







人脸检测与初始化
人脸跟踪方法:假设图像中所找到的面部特征与当前的估计比较接近。
存在问题:如何使用视频第一帧来初始化模型。
解决方法:最简单的是使用opencv内置的级联检测器来搜索人脸,但是模型的检测区域位置将取决于对所跟踪的面部特征的选择。一种基于数据驱动模式的简单方案是,学习人脸检测区域与人脸特征的几何关系。
实现:定义一个face_detector类
class face_detector //face detector for initialsation
{
public:
string detector_fname; //file containing cascade classifier
Vec3f detector_offset; //offset from center of dectection
Mat reference; //reference shape
CascadeClassifier detector; //face detector
vector<Point2f> //points for detected face in image
dectect (const Mat &im, //image containing face
const float scaleFactor = 1.1, //scale increment
const int minNeighbours = 2, //minimum neighbourhood size
const Size minSize = Size(30,30)); //minimum detection window size
void train(ft_data &data, //trining data
const string fname, //cascade detector
const Mat &ref, //reference shape
const bool visi = false, //visualise training?
const bool mirror = false, //mirror datd?
const float frac = 0.8, //fraction of points in detected rect
const float scaleFactor = 1.1, //scale increment
const int minNeight = 2, //minimum neightbourhood size
const Size minSize = Size(30,30)); //minimum detection window size
void write(FileStorage &fs) const; //file storage object to write to
void read(const FileNode &node); //file stroge node to raed from
protected:
bool //are enough points bounded?
enough_bounded_points(const Mat &pts, //points to evaluate
const Rect R, //bounding retctangle
const float frac); //fraction of points bounded
Point2f //center of mass
center_of_mass(const Mat &pts); //[x1;y1;...;xn;yn]
float //scaling from reference to pts
calc_scale(const Mat &pts); //[x1;y1;...;xn;yn]
};detector_fname:保存用于级联分类的文件名;
detect_offset:偏移量集合,保存图像的检测区域到人脸位置和尺度的偏移量;
reference:参考形状;
detector:保存着人脸检测器;
detect函数是人脸跟踪的主要函数,该函数将一幅图像作为输入,该函数返回对图像中面部特征位置的粗略估计。具体实现:
(1) 彩色图像转化成灰度图像,并进行直方图均衡化
(2) 利用Opencv的级联分类器检测人脸位置
(3) 根据人脸外界矩形,结合detector_offset和参考形状模型,重新计算标注点的坐标
vector<Point2f> face_detector::dectect(const Mat &im, const float scaleFactor /* = 1.1 */, const int minNeighbours /* = 2 */, const Size minSize /* = Size */)
{
//convert image to grayscale
Mat gray;
if(im.channels() == 1) gray = im;
else cvtColor(im, gray, CV_RGB2GRAY);
//face dectected
vector<Rect> faces; Mat eqIm; equalizeHist(gray, eqIm);
//跟踪图像中最明显的人脸
detector.detectMultiScale(eqIm, faces,scaleFactor,minNeighbours, CV_HAAR_FIND_BIGGEST_OBJECT, minSize);
//根据人脸检测方框来将参考形状放到图像中
Rect R = faces[0]; //人脸外接矩形
Vec3f scale = detector_offset * R.width;
int n = reference.rows / 2; vector<Point2f> p(n);
for (int i = 0; i < n ; i++)
{
//scale[2]:缩放比例
p[i].x = scale[2]*reference.at<float>(2*i) + R.x + 0.5*R.width + scale[0];
p[i].y = scale[2]*reference.at<float>(2*i + 1) + R.y + 0.5*R.height + scale[1];
}
return p;
}detect_ofdset:由三部分构成:
偏移量(x,y):表示人脸中心到人脸检测方框的距离;
尺度因子:表示为了最好的适应图像中的人脸,调整参考形状大小的比例。
这三部分都是检测方框宽度的线性函数。
问题:检测方框宽度与detect_ofdset变量之间的线性关系如何实现?
解决:加载训练数据到内存并分配参考形状后,使用train函数从标注数据中学习。
具体实现:
训练过程:每幅图首先利用opencv级联分离检索人脸位置,然后在样本图像上标出标注点。接下来判断矩形内标注点的数量是否合理,最后计算我们的偏移量detector_offset。
void face_detector::train(ft_data &data, const string fname, const Mat &ref, const bool visi /* = false */, const bool mirror /* = false */, const float frac /* = 0.8 */, const float scaleFactor /* = 1.1 */, const int minNeighbours /* = 2 */, const Size minSize /* = Size */)
{
char names[20] = {0};
//载入级联分配器
detector.load(fname.c_str());
detector_fname = fname;
reference = ref.clone();
vector<float>xoffset(0), yoffset(0),zoffset(0);
for (int i = 0; i < data.n_images(); i++)
{
//获取每一种训练图片
Mat im = data.get_image(i,0);
if(im.empty()) continue;
//获取训练图像对应的标注点
vector<Point2f> p = data.get_points(i,false);
int n = p.size();
Mat pt = Mat(p).reshape(1, 2*n);
vector<Rect> faces;
Mat eqIm; equalizeHist(im, eqIm); //直方图均衡
//人脸检测
detector.detectMultiScale(eqIm, faces, scaleFactor, minNeighbours,CV_HAAR_FIND_BIGGEST_OBJECT, minSize);
if(faces.size() >= 1)
{
if (visi)
{
sprintf(names,"train%d.jpg",i);
//框出人脸区域
Mat I; cvtColor(im,I,CV_GRAY2BGR);
for(int i = 0; i < n; i++) circle(I, p[i], 1, CV_RGB(0,255,0),2,CV_AA);
rectangle(I,faces[0].tl(), faces[0].br(), CV_RGB(255,0,0), 3);
imshow("face detector training", I);
waitKey(10);
imwrite(names,I);
}
//检查检测结果,确保是否有足够多的标注点
if (this->enough_bounded_points(pt, faces[0], frac))
{
Point2f center = this->center_of_mass(pt);
float w = faces[0].width;
xoffset.push_back((center.x - (faces[0].x + 0.5 * faces[0].width)) / w);
yoffset.push_back((center.y - (faces[0].y + 0.5 * faces[0].height))/w);
zoffset.push_back(this->calc_scale(pt) / w);
}
}
if (mirror)
{
im = data.get_image(i,1);
if(im.empty()) continue;
p = data.get_points(i,true); pt = Mat(p).reshape(1, 2*n);
equalizeHist(im, eqIm);
detector.detectMultiScale(eqIm, faces, scaleFactor, minNeighbours,CV_HAAR_FIND_BIGGEST_OBJECT,minSize);
if (faces.size() >= 1)
{
if(visi)
{
Mat I; cvtColor(im, I,CV_GRAY2BGR);
for (int i = 0; i < n; i++)
circle(I, p[i], 1, CV_RGB(0,255,0), 2, CV_AA);
rectangle(I, faces[0].tl(), faces[0].br(), CV_RGB(255,0,0),3);
imshow("face detector training",I);
waitKey(10);
}
//check ifenough points are in detected rectangle
if (this->enough_bounded_points(pt, faces[0], frac))
{
Point2f center = this->center_of_mass(pt);
float w = faces[0].width;
xoffset.push_back((center.x - (faces[0].x + 0.5 * faces[0].width)) / w);
yoffset.push_back((center.y - (faces[0].y + 0.5 * faces[0].height))/w);
zoffset.push_back(this->calc_scale(pt) / w);
}
}
}
}
//chosse median value 选取集合中值
Mat X = Mat(xoffset), Xsort, Y = Mat(yoffset), Ysort, Z = Mat(zoffset), Zsort;
cv::sort(X,Xsort,CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING);
int nx = Xsort.rows;
cv::sort(Y, Ysort, CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING);
int ny = Ysort.rows;
cv::sort(Z, Zsort, CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING);
int nz = Zsort.rows;
detector_offset = Vec3f(Xsort.at<float>(nx/2), Ysort.at<float>(ny/2), Zsort.at<float>(na/2));
return;
}显示训练过程的标注结果:

获得face_detector对象
与形状模型和块模型一样,我们需要获得face_detector对象并将其保存,用于后续的跟踪系统中。
具体实现
#include "ft.h"
#include "ft_data.h"
#include "face_detector.h"
#include "shape_model.h"
#include <highgui.h>
#include <iostream>
int main()
{
float frac = 0.8;
bool mirror = false;
//load data
ft_data data = load_ft<ft_data>("annotations.xml");
shape_model smodel = load_ft<shape_model>("shape.xml");
smodel.set_identity_params();
vector<Point2f> r = smodel.calc_shape();
Mat ref = Mat(r).reshape(1, 2*r.size());
//train face detector 训练和保存人脸检测器
face_detector detector;
detector.train(data, "harrcascade_frontalface_alt.xml", ref, mirror, true, frac);
//save detector
save_ft<face_detector>("detector.xml", detector);
return 0 ;
}可视化face_detector
跟之前的每个模块的训练与可视化一样,在我们得到face_detector类的detector.xml文件后, 我们可以利用该文件来检测人脸,实现如下:
#include "ft.h"
#include "face_detector.h"
#include <highgui.h>
#include <iostream>
int main()
{
//load detector model
face_detector detector = load_ft<face_detector>("detector.xml");
//detect untial user quits
namedWindow("face detector");
Mat im = imread("test.jpg", 1);
vector <Point2f> p = detector.dectect(im);
if (p.size() > 0)
{
for (int i = 0; i < int(p.size()); i++)
{
circle(im, p[i], 1, CV_RGB(0,255,0), 2, CV_AA);
}
}
imwrite("result.jpg", im);
imshow("face detector", im);
waitKey(0);
destroyAllWindows;
return 0;
}检测效果图:

人脸跟踪
实现:将人脸特征提取的结果投影到形状模型的线性子空间(shape model),也就是最小化原始点集到其在人脸子空间最接近合理形状分布的投影点集的距离。(就是说,把通过模版匹配检测到的原始点集A投影到人脸子空间产生新的点集B,再按照某种约束规则,通过对A迭代变化,使得A’到B的距离最小)。
这么做的好处:在用融合了几何关系的人脸特征模版匹配法跟踪人脸时,即便空间噪声满足高斯近乎于高斯分布,其检测效果也“最像“人脸的形状。
跟踪实现:
#ifndef _FT_FACE_TRACKER_HPP_
#define _FT_FACE_TRACKER_HPP_
#include "patch_model.hpp"
#include "shape_model.hpp"
#include "face_detector.hpp"
class fps_timer{ //frames/second timer for tracking
public:
int64 t_start; //start time
int64 t_end; //end time
float fps; //current frames/sec
int fnum; //number of frames since @t_start
fps_timer(){this->reset();} //default constructor
void increment(); //increment timer index
void reset(); //reset timer
void
display_fps(Mat &im, //image to display FPS on
Point p = Point(-1,-1)); //bottom left corner of text
};
class face_tracker_params{ //face tracking parameters
public:
vector<Size> ssize; //search region size/level
bool robust; //use robust fitting?
int itol; //maximum number of iterations to try
float ftol; //convergence tolerance
float scaleFactor; //OpenCV Cascade detector parameters
int minNeighbours; //...
Size minSize; //...
face_tracker_params(); //sets default parameter settings
void
write(FileStorage &fs) const; //file storage object to write to
void
read(const FileNode& node); //file storage node to read from
};
class face_tracker{ //face tracking class
public:
bool tracking; //are we in tracking mode?
fps_timer timer; //frames/second timer
vector<Point2f> points; //current tracked points
face_detector detector; //detector for initialisation
shape_model smodel; //shape model
patch_models pmodel; //feature detectors
face_tracker(){tracking = false;}
int //0 = failure
track(const Mat &im, //image containing face
const face_tracker_params &p = //fitting parameters
face_tracker_params()); //default tracking parameters
void
reset(){ //reset tracker
tracking = false; timer.reset();
}
void
draw(Mat &im,
const Scalar pts_color = CV_RGB(255,0,0),
const Scalar con_color = CV_RGB(0,255,0));
void
write(FileStorage &fs) const; //file storage object to write to
void
read(const FileNode& node); //file storage node to read from
protected:
vector<Point2f> //points for fitted face in image
fit(const Mat &image, //image containing face
const vector<Point2f> &init, //initial point estimates
const Size ssize = Size(21,21), //search region size
const bool robust = false, //use robust fitting?
const int itol = 10, //maximum number of iterations to try
const float ftol = 1e-3); //convergence tolerance
};
#endif
fps_timer类:计算程序运算的速度XX帧/秒,在face_tracker类中track函数调用。
face_tracker_params类:完成face_tracker中基本参数的初始化、序列化存储,包括搜索区域集合,最大迭代次数,级联分类器参数等等。
face_tracker类:人脸跟踪的核心模块,也是本次介绍的重点,包含train和track两个部分。
face_tracker::track函数,实现两种功能。当tracking标志位为fasle时,表示跟踪器进入检测模式(detectmode),为第一帧或下一帧图像初始化的人脸特征;当tracking标志位为true时,则根据上一帧人脸特征点的位置估计下一帧的人脸特征,这个操作主要由fit函数完成。跟踪算法的核心是多层次拟合(multi-level-fitting)过程。
int face_tracker::track(const Mat &im,const face_tracker_params &p)
{
//convert image to greyscale
Mat gray;
if(im.channels()==1)
gray = im;
else
cvtColor(im,gray,CV_RGB2GRAY);
//initialise,为第一帧或下一帧初始化人脸特征
if(!tracking)
points = detector.detect(gray,p.scaleFactor,p.minNeighbours,p.minSize);
if((int)points.size() != smodel.npts())
return 0;
//fit,通过迭代的方式,估计当前帧中的人脸特征点
for(int level = 0; level < int(p.ssize.size()); level++)
points = this->fit(gray,points,p.ssize[level],p.robust,p.itol,p.ftol);
//set tracking flag and increment timer
tracking = true;
timer.increment();
return 1;
}
....
vector<Point2f>face_tracker::fit(const Mat &image, const vector<Point2f> &init, const Size ssize,const bool robust,const int itol,const float ftol)
{
int n = smodel.npts();
assert((int(init.size())==n) && (pmodel.n_patches()==n));
smodel.calc_params(init); vector<Point2f> pts = smodel.calc_shape();
//find facial features in image around current estimates
vector<Point2f> peaks = pmodel.calc_peaks(image,pts,ssize);
//optimise
if(!robust){
smodel.calc_params(peaks); //compute shape model parameters
pts = smodel.calc_shape(); //update shape
}else{
Mat weight(n,1,CV_32F),weight_sort(n,1,CV_32F);
vector<Point2f> pts_old = pts;
for(int iter = 0; iter < itol; iter++){
//compute robust weight
for(int i = 0; i < n; i++)weight.fl(i) = norm(pts[i] - peaks[i]);
cv::sort(weight,weight_sort,CV_SORT_EVERY_COLUMN|CV_SORT_ASCENDING);
double var = 1.4826*weight_sort.fl(n/2); if(var < 0.1)var = 0.1;
pow(weight,2,weight); weight *= -0.5/(var*var); cv::exp(weight,weight);
//compute shape model parameters
smodel.calc_params(peaks,weight);
//update shape
pts = smodel.calc_shape();
//check for convergence
float v = 0; for(int i = 0; i < n; i++)v += norm(pts[i]-pts_old[i]);
if(v < ftol)break; else pts_old = pts;
}
}return pts;
}
face_tracker::fit函数的主要功能:给定一帧图像及上一帧人脸特征点集,在当前图像上搜索该点集附近的人脸特征,并产生新的人脸特征点集。
参数:
image:当前帧灰度图像
init:上一帧人脸特征点集(几何位置)
ssize:搜索区域大小
robust:标志位,决定是否采用robustmodel fitting流程,应对人脸特征的孤立点
itol:robust modelfitting迭代上限
ftol:迭代收敛判断阈值
返回值:
pts:在给定的搜索区域大小后,当前帧中人脸特征位置点集
训练与可视化
跟踪实现:
#include "ft.hpp"
#include "face_tracker.hpp"
#include <opencv2/highgui/highgui.hpp>
#include <iostream>
#define fl at<float>
void draw_string(Mat img, //image to draw on
const string text) //text to draw
{
Size size = getTextSize(text,FONT_HERSHEY_COMPLEX,0.6f,1,NULL);
putText(img,text,Point(0,size.height),FONT_HERSHEY_COMPLEX,0.6f,
Scalar::all(0),1,CV_AA);
putText(img,text,Point(1,size.height+1),FONT_HERSHEY_COMPLEX,0.6f,
Scalar::all(255),1,CV_AA);
}
int main(int argc,char** argv)
{
//load detector model
Mat im;
face_tracker tracker = load_ft<face_tracker>("tracker.xml");
//create tracker parameters
face_tracker_params p;
p.robust = false;
p.ssize.resize(3);
p.ssize[0] = Size(21,21);
p.ssize[1] = Size(11,11);
p.ssize[2] = Size(5,5);
//open video stream
VideoCapture cam;
namedWindow("face tracker");
cam.open("test.avi");
if(!cam.isOpened()){
cout << "Failed opening video file." << endl;
return 0;
}
//detect until user quits
while(cam.get(CV_CAP_PROP_POS_AVI_RATIO) < 0.999999){
cam >> im;
if(tracker.track(im,p))
tracker.draw(im);
draw_string(im,"d - redetection");
tracker.timer.display_fps(im,Point(1,im.rows-1));
imshow("face tracker",im);
int c = waitKey(10);
if(c == 'q')
break;
else if(c == 'd')
tracker.reset();
}
destroyWindow("face tracker");
cam.release();
return 0;
}
结果:
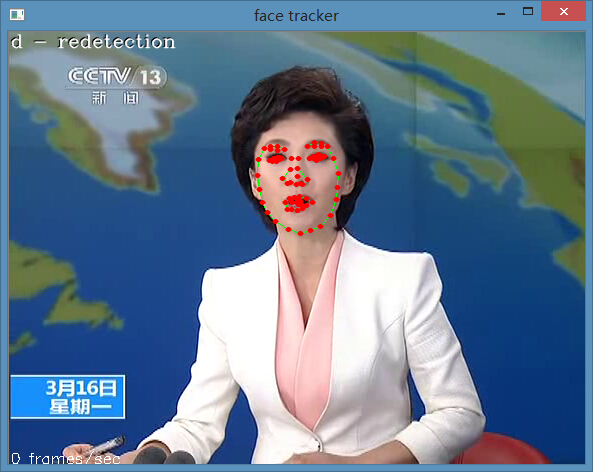
代码:http://download.csdn.net/detail/yiluoyan/8684973
reference:http://blog.csdn.net/jinshengtao/article/details/44814297















 2276
2276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









