元组[‘Alan Shepard’, ‘bornOn’, ‘Nov 18, 1923’]和[‘Alan Shepard’, ‘participatedIn’, ‘Apollo 14’]。
2、模式定义(Schema Definition):
接下来,通过提示LLMs为开放知识图谱中提取的每个模式组件(例如实体类型和关系类型)提供自然语言定义。

例如,对于关系‘bornOn’和‘participatedIn’,LLMs会生成它们的定义,这些定义随后作为辅助信息用于规范化阶段。
3、模式规范化(Schema Canonicalization):
第三阶段的目标是将开放知识图谱提炼成规范形式,消除冗余和歧义。
使用句子转换器将每个模式组件的定义向量化,创建嵌入(embeddings)。


规范化过程根据目标模式的可用性采取两种方式之一:
一个是目标对齐(Target Alignment):在存在目标模式的情况下,识别目标模式中与每个元素最相关的组件,考虑它们进行规范化。LLMs评估每个潜在转换的可行性,如果转换不合理,则表示目标模式中没有语义等价物,该组件及其相关三元组将被排除。
另一个是自我规范化(Self Canonicalization):在没有目标模式的情况下,目标是整合语义相似的模式组件,将它们标准化为单一表示,以简化知识图谱。从空的规范模式开始,通过向量相似性和LLM验证,检查开放知识图谱三元组中的潜在整合候选者。
4、迭代细化(EDC+R: iteratively refine EDC with Schema Retriever):
利用EDC生成的数据来提高提取三元组的质量。
通过提供之前提取的三元组和相关部分的模式作为提示,在初始提取期间重复EDC。
二、关于大模型量化方法的一些总结
最近的工作《A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms》,https://arxiv.org/abs/2409.16694,是关于大型语言模型(LLMs)的低比特量化技术的综述,看看也不错。
我们来看看其中的几个点:
1、LLM量化方法的框架
图1展示了大型语言模型(LLM)量化方法的框架结构,这张图通过分解量化过程的主要组成部分,帮助读者理解量化方法的不同方面。
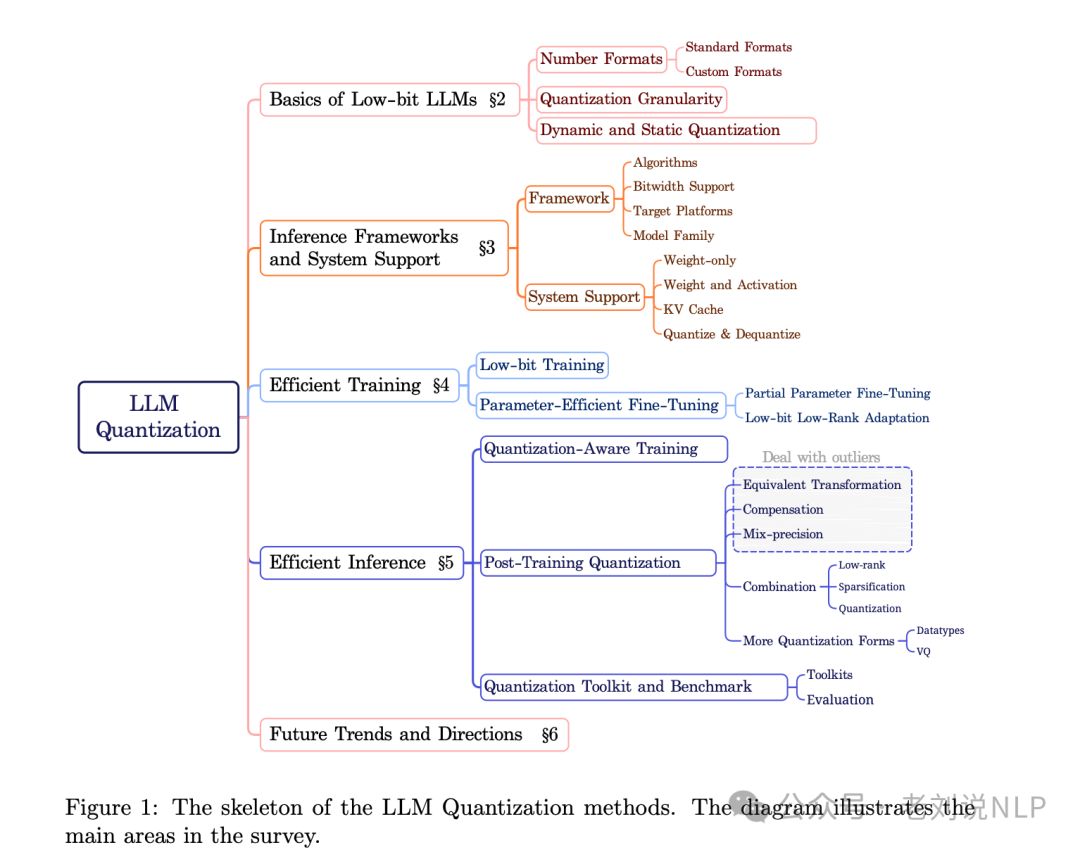
1)Number Formats(数字格式):标准格式(Standard Formats):介绍了在量化中使用的标准化数字格式,如浮点数(FP)、微浮点数(Micro-FP)、整数(INT)、二进制(Bi)等;定制格式(Custom Formats):针对LLMs设计的特定数字格式,如Flint、Abfloat、SF等,这些格式旨在更好地处理模型中的异常值或提高计算效率。
2)Quantization Granularity(量化粒度):量化可以在不同层次上进行,例如整个张量(Tensor-wise)、每个token(Token-wise)、通道组(Channel Group-wise)、元素级别(Element-wise)等。
3)Dynamic and Static Quantization(动态和静态量化):动态量化(Dynamic Quantization):不需要校准,量化参数实时计算,简化了量化模型的准备。静态量化(Static Quantization):需要预先校准量化参数,但提供了更快的推理性能。
4)Inference Frameworks and System Support(推理框架和系统支持):支持量化LLMs的框架和系统,包括不同的算法、支持的硬件平台、模型家族等。
5)Efficient Training(高效训练):低比特训练技术,如低比特训练、参数高效微调等。
6)Efficient Inference(高效推理):LLMs的量化感知训练和后训练量化方法,包括等效转换、补偿、混合精度、组合量化等技术。
7)Quantization Toolkit and Benchmark(量化工具包和基准测试):支持准确低比特LLMs开发的集成算法工具包。
8)Future Trends and Directions(未来趋势和方向):LLM量化的未来趋势和潜在进展。
图1作为一个框架图,提供了一个清晰的视角来理解文章中讨论的量化技术和策略。它将复杂的量化过程分解为可管理的部分,使得读者可以更容易地跟随文章的论述。
2、针对量化大模型推理框架
表2中列出了一些代表性的推理框架。目前,没有一个单一的推理框架在性能或使用上占据主导地位。
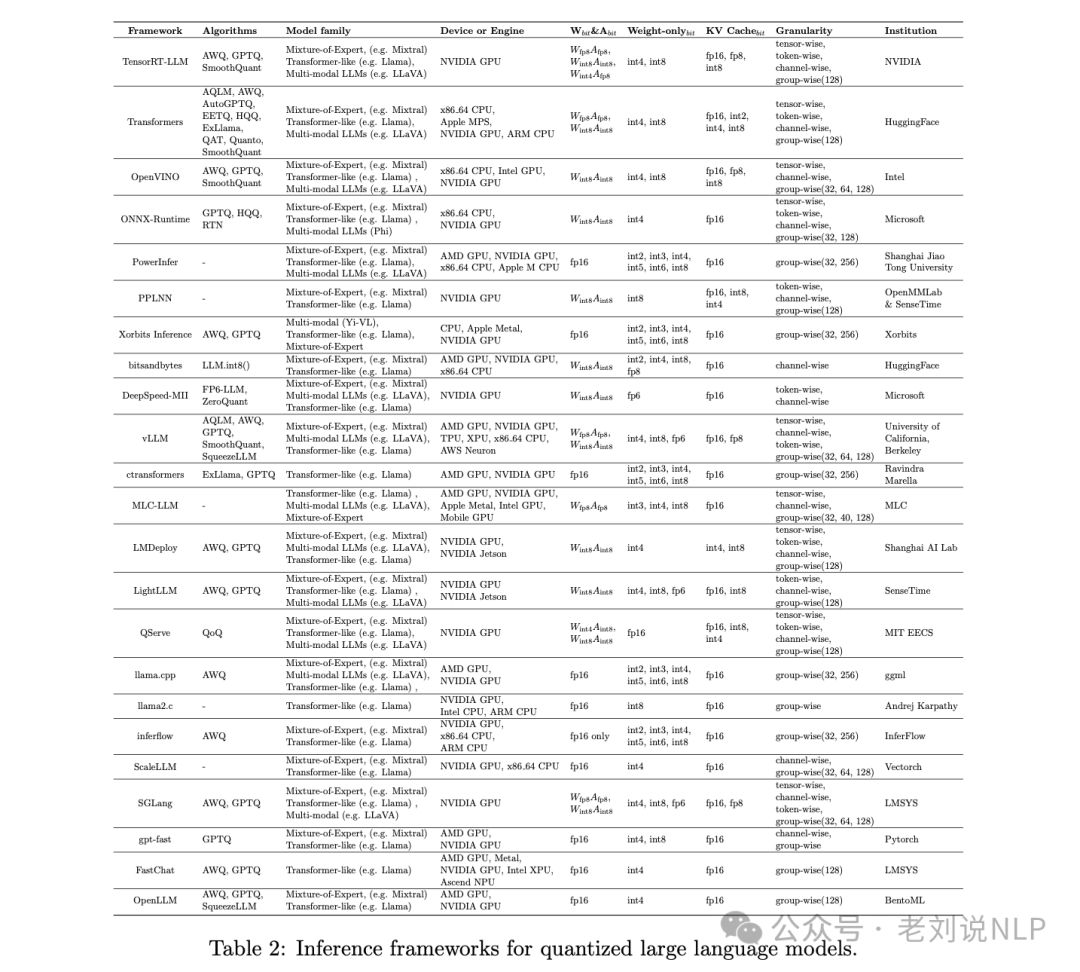
然而,一些经典的深度学习框架,比如TensorRT-LLM、ONNX-runtime、Transformers(Huggingface)、OpenVINO、PowerInfer、PPLNN和Xorbits Inference已经集成了对大型模型高效推理的支持。
此外,随着大型模型的出现,还出现了其他专门为LLMs提出的推理框架,如bitsandbytes、ctransformers、MLC-LLM、DeepSpeed-MII、vLLM、LMDeploy、LightLLM、QServe、llama.cpp、llama2.c、inferflow、ScaleLLM、SGLang、gpt-fast、FastChat2、OpenLLM等等。这些框架轻量级,并且已经集成了许多针对大型模型的专业优化技术。
可以看下具体的项目地址:
1)TensorRT-LLM1:https://github.com/NVIDIA/TensorRT-LLM
2)ONNX-runtime:https://github.com/microsoft/onnxruntime
3)Transformers (Huggingface):https://huggingface.co/docs/transformers/en/index
4)OpenVINO:https://github.com/openvinotoolkit/nncf
5)PowerInfer:https://github.com/SJTU-IPADS/PowerInfer
6)PPLNN:https://github.com/openppl-public/ppl.nn
7)aXorbits Inference:https://github.com/xorbitsai/inference
8)bitsandbytes:https://github.com/bitsandbytes-foundation/bitsandbytes
9)ctransformers:https://github.com/marella/ctransformers
10)MLC-LLM:https://github.com/mlc-ai/mlc-llm
11)DeepSpeed-MII:https://github.com/microsoft/DeepSpeed-MII
12)vLLM:https://github.com/vllm-pro ject/vllm
13)LMDeploy:https://github.com/InternLM/lmdeploy
14)LightLLM:https://github.com/ModelTC/lightllm
15)QServe:https://github.com/mit-han-lab/qserve
16)llama.cpp:https://github.com/ggerganov/llama.cpp
17)llama2.c:https://github.com/karpathy/llama2.c
18)inferflow:https://github.com/inferflow/inferflow
19)ScaleLLM:https://github.com/vectorch-ai/ScaleLLM
20)SGLang:https://github.com/sgl-pro ject/sglang
21)gpt-fast:gpt-fast:https://github.com/pytorch-labs/gpt-fast
22)FastChat:https://github.com/lm-sys/FastChat
23)OpenLLM:https://github.com/bentoml/OpenLLM
3、即用算法
随着LLMs量化算法的出现,一些典型的方法已经被大多数框架集成,而有些方法可能是在特定框架上最初开发和发布的。我们在表2中列出了每个主流框架中最即用的算法。大多数框架都包含了一些方法,如GPTQ、AWQ、SmoothQuant等。
这些方法有几个共同的优点:量化后高精度和高效性能、能够无缝集成到现有的实现流程中,以及用户友好性。
此外,一些算法被几个框架支持。例如,LLM.int8()被bitsandbytes很好地支持,它允许直接从HuggingFace Hub存储和加载8位权重,并将线性层中的权重量化为8位。
FP6-LLM被集成在DeepSpeed-FastGen24中,以实现6位浮点权重量化的运行时量化。
它通过统一的配置选项,允许6位权重LLMs的高效量化和反量化。值得注意的是,Transformers和QServe集成了大多数算法,并提供了全面的用户手册和详细的例子,使深度学习研究人员和开发人员能够快速开始。
参考文献
1、https://arxiv.org/pdf/2404.03868v2
2、https://arxiv.org/abs/2409.16694

















 2774
2774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









