








以下内容翻译自:Automating Generation of Low Precision Deep Learning Operators
随着深度学习模型变得越来越大,越来越复杂,将它们部署在低功耗手机和物联网设备上变得具有挑战性,因为它们的计算和能源预算有限。深度学习的最新趋势是使用极端量化的模型,对输入和若干位的权重进行操作,XNOR-Net、DoReFa-Net 和 HWGQ-Net 等网络稳步提高了准确性。
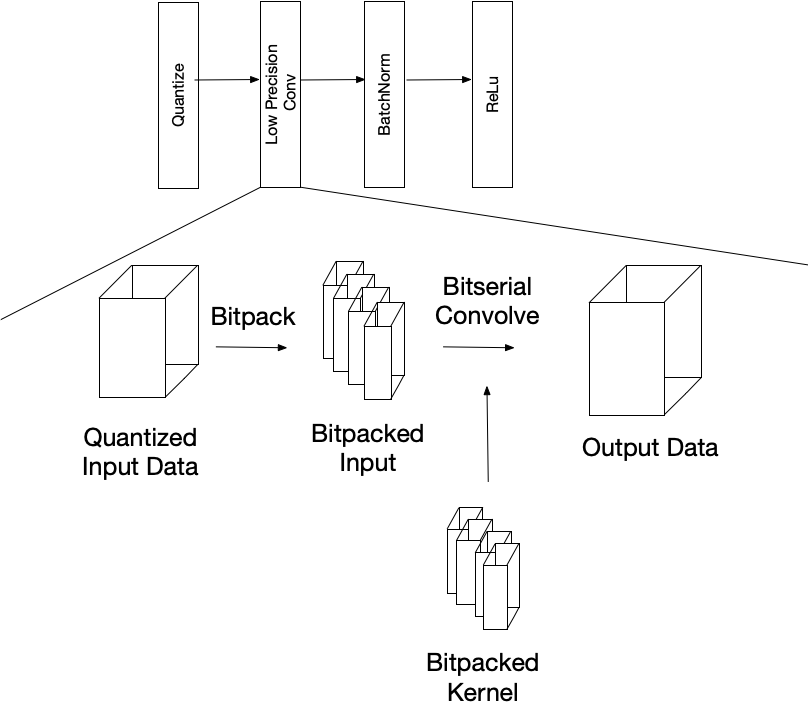
下面是一个低精度图片段的示例。低精度卷积接受量化数据并打包成适当的数据格式,以实现有效的比特串行卷积。输出具有更高的精度,应用传统的深度学习层(例如批量归一化和 ReLu)之后,重新量化并送往另一个低精度运算符。

Low precision convolution pipeline.
从理论上讲,低精度运算符比浮点运算符使用更少的运算,导致许多人相信它们可以实现巨大的加速。然而,深度学习框架通过低级别的 BLA 和 LAPACK 库利用了数十年的工程工作,这些库经过了难以置信的优化,CPU包含了加速这些任务的内在指令。在实践中,开发低阶算子并不简单,例如与8位量化或甚至浮点运算符竞争的卷积。在本文中,我们介绍了为 CPU 自动生成优化的低精度卷积的方法。我们声明低精度运算符,以便它们对有效存储的低精度输入进行计算,并描述实现参数搜索空间的调度。我们依靠 AutoTVM 快速搜索空间并找到特定卷积、精度和后端的优化参数。
Bitserial 计算背景
低精度模型的核心是位串行点积,这使得仅能使用按位运算和 popcount 来计算卷积和密集运算符。通常,通过两个向量的元素乘法计算点积,然后对所有元素求和,如下面的简单示例。如果所有数据都是二进制的,则输入向量可以打包成单个整数,通过按位与打包输入并使用 popcount 统计结果中1的数量来计算点积。
注意:根据输入数据的量化方式,可以使用 bitwise-xnor 而不是 bitwise-and。

通过首先将输入数据分成位平面,可以按这种方式计算任意精度点积。采用这种表示后,我们可以通过对 A 和 B 的位平面之间的加权二进制点积进行求和来计算点积。二进制点积的数量随着 A 和 B 的精度的乘积而增长,因此该方法仅适用于精度非常低的数据。

在 TVM 中定义运算符
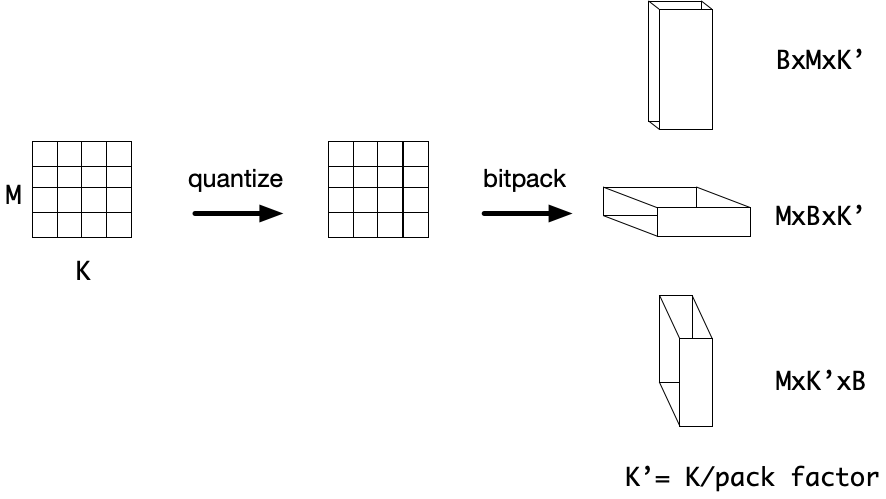
在计算之前,需要对输入数据进行比特打包,以便可以访问输入数据的位平面并将其打包到支持的数据类型中,例如 uint8或 uint32。我们提供了一个灵活的比特打包运算符,它接受任意大小的输入张量并返回一个 bitpacked 张量,位平面是哪个轴由用户指定。

一旦采用这种位压缩格式,就可以按位序列计算低精度卷积。对于此演示,该数据沿输入通道打包,位平面添加到最内层,数据打包为32位整数。
位序列卷积的计算与普通卷积相似,但位与运算(&)代替乘法,我们使用popcount来累积打包数据中的值。位平面轴成为附加的规约轴,计算输入和内核不同位平面之间的二进制点积。最后,以解包格式和更高的精度计算输出。
Input_bitpacked = bitpack(Input, activation_bits, pack_axis=3, bit_axis=4, pack_type=’uint32’)
Weights_bitpacked = bitpack(Filter, weight_bits, pack_axis=2, bit_axis=4, pack_type=’uint32’)
batch, in_height, in_width, in_channel_q, _ = Input_bitpacked.shape
kernel_h, kernel_w, _, num_filter, _ = Filter_bitpakced.shape
stride_h, stride_w = stride
pad_top, pad_left, pad_down, pad_right = get_pad_tuple(padding, (kernel_h, kernel_w))
# Computing the output shape
out_channel = num_filter
out_height = simplify((in_height - kernel_h + pad_top + pad_down) // stride_h + 1)
out_width = simplify((in_width - kernel_w + pad_left + pad_right) // stride_w + 1)
pad_before = [0, pad_top, pad_left, 0, 0]
pad_after = [0, pad_down, pad_right, 0, 0]
Input_padded = pad(Input_bitpacked, pad_before, pad_after, name="PaddedInput")
# Treat the bitplane axes like additional reduction axes
rc = tvm.reduce_axis((0, in_channel_q), name='rc')
ry = tvm.reduce_axis((0, kernel_h), name='ry')
rx = tvm.reduce_axis((0, kernel_w), name='rx')
ib = tvm.reduce_axis((0, input_bits), name='ib')
wb = tvm.reduce_axis((0, weight_bits), name='wb')
tvm.compute((batch, out_height, out_width, out_channel), lambda nn, yy, xx, ff:
tvm.sum(tvm.popcount(
Input_padded[nn, yy * stride_h + ry, xx * stride_w + rx, rc, ib] &
Weights_bitpacked[ry, rx, rc, ff, wb])) << (ib+wb))).astype(out_dtype),
axis=[rc, ry, rx, wb, ib]))
在我们的调度中,我们应用了常见的优化,如矢量化和内存平铺,以提供更好的内存位置并利用SIMD单元。其中一些优化(如平铺)需要为特定的微体系结构调整参数。我们将这些参数作为旋钮暴露给 TVM,并使用 AutoTVM 同时自动调整所有参数。
最后,我们可以利用 TVM 的 Tensorize 原语制作小的微内核来代替计算的最里面的循环,并对它们进行调度。由于编译器通常会生成次优代码,因此人们可以编写效率更高的短汇编序列。这些微内核通常利用新引入的内部指令来帮助加速深度学习工作负载,并巧妙地使用它们改进内存访问或减少所需的指令数量。
结果
Raspberry Pi
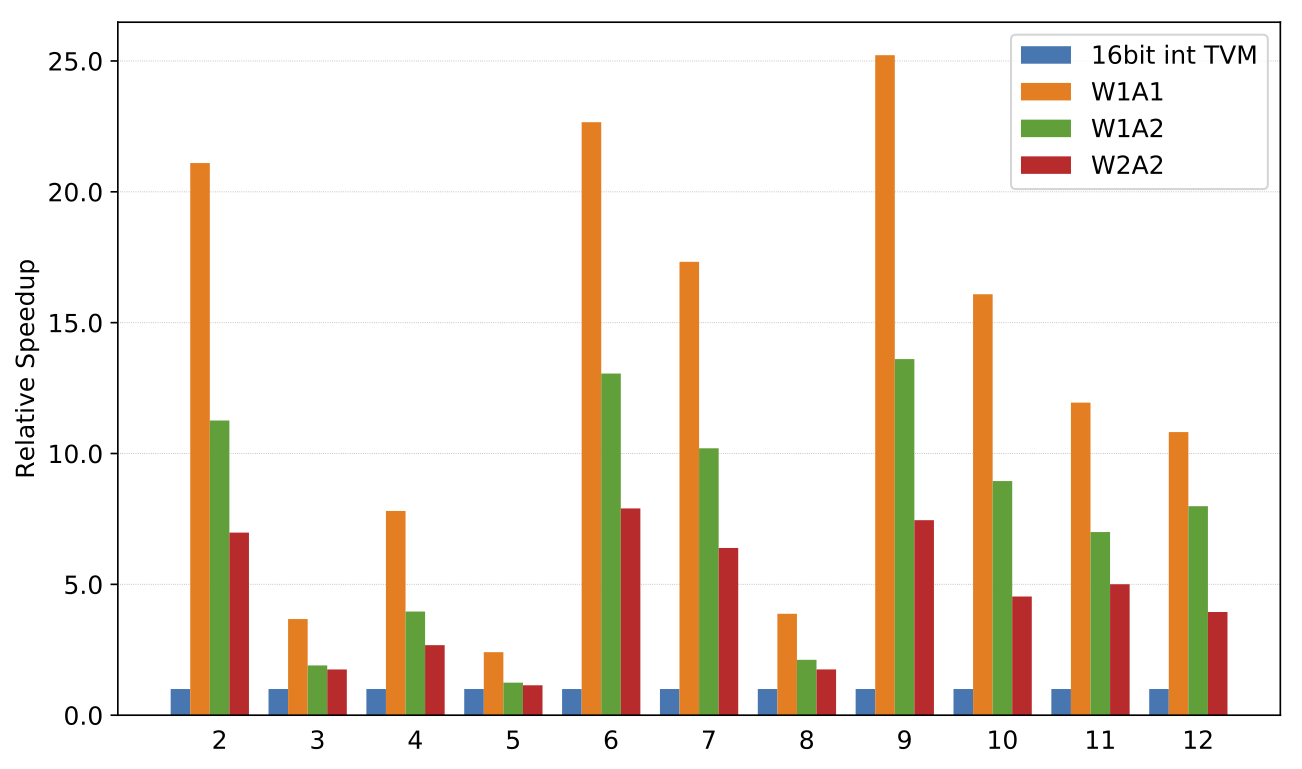
与16位整数 TVM 实现相比,Raspberry Pi 3B 上的卷积加速。工作负载是 ResNet18的卷积层。
 Speedup of low precision convolutions on a Raspberry Pi compared to 16-bit TVM implementation.
Speedup of low precision convolutions on a Raspberry Pi compared to 16-bit TVM implementation.
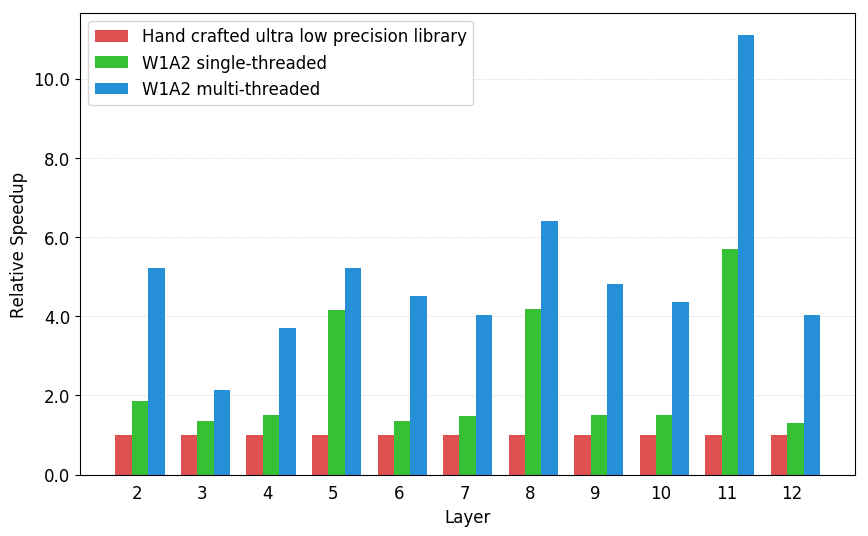
与 High performance ultra-low-precision convolutions on mobile devices 的手动优化实现相比,Raspberry Pi 3B 上的2位激活,1位权重卷积加速。工作负载是 ResNet18的卷积层。

Speedup of 2-bit weight 1-bit activation Raspberry Pi convolutions against a hand optimized implementation.
x86
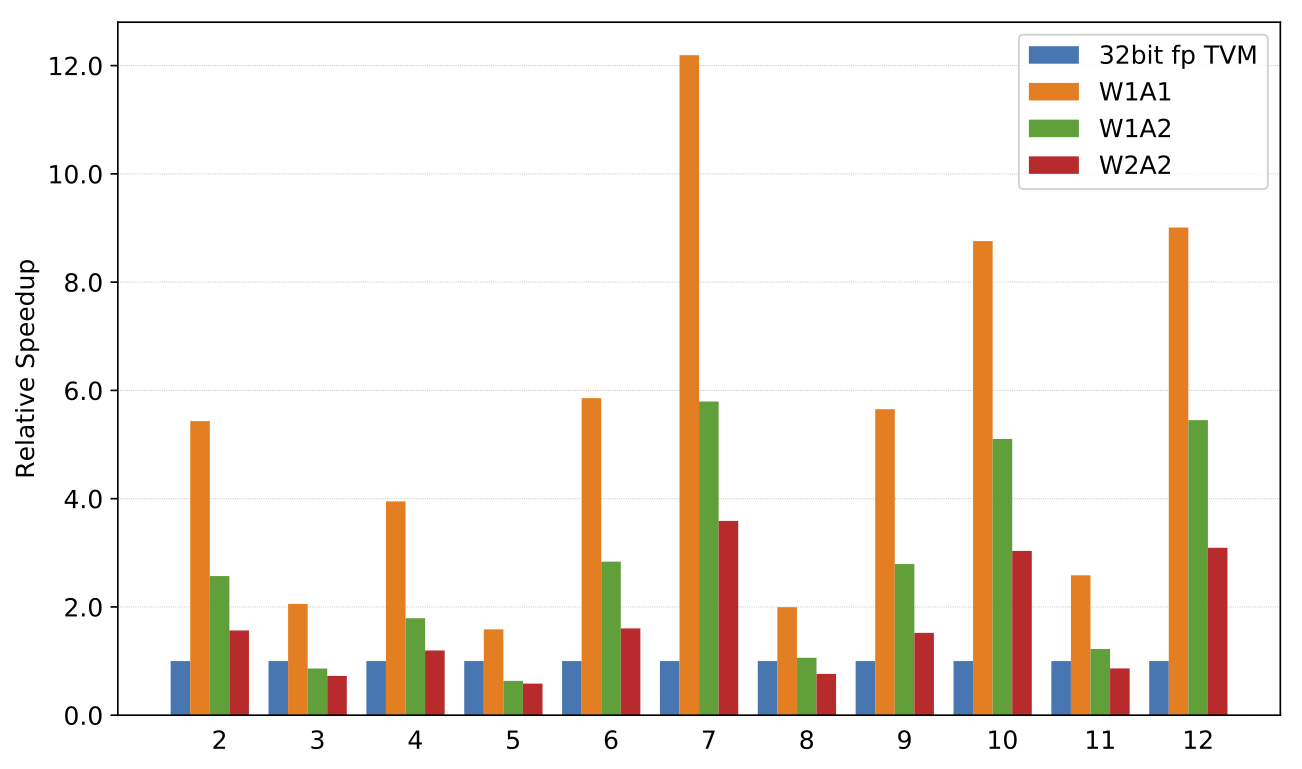
与32位浮点 TVM 实现相比,x86上的卷积加速。
注意:x86不支持此微体系结构的矢量化 popcount,因此加速比较低。
Speedup of x86 low precision convolutions compared to a 32-bit floating point TVM implementation.


















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}