









存在的问题
稀疏数据下的特征组合问题
- 类别特征经过one-hot编码转换后会导致样本特征的稀疏性,并且会得到千万级别甚至上亿级别的特征空间,导致特征空间爆炸
多项式模型:
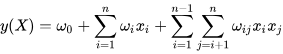
可以看出,组合的特征的参数一共有
n
(
n
−
1
)
2
\frac{n(n-1)}{2}
2n(n−1)个,并且它们都是相互独立的,而且在数据稀疏普遍存在的实际应用场景中,二次项参数的训练是很困难的,因为满足"
x
i
x_i
xi和
x
j
x_j
xj都非零"的样本是非常少的.训练样本的不足,很容易导致参数
w
i
j
w_{ij}
wij不准确(每个参数的训练都需要大量的非零样本),严重影响模型的性能;
- 而且这种多项式模型中任意两个参数都是独立的,而特征之间的组合与label之间的相关性就会有所提高;
基于的思想
矩阵分解:
任意的 N×N 实对称矩阵都有 N 个线性无关的特征向量。并且这些特征向量都可以正交单位化而得到一组正交且模为 1 的向量。故实对称矩阵 A 可被分解成:
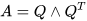
其中Q为正交矩阵,Λ为实对角矩阵。
类似地,所有二次项参数 w i j w_{ij} wij可以组成一个对称阵 W W W(为了方便说明FM的由来,对角元素可以设置为正实数),那么这个矩阵就可以分解为 W = V T V W=V^TV W=VTV,V 的第 j列( v j v_j vj )便是第 j维特征( x j x_j xj)的隐向量。换句话说,特征分量 x i x_i xi和 x j x_j xj的交叉项系数就等于 x i x_i xi对应的隐向量与 x j x_j xj对应的隐向量的内积,即每个参数 w i j = < v i , v j > w_{ij}=<v_i, v_j> wij=<vi,vj>,这就是FM模型的核心思想。
为了求出
w
i
j
w_{ij}
wij,我们需要求出特征分量
x
i
x_i
xi 的辅助向量
v
i
=
(
v
i
1
,
.
.
.
,
v
i
k
)
v_i=(v_{i1}, ..., v_{ik})
vi=(vi1,...,vik),
x
j
x_j
xj 的辅助向量
v
j
=
(
v
j
1
,
.
.
.
,
v
j
k
)
v_j=(v_{j1}, ..., v_{jk})
vj=(vj1,...,vjk) , k 表示隐向量长度(实际应用中
k
<
<
n
k<<n
k<<n),转换过程如下图所示:
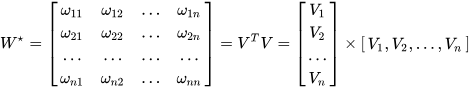
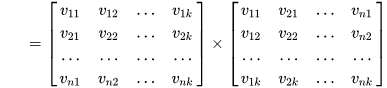
具体方法
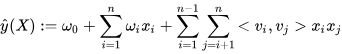
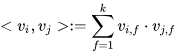
v
i
v_{i}
vi 由k维组成,k<<n,包含k个描述特征的因子,二次项参数的个数减少为
k
n
kn
kn个,远少于多项式模型的参数数量.另外,参数因子化使得
x
h
x
i
x_hx_i
xhxi 的参数和
x
i
x
j
x_ix_j
xixj的参数不再是相互独立的,因此我们可以在样本稀疏的情况下相对合理地估计FM的二次项参数。具体来说,
x
h
x
i
x_hx_i
xhxi 和
x
i
x
j
x_ix_j
xixj的系数分别为
<
v
h
,
v
i
>
<v_h, v_i>
<vh,vi>和
<
v
i
,
v
j
>
<v_i, v_j>
<vi,vj> ,它们之间有共同项
v
i
v_i
vi。也就是说,所有包含“
x
i
x_i
xi的非零组合特征”(存在某个
i
≠
j
i \neq j
i=j,使得
x
i
x
j
≠
0
x_ix_j \neq 0
xixj=0)的样本都可以用来学习隐向量
v
i
v_i
vi,这很大程度上避免了数据稀疏性造成的影响。而在多项式模型中,
w
h
i
w_{hi}
whi 和
w
j
i
w_{ji}
wji是相互独立的。
这里的 v i v_{i} vi是 x i x_i xi特征的低纬稠密表达,实际中隐向量的长度通常远小于特征维度N。在实际的CTR场景中,数据都是很稀疏的category特征,通常表示成离散的one-hot形式,这种编码方式,使得one-hot vector非常长,而且很稀疏,同时特征总量也骤然增加,达到千万级甚至亿级别都是有可能的,而实际上的category特征数目可能只有几百维。FM学到的隐向量可以看做是特征的一种embedding表示,把离散特征转化为Dense Feature,这种Dense Feature还可以后续和DNN来结合,作为DNN的输入,事实上用于DNN的CTR也是这个思路来做的。
而且隐向量可以表示之前没有出现过的交叉特征,假如在数据集中经常出现 <男,篮球> ,<女,化妆品>,但是没有出现过<男,化妆品>,<女,篮球>,这时候如果用 w i j w_{ij} wij表示<男,化妆品> 的系数,就会得到0。但是有了男特征和化妆品特征的隐向量之后,就可以通过来求解 < v v v 男, v v v 化妆品> 来求解。
时间复杂度
直观上看,FM的复杂度是
O
(
k
n
2
)
O(kn^2)
O(kn2)。但是,通过公式(3)的等式,FM的二次项可以化简,其复杂度可以优化到
O
(
k
n
)
O(kn)
O(kn) 。由此可见,FM可以在线性时间对新样本作出预测。
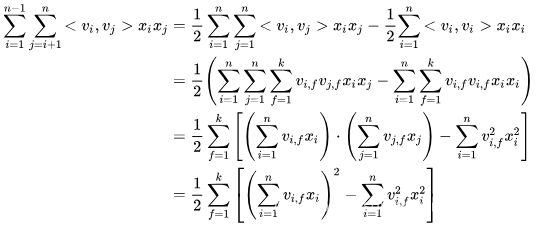
采用随机梯度下降法SGD求解参数:
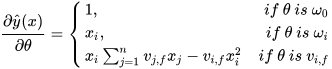
由上式可知,
v
i
f
v_{if}
vif的训练只需要样本
x
i
x_i
xi特征非0即可,适合于稀疏数据.在每次迭代中,只需计算一次所有f的
∑
j
=
1
n
v
j
f
x
j
\sum^{n}_{j=1}v_{jf}x_j
∑j=1nvjfxj,时间复杂度为
O
(
k
n
)
O(kn)
O(kn). 综上可知,FM可以在线性时间训练和预测,是一种非常高效的模型。
优点
- 参数的数量大幅度缩减,从n×(n−1)/2降低到nk
- 向量的点积可以表示原本两个毫无相关的参数之间的关系, 增大了特征之间的相关性信息
- 而稀疏数据下学习不充分的问题也能得到充分解决。比如原本的多项式回归的参数w12的学习只能依赖于特征x1和x2;而对参数⟨v1,v2⟩而言就完全不一样了,它由v1和v2组成。而对于每个向量可以通过多个交叉组合特征学习得到,比如可以由x1x2,x1x3,…学习获得,这样可供学习的非零样本就大大增加了,
参考资料
[1] : https://zhuanlan.zhihu.com/p/37963267
[2] : https://blog.csdn.net/asd136912/article/details/78318563














 1636
1636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









