







2006年以来,机器学习领域突破性发展,不仅依赖于云计算、Hadoop框架的大数据的并行处理能力,还依赖于算法,该算法就是深度学习。它抽象模拟了人脑神经元传递信息和链接的方式。
1.1、模拟大脑的学习和重构
从单词“easy”到“Easy”的学习过程举例,引入自动编码器(AutoEncoder)的思想。昨天的学习单词“easy”是编码,今天的“Easy”还原出来是解码。
1.1.1 灰度图像
通过28*28像素的灰度图像组成的训练集案例,每一个像素的值都作为一个输入层神经元的输入(784个),输出层也有相同的数目,且灰度值相等。
提出人脸识别的案例,第一隐层提取线段特征,第二隐层提取脸部特征,第三隐层提取全脸特征。
从输入一层层下去,每个隐层都减少若干神经元,然后再反向训练权值(这里的反向训练后面再详细介绍)。 最后得到的东西也就是几十种脸型,极大减少了特征量,这就是自编码器做的事情。
1.1.2 流行感冒
1.1.3 看看如何编解码
(1,0,0,0)->(0.948,0.025)->(0.892,0.096,0.116,0.008)
(0,1,0,0)->(0.044,0.032)->(0.102,0.848,0.004,0.108)
(0,0,1,0)->(0.958,0.966)->(0.006,0.001,0.858,0.056)
(0,0,0,1)->(0.019,0.930)->(0.001,0.001,0.136,0.884)
input_layer hidden_layer output_layer
总结:首先,利用压缩方法使输入数据降维,变成隐层的东西。然后将它还原出来,得到一个近似输入的输出值,比如(1,0,0,1)输出是(0.892,0.096,0.116,0.0008),在这个过程中自编码器 自然学习了特征,对于输出和输入的差别,可以被用作标定数据去训练隐层。
1.1.4 如何训练
有监督分类器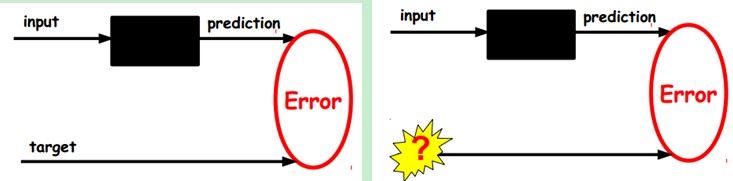
有监督分类器,无标记数据无法纠正。
第一个图,我们输入的样本是有标签的,即(input, target),这样我们根据当前输出和target(label)之间的差去改变前面各层的参数,直到收敛。但现在我们只有无标签数据,也就是右边的图。那么这个误差怎么得到呢?
编解码过程

将input输入一个编码器,就会得到一个code,这个code也就是输入的一个表示,怎么知道这个code表示的就是input呢?这里就加一个解码器,解码后的信息如果和input的输入很像(或一样),那么就相信这个code是靠谱的。所以,我们通过调整coder和decoder参数,使重构误差最小。---这时我们就得到了输入input信号的第一个表示,也就是编码code。
后面第二层和第一层的训练方法类似,将第一层输出的code当成第二层的输入信号,同样最小化重构误差,后面层如法炮制。
1.1.5 有监督微调
到这里,这个AutoEncoder还不能用来分类数据,因为它还没有学习如何去连结一个输入和一个类。它只是学会了如何去重构或者复现它的输入而已。或者说,它只是学习获得了一个可以良好代表输入的特征,这个特征可以最大程度上代表原输入信号。那么,为了实现分类,将最后一层的特征code输入到分类器,通过有标签样本,通过监督学习进行微调。
也就是说,这时候,我们需要将最后层的特征code输入到最后的分类器,通过有标签样本,通过监督学习进行微调,这也分两种,一个是只调整分类器(黑色部分):
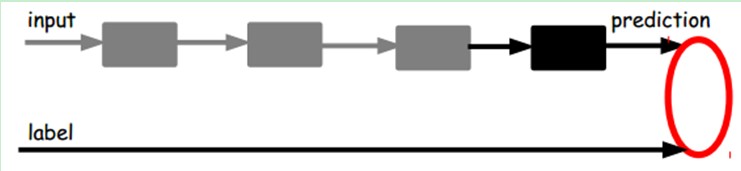
另一种:通过有标签样本,微调整个系统:(如果有足够多的数据,这个是最好的。end-to-end learning端对端学习)
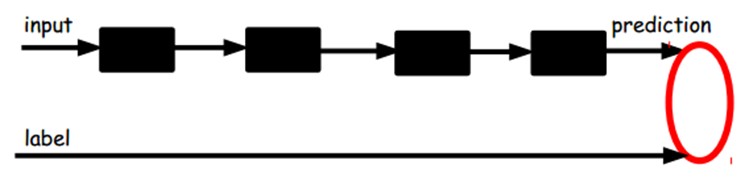
1.2 快速感知:稀疏编码(Sparsity Coding)
压缩感知:信号处理领域--第一个问题就是采样;第二个问题是重建完整信号
如何采样:还是自动编码器的例子,我们还可以继续加上一些约束条件得到新的Deep Learning方法,如:如果在AutoEncoder的基础上加上L1的Regularity限制(L1主要是约束每一层中的节点中大部分都要为0,只有少数不为0,这就是Sparse名字的来源),我们就可以得到Sparse AutoEncoder法。

如上图,其实就是限制每次得到的表达code尽量稀疏。因为稀疏的表达往往比其他的表达要有效(人脑好像也是这样的,某个输入只是刺激某些神经元,其他的大部分的神经元是受到抑制的)。
1.3 栈式自编码器

由一个多层稀疏自编码器组成的神经网络,提供了一种有效的预训练方法来初始化网络的权重,这样就得到了一个可以用来训练的复杂、多层的感知机。
1.4 解决概率分布问题:限制波尔兹曼机
1.4.1 生成模型和概率模型
1、决策函数Y=f(X)或者条件概率分布P(Y|X)
监督学习的任务就是从数据中学习一个模型(也叫分类器),应用这一模型,对给定的输入X预测相应的输出Y。这个模型的一般形式为决策函数Y=f(X)或者条件概率分布P(Y|X)。
决策函数Y=f(X):你输入一个X,它就输出一个Y,这个Y与一个阈值比较,根据比较结果判定X属于哪个类别。例如两类(w1和w2)分类问题,如果Y大于阈值,X就属于类w1,如果小于阈值就属于类w2。这样就得到了该X对应的类别了。
条件概率分布P(Y|X):你输入一个X,它通过比较它属于所有类的概率,然后输出概率最大的那个作为该X对应的类别。例如:如果P(w1|X)大于P(w2|X),那么我们就认为X是属于w1类的。
所以上面两个模型都可以实现对给定的输入X预测相应的输出Y的功能。实际上通过条件概率分布P(Y|X)进行预测也是隐含着表达成决策函数Y=f(X)的形式的。例如也是两类w1和w2,那么我们求得了P(w1|X)和P(w2|X),那么实际上判别函数就可以表示为Y= P(w1|X)/P(w2|X),如果Y大于1或者某个阈值,那么X就属于类w1,如果小于阈值就属于类w2。而同样,很神奇的一件事是,实际上决策函数Y=f(X)也是隐含着使用P(Y|X)的。因为一般决策函数Y=f(X)是通过学习算法使你的预测和训练数据之间的误差平方最小化,而贝叶斯告诉我们,虽然它没有显式的运用贝叶斯或者以某种形式计算概率,但它实际上也是在隐含的输出极大似然假设(MAP假设)。也就是说学习器的任务是在所有假设模型有相等的先验概率条件下,输出极大似然假设。
所以呢,分类器的设计就是在给定训练数据的基础上估计其概率模型P(Y|X)。如果可以估计出来,那么就可以分类了。但是一般来说,概率模型是比较难估计的。给一堆数给你,特别是数不多的时候,你一般很难找到这些数满足什么规律吧。那能否不依赖概率模型直接设计分类器呢?事实上,分类器就是一个决策函数(或决策面),如果能够从要解决的问题和训练样本出发直接求出判别函数,就不用估计概率模型了,这就是决策函数Y=f(X)的伟大使命了。例如支持向量机,我已经知道它的决策函数(分类面)是线性的了,也就是可以表示成Y=f(X)=WX+b的形式,那么我们通过训练样本来学习得到W和b的值就可以得到Y=f(X)了。还有一种更直接的分类方法,它不用事先设计分类器,而是只确定分类原则,根据已知样本(训练样本)直接对未知样本进行分类。包括近邻法,它不会在进行具体的预测之前求出概率模型P(Y|X)或者决策函数Y=f(X),而是在真正预测的时候,将X与训练数据的各类的Xi比较,和哪些比较相似,就判断它X也属于Xi对应的类。
2、生成方法和判别方法
监督学习方法又分生成方法(Generative approach)和判别方法(Discriminative approach),所学到的模型分别称为生成模型(Generative Model)和判别模型(Discriminative Model)。咱们先谈判别方法,因为它和前面说的都差不多,比较容易明白。
判别方法:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。基本思想是有限样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型。典型的判别模型包括k近邻,感知级,决策树,支持向量机等。
生成方法:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。基本思想是首先建立样本的联合概率概率密度模型P(X,Y),然后再得到后验概率P(Y|X),再利用它进行分类,就像上面说的那样。注意了哦,这里是先求出P(X,Y)才得到P(Y|X)的,然后这个过程还得先求出P(X)。P(X)就是你的训练数据的概率分布。哎,刚才说了,需要你的数据样本非常多的时候,你得到的P(X)才能很好的描述你数据真正的分布。例如你投硬币,你试了100次,得到正面的次数和你的试验次数的比可能是3/10,然后你直觉告诉你,可能不对,然后你再试了500次,哎,这次正面的次数和你的试验次数的比可能就变成4/10,这时候你半信半疑,不相信上帝还有一个手,所以你再试200000次,这时候正面的次数和你的试验次数的比(就可以当成是正面的概率了)就变成5/10了。这时候,你就觉得很靠谱了。
还有一个问题就是,在机器学习领域有个约定俗成的说法是:不要去学那些对这个任务没用的东西。例如,对于一个分类任务:对一个给定的输入x,将它划分到一个类y中。那么,如果我们用生成模型:p(x,y)=p(y|x).p(x)
那么,我们就需要去对p(x)建模,但这增加了我们的工作量,这让我们很不爽(除了上面说的那个估计得到P(X)可能不太准确外)。实际上,因为数据的稀疏性,导致我们都是被强迫地使用弱独立性假设去对p(x)建模的,所以就产生了局限性。所以我们更趋向于直观的使用判别模型去分类。
这样的方法之所以称为生成方法,是因为模型表示了给定输入X产生输出Y的生成关系。用于随机生成的观察值建模,特别是在给定某些隐藏参数情况下。典型的生成模型有:朴素贝叶斯和隐马尔科夫模型等。
3、生成模型和判别模型的优缺点
在监督学习中,两种方法各有优缺点,适合于不同条件的学习问题。
生成方法的特点:上面说到,生成方法学习联合概率密度分布P(X,Y),所以就可以从统计的角度表示数据的分布情况,能够反映同类数据本身的相似度。但它不关心到底划分各类的那个分类边界在哪。生成方法可以还原出联合概率分布P(Y|X),而判别方法不能。生成方法的学习收敛速度更快,即当样本容量增加的时候,学到的模型可以更快的收敛于真实模型,当存在隐变量时,仍可以用生成方法学习。此时判别方法就不能用。
判别方法的特点:判别方法直接学习的是决策函数Y=f(X)或者条件概率分布P(Y|X)。不能反映训练数据本身的特性。但它寻找不同类别之间的最优分类面,反映的是异类数据之间的差异。直接面对预测,往往学习的准确率更高。由于直接学习P(Y|X)或P(X),可以对数据进行各种程度上的抽象、定义特征并使用特征,因此可以简化学习问题。
4、生成模型和判别模型的联系
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
5、再形象点
例如我们有一个输入数据x,然后我们想将它分类为标签y。(迎面走过来一个人,你告诉我这个是男的还是女的)
生成模型学习联合概率分布p(x,y),而判别模型学习条件概率分布p(y|x)。
下面是个简单的例子:
例如我们有以下(x,y)形式的数据:(1,0), (1,0), (2,0), (2, 1)
那么p(x,y)是:
y=0 y=1
-----------
x=1 | 1/2 0
x=2 | 1/4 1/4
而p(y|x) 是:
y=0 y=1
-----------
x=1| 1 0
x=2| 1/2 1/2
我们为了将一个样本x分类到一个类y,最自然的做法就是条件概率分布p(y|x),这就是为什么我们对其直接求p(y|x)方法叫做判别算法。而生成算法求p(x,y),而p(x,y)可以通过贝叶斯方法转化为p(y|x),然后再用其分类。但是p(x,y)还有其他作用,例如,你可以用它去生成(x,y)对。
再假如你的任务是识别一个语音属于哪种语言。例如对面一个人走过来,和你说了一句话,你需要识别出她说的到底是汉语、英语还是法语等。那么你可以有两种方法达到这个目的:
1)、学习每一种语言,你花了大量精力把汉语、英语和法语等都学会了,我指的学会是你知道什么样的语音对应什么样的语言。然后再有人过来对你哄,你就可以知道他说的是什么语音,你就可以骂他是“米国人还是小日本了”。(呵呵,切勿将政治掺杂在技术里面)
2)、不去学习每一种语言,你只学习这些语言模型之间的差别,然后再分类。意思是指我学会了汉语和英语等语言的发音是有差别的,我学会这种差别就好了。
那么第一种方法就是生成方法,第二种方法是判别方法。
生成算法尝试去找到底这个数据是怎么生成的(产生的),然后再对一个信号进行分类。基于你的生成假设,那么那个类别最有可能产生这个信号,这个信号就属于那个类别。判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。
1.4.2 能量模型
参考:http://blog.csdn.net/zouxy09/article/details/8195017















 25万+
25万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









