









源自: AINLPer(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2025-4-2
引言
前面主要介绍了Transformer的Attention:Transformer | 一文了解:缩放、批量、多头、掩码、交叉注意力机制(Attention),但是在Transformer模型的架构中,与Attention一样重要的还有FFN(Feed-Forward Network)层,它扮演着至关重要的角色。本文将深入介绍FFN层的结构、数学原理、源码理解、在大模型中的应用等内容,旨在揭示其如何通过升维和降维操作增强模型的表达能力,以及其在Transformer中的独特作用。让你一文了解Transformer的FFN层。本文安排如下:
- FFN架构
- FFN数学表示
- FFN源码理解
- FFN层的主要作用
- 从KV键值角度理解FFN
- FFN与Attention非线性
- FFN为什么要升维4d
- 大模型FFN层的激活函数SwiGLU
FFN架构
FFN是Transformer的关键组装件之一,下图是Transformer的整体架构,包括Encoder和Decoder两个部分。其中红色标记出来的部分就是前馈神经网络(FeedforwardNeural Network,简称 FFN 或 FNN ),又称为全连接层(Fully Connected Layer)或密集层(Dense Layer)。在Transformer模型中,FFN层通常出现在编码器(Encoder)和解码器(Decoder)的注意力层之后。
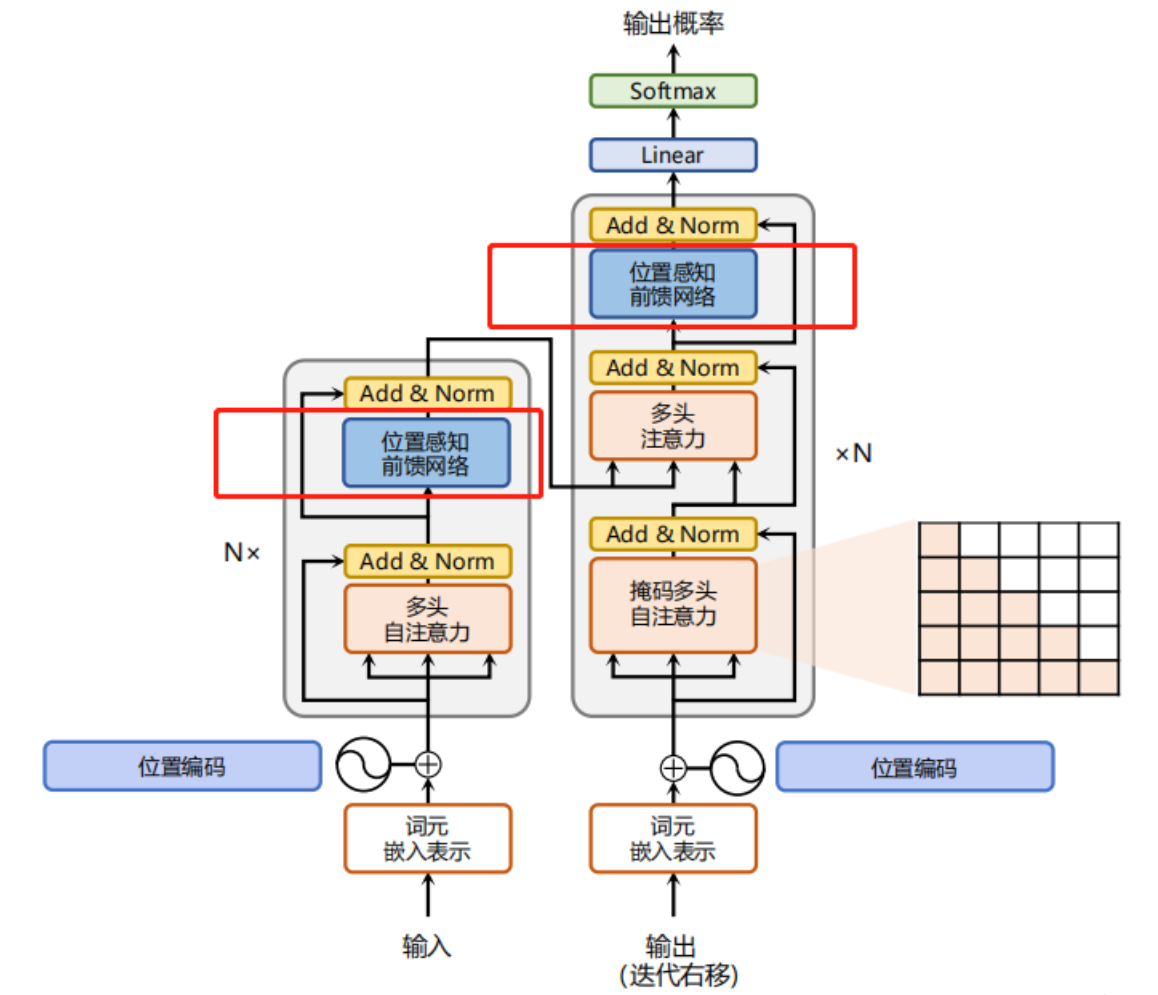
将上面红框标记出来的FFN层进行展开,其主要包括三个部分,如下图所示:
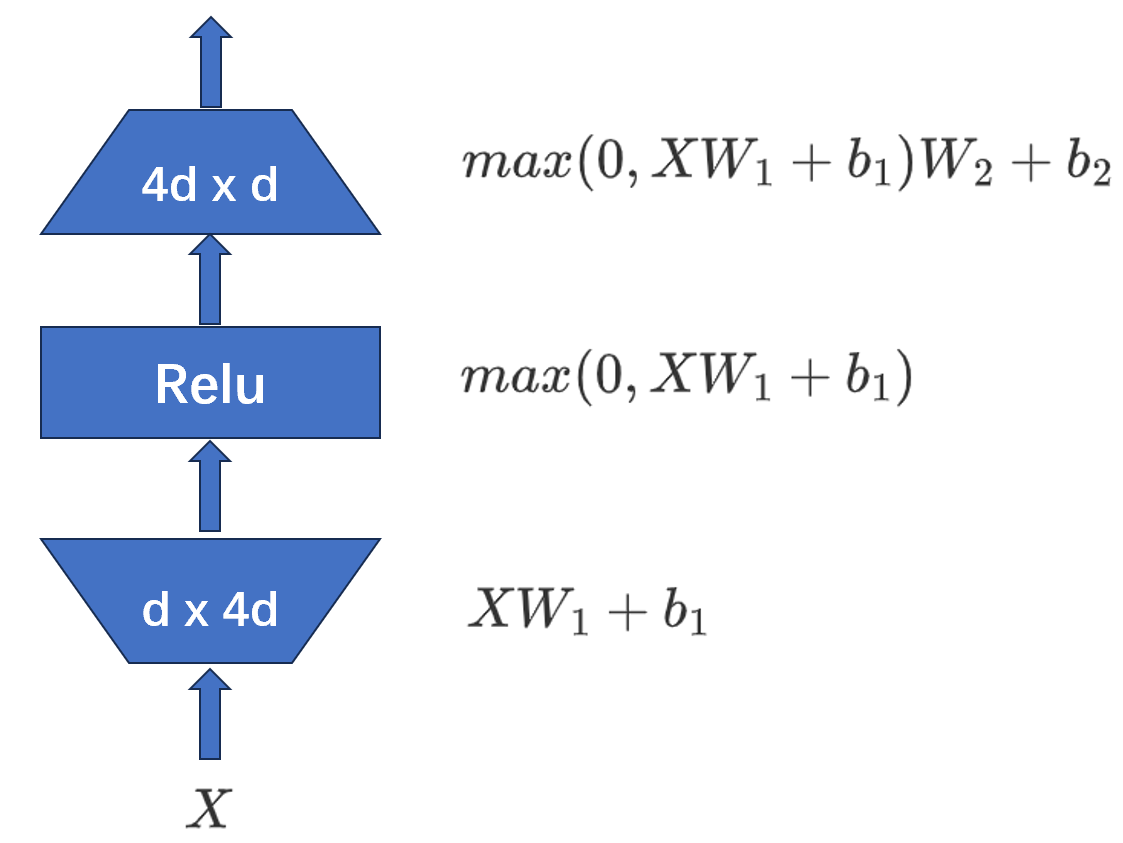
- 升维线性变换:输入首先经过一个线性变换,将输入映射到一个高维空间。这个线性变换通常由一个权重矩阵
W
1
W_1
W1和一个偏置向量
b
i
a
s
bias
bias实现(有些大模型架构也会把
bias省略掉)。 - 非线性激活函数:经过生维线性变换后,输入会通过一个激活函数,增加模型的非线性表达能力。常用的激活函数包括ReLU、Sigmoid、Tanh等,顺便说一下,当前主流大模型常用的SwiGLU。
- 降维线性变换:经过激活函数后,再进行一次线性变换,利用降维矩阵 W 2 W_2 W2将高维空间的特征映射回原始空间,得到FFN层的输出。
FFN数学表示
给定输入
X
∈
R
n
×
d
X \in \mathbb{R}^{n \times d}
X∈Rn×d (假设 batch size 为
n
n
n,隐藏维度为
d
d
d),采用ReLU激活函数,FFN 的计算方式如下:
F
F
N
(
X
)
=
m
a
x
(
0
,
X
W
1
+
b
1
)
W
2
+
b
2
FFN(X)=max(0,XW_1+b_1)W_2+b_2
FFN(X)=max(0,XW1+b1)W2+b2
其中:
- W 1 ∈ R d × 4 d W_1 \in \mathbb{R}^{d \times 4d} W1∈Rd×4d 是第一层的权重矩阵,通常将维度扩展 4 倍。
- b 1 ∈ R 4 d b_1 \in \mathbb{R}^{4d} b1∈R4d 是第一层的偏置项。
- W 2 ∈ R 4 d × d W_2 \in \mathbb{R}^{4d \times d} W2∈R4d×d 是第二层的权重矩阵,将扩展的维度降回原来的大小 d d d。
- b 2 ∈ R d b_2 \in \mathbb{R}^{d} b2∈Rd 是第二层的偏置项。
- ReLU(或 GELU) 是非线性激活函数,赋予 FFN 更强的特征表达能力。
目前很多大模型会把偏置项去掉,如果讲上面偏置项去掉,采用ReLU激活函数,FFN的计算公式如下:
F
F
N
(
X
)
=
R
e
L
U
(
X
W
1
)
W
2
FFN(X)=ReLU(XW_1)W_2
FFN(X)=ReLU(XW1)W2
FFN源码理解
下面就是使用pytorch构建的关于Transformer编码器层的源码,大家可以重点关注一下第一个全连接层和第二个全连接层。这个对应的就是上面的矩阵
W
1
W_1
W1 和
W
2
W_2
W2 ,并且在类TransformerEncoderLayer的forward函数中,第一个全连接层完成第一次升维,接着通过激活函数torch.nn.functional.relu,最后利用第二个全连接层完成最后的降维。
import torch
import torch.nn as nn
# 定义多头自注意力层
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super(MultiHeadAttention, self).__init__()
self.n_heads = n_heads # 多头注意力的头数
self.d_model = d_model # 输入维度(模型的总维度)
self.head_dim = d_model // n_heads # 每个注意力头的维度
assert self.head_dim * n_heads == d_model, "d_model必须能够被n_heads整除" # 断言,确保d_model可以被n_heads整除
# 线性变换矩阵,用于将输入向量映射到查询、键和值空间
self.wq = nn.Linear(d_model, d_model) # 查询(Query)的线性变换
self.wk = nn.Linear(d_model, d_model) # 键(Key)的线性变换
self.wv = nn.Linear(d_model, d_model) # 值(Value)的线性变换
# 最终输出的线性变换,将多头注意力结果合并回原始维度
self.fc_out = nn.Linear(d_model, d_model) # 输出的线性变换
def forward(self, query, key, value, mask):
# 将嵌入向量分成不同的头
query = query.view(query.shape[0], -1, self.n_heads, self.head_dim)
key = key.view(key.shape[0], -1, self.n_heads, self.head_dim)
value = value.view(value.shape[0], -1, self.n_heads, self.head_dim)
# 转置以获得维度 batch_size, self.n_heads, seq_len, self.head_dim
query = query.transpose(1, 2)
key = key.transpose(1, 2)
value = value.transpose(1, 2)
# 计算注意力得分
scores = torch.matmul(query, key.transpose(-2, -1)) / self.head_dim
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
attention = torch.nn.functional.softmax(scores, dim=-1)
out = torch.matmul(attention, value)
# 重塑以恢复原始输入形状
out = out.transpose(1, 2).contiguous().view(query.shape[0], -1, self.d_model)
out = self.fc_out(out)
return out
# 定义Transformer编码器层
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, dim_feedforward, dropout):
super(TransformerEncoderLayer, self).__init__()
# 多头自注意力层,接收d_model维度输入,使用n_heads个注意力头
self.self_attn = MultiHeadAttention(d_model, n_heads)
# 第一个全连接层,将d_model维度映射到dim_feedforward维度
self.linear1 = nn.Linear(d_model, dim_feedforward)
# 第二个全连接层,将dim_feedforward维度映射回d_model维度
self.linear2 = nn.Linear(dim_feedforward, d_model)
# 用于随机丢弃部分神经元,以减少过拟合
self.dropout = nn.Dropout(dropout)
# 第一个层归一化层,用于归一化第一个全连接层的输出
self.norm1 = nn.LayerNorm(d_model)
# 第二个层归一化层,用于归一化第二个全连接层的输出
self.norm2 = nn.LayerNorm(d_model)
def forward(self, src, src_mask):
# 使用多头自注意力层处理输入src,同时提供src_mask以屏蔽不需要考虑的位置
src2 = self.self_attn(src, src, src, src_mask)
# 残差连接和丢弃:将自注意力层的输出与原始输入相加,并应用丢弃
src = src + self.dropout(src2)
# 应用第一个层归一化
src = self.norm1(src)
# 经过第一个全连接层,再经过激活函数ReLU,然后进行丢弃
src2 = self.linear2(self.dropout(torch.nn.functional.relu(self.linear1(src))))
# 残差连接和丢弃:将全连接层的输出与之前的输出相加,并再次应用丢弃
src = src + self.dropout(src2)
# 应用第二个层归一化
src = self.norm2(src)
# 返回编码器层的输出
return src
# 实例化模型
vocab_size = 10000 # 词汇表大小(根据实际情况调整)
d_model = 512 # 模型的维度
n_heads = 8 # 多头自注意力的头数
num_encoder_layers = 6 # 编码器层的数量
dim_feedforward = 2048 # 全连接层的隐藏层维度
max_seq_length = 100 # 最大序列长度
dropout = 0.1 # 丢弃率
# 创建Transformer模型实例
model = Transformer(vocab_size, d_model, n_heads, num_encoder_layers, dim_feedforward, max_seq_length, dropout)
FFN层作用
从FFN具体各层的角度来看:
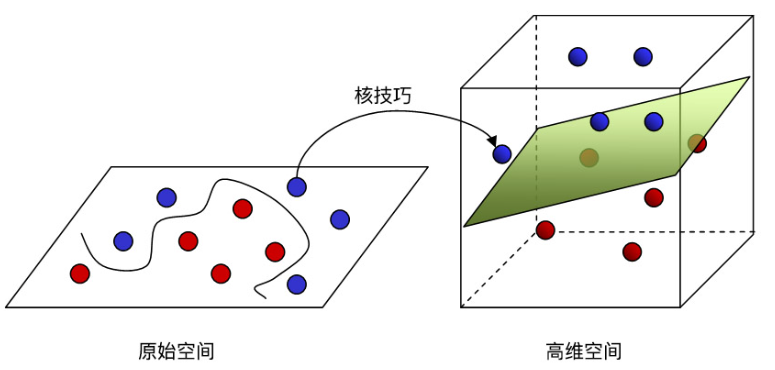
升维层将输入特征映射到更高的维度,使模型能够挖掘出更复杂的特征关系。在低维空间中,向量的表示能力有限,可能无法充分捕捉数据的复杂结构,升高向量维度可以更好地区分向量之间的关系。主要是因为高维空间提供了更多的自由度和更丰富的表达能力,使得原本在低维空间中难以区分的向量可以通过映射到高维空间来变得可区分。
下面是一个特别直观的例子,在2维空间中红蓝两色的点不好区分,但将其映射到3维空间,就能够比较容易的进行区分。尽管当前模型动不动就是几百上千维,原理是是一致的。
激活层引入非线性因素,使得模型能够学习和拟合复杂的函数关系。神经网络的基本单元是神经元,每个神经元的输出通常是输入的加权和。如果没有激活函数,无论神经网络有多少层,其最终输出仍然是输入的线性组合。线性模型的表达能力有限,无法学习复杂的非线性关系。
降维层除冗余信息,浓缩特征,保持输入输出的一致性。尽管升维操作可以捕捉更多的信息,但过高的维度会导致计算开销增大和潜在的过拟合风险。降维操作通过将高维表示映射回较低维空间,有效地控制了模型的复杂度和计算成本,同时确保了 FFN 的输出与输入维度一致,便于后续层的处理和连接。
从整体FFN层的结构来看:
-
1、维度扩展和特征抽取:第一层全连接 W 1 W_1 W1 将维度从 d d d 扩展到 4 d 4d 4d,相当于增加了模型的容量,使得更多的信息可以在更高维度进行处理。第二层 W 2 W_2 W2 再次将维度降回 d d d,这样不会增加参数量过多,同时保证了信息的压缩和提取。(有好奇的小伙伴可能会好奇:这里可以为什么会是 4 d 4d 4d 呢?这个后面解释。)
-
2、引入非线性变换:Transformer 的 注意力(Attention)机制本质上是线性的,它本质上是计算不同 token 之间的加权和。FFN 提供了非线性变换,使模型能够学习更复杂的特征和关系,弥补了自注意力的局限性。
-
3、位置独立处理:模型位置编码一般都会放在Attention阶段进行,例如:Transformer架构通过正余弦添加位置编码,Bert模型通过可学习的方式添加位置编码,当前生成式的大模型通过RoPE添加位置编码等(具体可以参考这篇文章:2万字长文!一文了解Attention,从MHA到DeepSeek MLA,大量图解,非常详细!
)。回到FFN层,它不会引入额外的位置信息,而是对每个位置的特征向量进行独立的非线性变换,这使得 FFN 层能够专注于对每个位置的特征进行增强,而不会干扰到其他位置的信息。这与自注意力机制的全局交互性形成了互补,使得模型能够同时捕捉局部特征和全局依赖关系。 -
4、下游任务匹配:Transformer 模型的设计目标之一是能够灵活地应用于各种任务,包括但不限于自然语言处理、计算机视觉等。FFN 层的结构相对简单,但通过调整其参数(如隐藏层的维度、激活函数等),可以很容易地改变模型的表达能力和复杂度。这种灵活性使得 Transformer 模型能够适应不同的任务需求。
从键值对(KV)理解FFN
根据前面的介绍,FFN主要是存储训练数据的知识,这个不仅符合我们得直觉,也符合目前主流学术得研究方向。例如:MoE架构中的专家模型、通用模型的实现都是通过FFN层实现的(不了解MoE可以参一下这篇文章:一文带你详细了解:大模型MoE架构(含DeepSeek MoE详解)
)、大模型的Adapter微调,添加Adapter就是由FFN层层组成、大模型LoRA微调的时候,在旁侧添加的A、B矩阵其实也是FFN层。
为了更好的让大家理解FFN层,一篇文章[Transformer Feed-Forward Layers Are Key-Value Memories]提出了一个特别有趣的观点:FFN的知识是以KV Memory的形式存储在FFN中,其中每个 k i k_i ki 存储着从训练数据中学习到的某些特征,对应的 v i v_i vi存储着在该特征下预测下一个词的概率分布。
根据之前对Attention的介绍:(Transformer | 一文了解:缩放、批量、多头、掩码、交叉注意力机制(Attention)
,Attention的基本公式为:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
\text{Attention}(Q, K, V) = \text{softmax} \left(\frac{QK^T}{\sqrt{d_k}}\right) V
Attention(Q,K,V)=softmax(dkQKT)V
对比FFN的计算公式:
F
F
N
(
X
)
=
R
e
L
U
(
X
W
1
)
W
2
FFN(X)=ReLU(XW_1)W_2
FFN(X)=ReLU(XW1)W2
如果将FFN的
W
1
W_1
W1矩阵看作
K
K
K,
W
2
W_2
W2矩阵看作
V
V
V,softmax可以看作是激活函数ReLU,对比可以看一下下图。
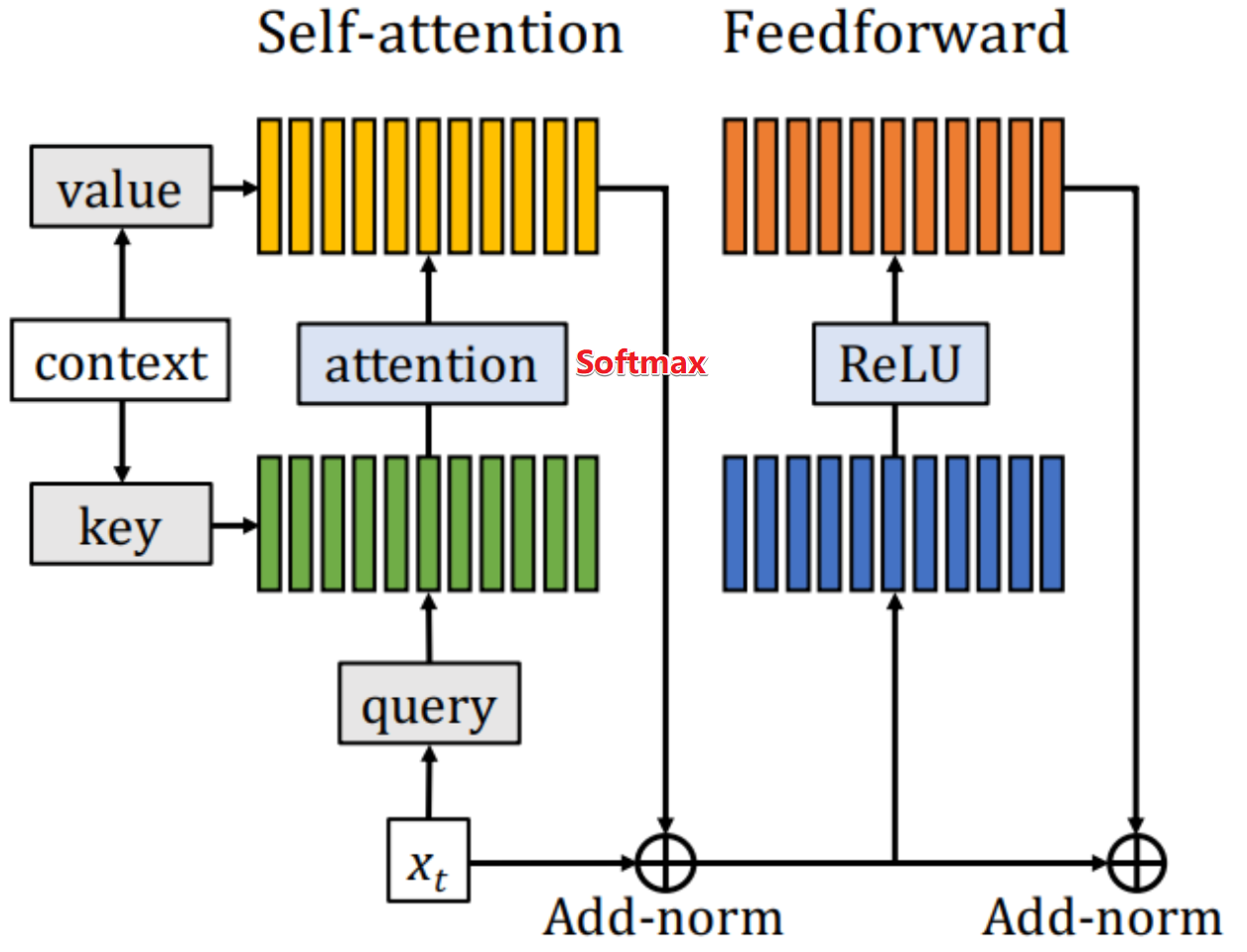
那么FFN的计算公式可以写成下式。可以发现,这个过程其实就类似于QKV点乘注意力的计算。
F
F
N
(
x
)
=
f
(
x
K
T
)
V
FFN(x)= f(xK^T) V
FFN(x)=f(xKT)V
那么,输入
x
x
x与每个
k
i
k_i
ki点乘得到系数
m
i
m_i
mi(memory coefficient),然后与对应的
v
i
v_i
vi加权得到FFN的输出。这个过程类似于QKV点乘注意力的计算。两者不同的地方在于:
- Attention的计算是context-dependent的,查表操作的qkv都来自于数据的表示,是变长的,FFN的KV是context-independent的,q来自于数据表示,kv则分别来自于两个可学习参数矩阵中的向量,是固定的
- Attention中的激活函数是normalized性质的softmax,而FFN是unnormalized的激活函数,如ReLU
文中作者通过对比Attention,做了一些FFN的知识存储和内部信息流动分析, 实验表明FFN 确实将一些 pattern 或者知识记忆和存储起来了。从这个角度来说,Attention 是对短期的信息进行提取,而 FFN 则对整个训练样本进行信息提取和记忆。**这也就能解释为什么一个有限的窗口甚至对语料进行了暴力截断,模型也能记住语料库中的信息。**感兴趣的小伙伴可以读一下论文原文。
FFN与Attention非线性
FFN前面介绍说,FFN主要作用之一是引入非线性变换,目的是让模型能够学习和拟合复杂的函数关系,来提高提高模型表达能力。但是通过上一节与Attention的对比,可以发现A**ttention也会通过softmax引入非线性变换。那么问题来了:FFN为什么还要引入非线性变换呢?**这个问题其实在我之前的面试中也问过很多面试者,如果对FFN不是很熟悉的人听到这个也会比较懵。
其实,这里有一个小陷阱,用来了解一下候选人对 Transformers 细节的把握情况。这个陷阱其实会引出另外一个问题:attention 是线性运算的还是非线性运算的?
全局来看,对于输入 x x x来说是非线性运算。因为仔细看一下 Attention 的计算公式,其中确实有一个针对 $q 和 和 和 k 的 s o f t m a x 的非线性运算。但是对于 的 softmax 的非线性运算。但是对于 的softmax的非线性运算。但是对于v$来说,并没有任何的非线性变换,所以每一次 Attention 的计算相当于是对 value 代表的向量进行了加权平均。
还有一个重要点就是:Attention机制中的非线性变换(如Softmax)和FFN中的非线性变换(如ReLU)是不同的。Softmax函数主要用于权重的归一化,而ReLU等激活函数则用于引入非线性,使得模型能够学习到更复杂的特征表示,这种变换可以看作是对输入特征的“重塑”,使得模型能够学习到更丰富、更复杂的特征表示。
FFN为什么升维4d?
W 2 W_2 W2 矩阵一般是 4 d × d 4d \times d 4d×d 的,那么它的秩(Rank)最高为d,根据线性代数原理,也就是说至少有3d行可以被其他行线性表出,
假设某个input x ∈ R 1 × d x \in \mathbb{R}^{1 \times d} x∈R1×d 在经过 W 1 W_1 W1 以及激活函数后的hidden state为 h ∈ R 1 × 4 d h \in \mathbb{R}^{1 \times 4d} h∈R1×4d 那么FFN的output h ⋅ W 2 h \cdot W_2 h⋅W2 可以看作是对 W 2 W_2 W2 的4d行进行一个加权求和 ∑ i = 1 4 d h i W 2 , i \sum_{i=1}^{4d} h_i W_{2,i} ∑i=14dhiW2,i,其中 h i h_i hi 代表 h h h 的第 i i i 个分量, W 2 , i W_{2,i} W2,i 代表 W 2 W_2 W2 的第 i i i 行。
由于 W 2 W_2 W2 的低秩特性,我总可以在 W 2 W_2 W2 找到 n ( n ≤ d ) n (n \leq d) n(n≤d) 个线性无关的行(假设就是前n行),从而对于任意 1 ≤ i ≤ 4 d 1 \leq i \leq 4d 1≤i≤4d, W 2 , i W_{2,i} W2,i 都可以由这n行线性表出 W 2 , i = ∑ j = 1 n c j W 2 , j W_{2,i} = \sum_{j=1}^{n} c_j W_{2,j} W2,i=∑j=1ncjW2,j,
所以上述加权求和总可以进行改写: ∑ i = 1 4 d h i W 2 , i = ∑ i = 1 n k i W 2 , i \sum_{i=1}^{4d} h_i W_{2,i} = \sum_{i=1}^{n} k_i W_{2,i} ∑i=14dhiW2,i=∑i=1nkiW2,i,那么 W 2 W_2 W2 矩阵只需要这n行即可,模型只需要学习到如何通过 W 1 W_1 W1 和激活函数来得到“新的” h ′ ∈ R 1 × n = { k 1 , k 2 , … , k n } h' \in \mathbb{R}^{1 \times n} = \{k_1, k_2, \ldots, k_n\} h′∈R1×n={k1,k2,…,kn},那么这么看完全不需要现在的FFN中先升维再降维的操作,所以为什么降低FFN中矩阵的维度实践中往往效果会变差呢?
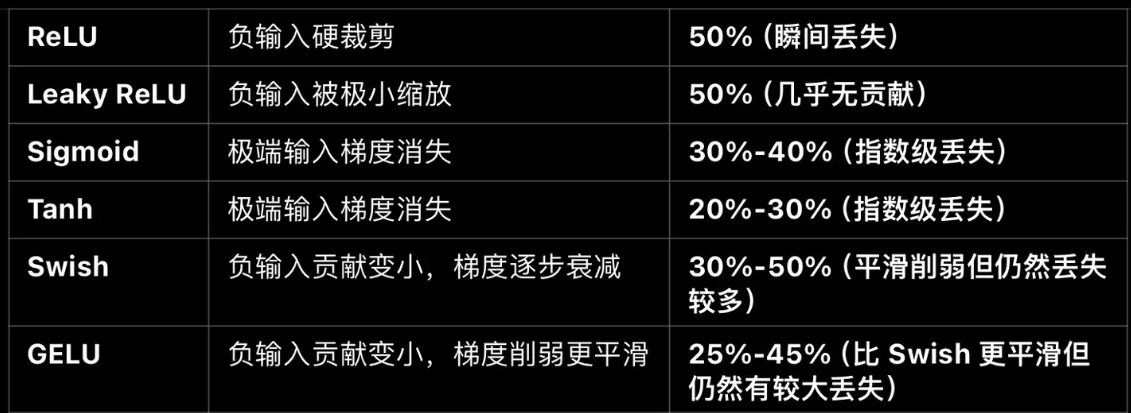
这个问题大部分人回答会说升维是为了投影到高维以增强信息的分离能力,再降维是回到原空间对齐下一步计算维度。而之所以选择4倍是经验性的,它在计算成本、参数规模、表达能力之间达到了较好的平衡。这样的回答其实并没有抓住事情的本质。其实升维的根本原因是非线性激活函数,它会导致50%左右的信息丢失,而在使用激活函数前升维是为了补偿这个损失。
首先要明白激活函数本质是通过“丢失”某些信息,让数据的结构变得非线性,从随机信号处理的角度来看,50% 是一个自然的最优点:
- 如果丢失过少(< 50%),神经元的非线性表达能力不足;
- 如果丢失过多(> 50%),有效信息可能不足,模型训练可能变得不稳定。
是由于FFN结构是两层全连接网络:
- 第一层(升维): W 1 W_1 W1让维度从 d d d变为¥;
- 经过ReLU(或其他激活函数)大约一半的神经元会变为0,信息丢失1/2。
- 第二层(降维): W 2 W_2 W2将 4 d 4d 4d维的结果降回 d d d维。等效于有效信息又减少近1/2;
最终有效信息流减少到$ (1/2) * (1/2) = 1/4$。如果我们希望最终的有效信息保持与原始输入相同,必须提前升维补偿这个损失,所以自然地会选择升维4倍。
大模型FFN的SwiGLU激活函数
上面那说到了激活函数,这里顺便也介绍一下当前主流大模型在FFN层的激活函数SwiGLU。SwiGLU(Swish-Gated Linear Unit)是一种激活函数,最早由 Google DeepMind 在《Scaling Laws for Neural Language Models》中提出。它结合了 Swish 激活函数和 Gated Linear Unit(GLU)机制,相较于 ReLU 函数在大部分评测中都有不少提升,能够提高神经网络的表达能力和训练效率。两个激活函数如下图:
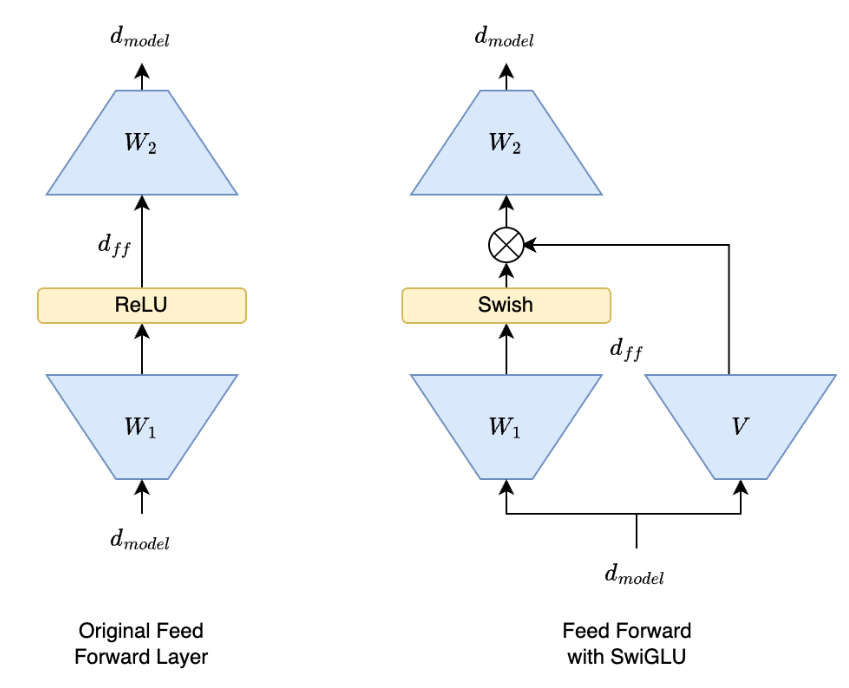
SwiGLU(Swish-Gated Linear Unit)是一种结合了 Swish 激活函数和门控线性单元(GLU)机制的激活函数,其数学表达式如下,其中X代表输入。W、V、b、c都是要学习的参数。
S
w
i
G
L
U
(
X
,
W
1
,
V
,
b
,
c
,
β
)
=
Swish
β
(
X
W
1
+
b
)
⊗
(
X
V
+
c
)
{SwiGLU}(X, W_1, V, b, c, \beta) = \text{Swish}_\beta(XW_1 + b) \otimes (XV + c)
SwiGLU(X,W1,V,b,c,β)=Swishβ(XW1+b)⊗(XV+c)
Swish 是一种平滑的非单调激活函数,定义如下:
Swish
β
(
x
)
=
x
⋅
σ
(
β
x
)
=
β
x
1
+
e
−
β
x
\text{Swish}_{\beta}(x) = x \cdot \sigma(\beta x) = \frac{\beta x}{1 + e^{-\beta x}}
Swishβ(x)=x⋅σ(βx)=1+e−βxβx
其中,
σ
(
x
)
\sigma(x)
σ(x) 是Sigmoid函数。下图给出了Swish激活函数在参数
β
\beta
β 不同取值下的形状。可以看到当
β
\beta
β 趋近于0时,Swish函数趋近于线性函数
y
=
x
y = x
y=x,当
β
\beta
β趋近于无穷大时,Swish函数趋近于ReLU函数,
β
\beta
β 取值为1时,Swish函数是光滑且非单调。在HuggingFace的Transformer库中Swish1函数使用silu函数代替。
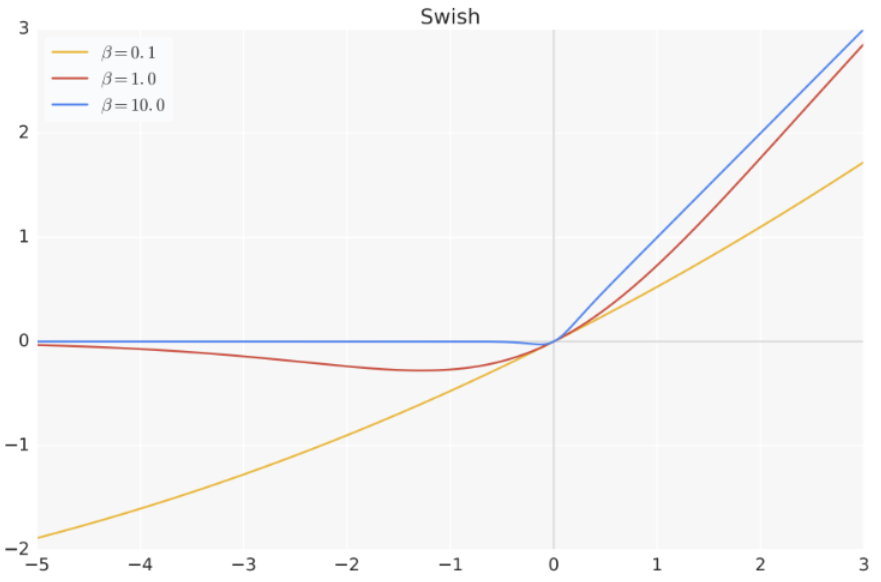
有研究表明,Swish 函数在许多应用中表现出优于 ReLU 的性能,主要优势在于其在零点附近的平滑性,有助于更好的优化和更快的收敛。
GLU 是一种神经网络层,旨在通过引入门控机制来控制信息流。其公式为:
GLU
(
x
)
=
(
X
W
+
b
)
⊗
σ
(
X
V
+
c
)
\text{GLU}(x) = (XW + b) \otimes \sigma(XV + c)
GLU(x)=(XW+b)⊗σ(XV+c)
其中,
x
x
x是输入张量,
W
W
W、
V
V
V和
b
b
b、
c
c
c 是可训练的权重和偏置项,
⊗
\otimes
⊗ 表示逐元素乘法。
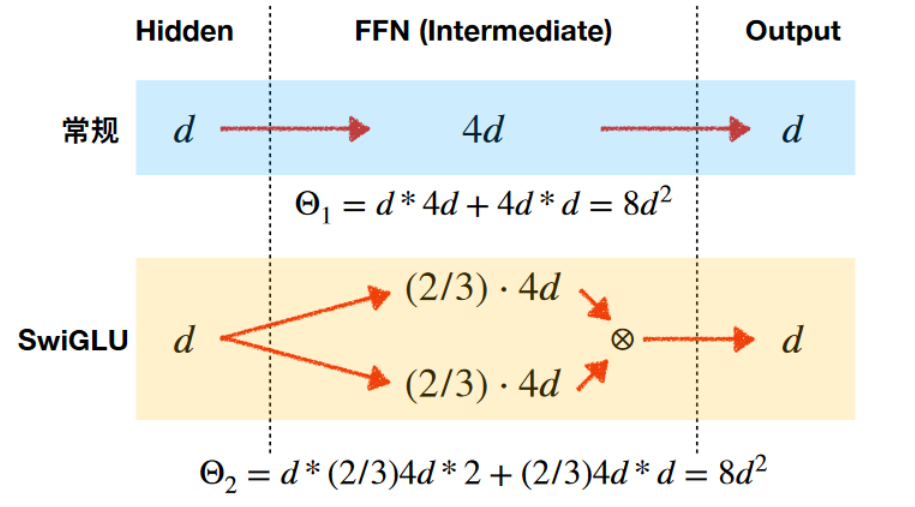
在实践中,为了保持前馈网络的参数数量不变,通常将隐藏层维度设置为
2
3
×
4
d
model
\frac{2}{3} \times 4d_{\text{model}}
32×4dmodel,以补偿额外的线性变换带来的参数增加。大家可以理解以下这个图:
import torch
import torch.nn as nn
class SwiGLU(nn.Module):
def __init__(self, input_dim, hidden_dim):
super().__init__()
self.w1 = nn.Linear(input_dim, hidden_dim)
self.w2 = nn.Linear(input_dim, hidden_dim)
def forward(self, x):
return torch.sigmoid(self.w1(x)) * self.w2(x)
# 示例
x = torch.randn(4, 10) # 4个样本,每个样本10维
swiglu = SwiGLU(10, 20)
output = swiglu(x)
print(output.shape) # 输出张量形状
讲到这里,这里也顺便列一下与SwiGLU与其它激活函数的对比,如下表所示:
| 激活函数 | 公式 | 主要特点 |
|---|---|---|
| ReLU | max ( 0 , x ) \max(0, x) max(0,x) | 简单高效,可能导致神经元死亡问题 |
| Swish | x ⋅ σ ( β x ) x \cdot \sigma(\beta x) x⋅σ(βx) | 平滑非线性,效果优于 ReLU |
| GLU | ( X W + b ) ⊗ σ ( X V + c ) (XW + b) \otimes \sigma(XV + c) (XW+b)⊗σ(XV+c) | 门控机制提升信息控制能力 |
| SwiGLU | S w i G L U ( X , W , V , b , c , β ) = Swish β ( X W + b ) ⊗ ( X V + c ) {SwiGLU}(X, W, V, b, c, \beta) = \text{Swish}_\beta(XW + b) \otimes (XV + c) SwiGLU(X,W,V,b,c,β)=Swishβ(XW+b)⊗(XV+c) | 结合 Swish 和 GLU,效果更优 |
推荐阅读
[1] 2025年的风口!| 万字长文让你了解大模型Agent
[2]Transformer | 一文了解:缩放、批量、多头、掩码、交叉注意力机制(Attention)
[3] 大模型Agent的 “USB”接口!| 一文详细了解MCP(模型上下文协议)
[4] 盘点一下!大模型Agent的花式玩法,涉及娱乐、金融、新闻、软件等各个行业
[5] 一文了解大模型Function Calling
[6] 万字长文!最全面的大模型Attention介绍,含DeepSeek MLA,含大量图示!
[7]一文带你详细了解:大模型MoE架构(含DeepSeek MoE详解)
[8] 颠覆大模型归一化!Meta | 提出动态Tanh:DyT,无归一化的 Transformer 性能更强
参考
[1]https://zhuanlan.zhihu.com/p/716276098
[2]https://www.zhihu.com/question/665731716/answer/1888856285438534538

















 1778
1778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









