







一.数据准备
SVHN是一个真实世界的街道门牌号数字识别数据集.The Street View House Numbers (SVHN) Dataset,我们可以从这里下载数据,为方便转换,我们下载train_32x32.mat和test_32x32.mat,.mat文件中包含两个变量,X是一个4D的矩阵,维度是(32,32,3,n),n是数据个数,y是label变量,接下来我们先使用一段script看一下前十张图:
import scipy.io as sio
import matplotlib.pyplot as plt
print 'Loading Matlab data.'
mat=sio.loadmat('train_32x32.mat')
data=mat['X']
label=mat['y']
for i in range(10):
plt.subplot(2,5,i+1)
plt.title(label[i][0])
plt.imshow(data[...,i])
plt.axis('off')
plt.show()

可以看出,.mat文件中的数字是已经被crop出来的单个数字,接下来使用另一个script将其转换为lmdb数据:
import numpy as np
import caffe
import lmdb
import scipy.io as sio
import random
from caffe.proto import caffe_pb2
def main():
train=sio.loadmat('train_32x32.mat')
test=sio.loadmat('test_32x32.mat')
train_data=train['X']
train_label=train['y']
test_data=test['X']
test_label=test['y']
train_data = np.swapaxes(train_data, 0, 3)
train_data = np.swapaxes(train_data, 1, 2)
train_data = np.swapaxes(train_data, 2, 3)
test_data = np.swapaxes(test_data, 0, 3)
test_data = np.swapaxes(test_data, 1, 2)
test_data = np.swapaxes(test_data, 2, 3)
N=train_label.shape[0]
map_size=train_data.nbytes*10
env=lmdb.open('svhn_train_lmdb',map_size=map_size)
txn=env.begin(write=True)
#shuffle the training data
r=list(range(N))
random.shuffle(r)
count=0
for i in r:
datum=caffe_pb2.Datum()
label=int(train_label[i][0])
if label==10:
label=0
datum=caffe.io.array_to_datum(train_data[i],label)
str_id='{:08}'.format(count)
txn.put(str_id,datum.SerializeToString())
count += 1
if count % 1000 == 0:
print('already handled with {} pictures'.format(count))
txn.commit()
txn = env.begin(write=True)
txn.commit()
env.close()
map_size = test_data.nbytes * 10
env = lmdb.open('svhn_test_lmdb', map_size=map_size)
txn = env.begin(write=True)
count = 0
for i in range(test_label.shape[0]):
datum = caffe_pb2.Datum()
label = int(test_label[i][0])
if label == 10:
label = 0
datum = caffe.io.array_to_datum(test_data[i], label)
str_id = '{:08}'.format(count)
txn.put(str_id, datum.SerializeToString())
count += 1
if count % 1000 == 0:
print('already handled with {} pictures'.format(count))
txn.commit()
txn = env.begin(write=True)
txn.commit()
env.close()
if __name__=='__main__':
main()
这样就可以得到svhn_train_lmdb和svhn_test_lmdb了
二.Data Pre-processing
SVHN比较简单,我们不做任何data augmentation操作,只通过上篇文章的script计算出其图像均值:
import caffe
import lmdb
import numpy as np
from caffe.proto import caffe_pb2
import time
lmdb_env=lmdb.open('svhn_train_lmdb')
lmdb_txn=lmdb_env.begin()
lmdb_cursor=lmdb_txn.cursor()
datum=caffe_pb2.Datum()
N=0
mean = np.zeros((1, 3, 32, 32))
beginTime = time.time()
for key,value in lmdb_cursor:
datum.ParseFromString(value)
data=caffe.io.datum_to_array(datum)
image=data.transpose(1,2,0)
mean[0,0] += image[:, :, 0]
mean[0,1] += image[:, :, 1]
mean[0,2] += image[:, :, 2]
N+=1
if N % 1000 == 0:
elapsed = time.time() - beginTime
print("Processed {} images in {:.2f} seconds. "
"{:.2f} images/second.".format(N, elapsed,
N / elapsed))
mean[0]/=N
blob = caffe.io.array_to_blobproto(mean)
with open('mean.binaryproto', 'wb') as f:
f.write(blob.SerializeToString())
lmdb_env.close()
三.实验
这里我们采用caffe自带的cifar_full模型进行训练:
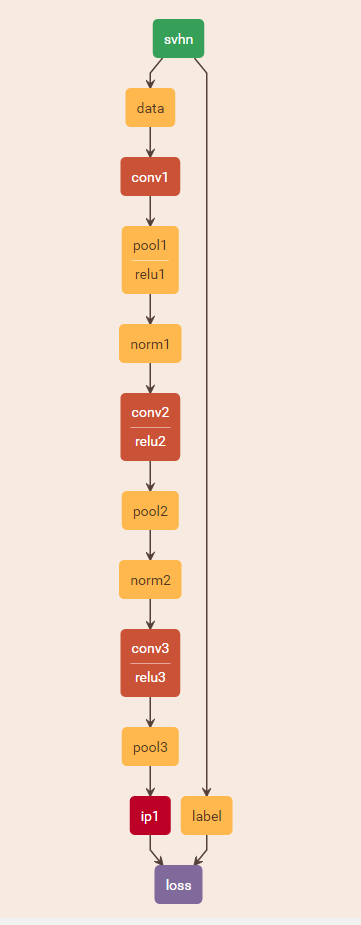
caffe train -solver=solver.prototxt -gpu 0
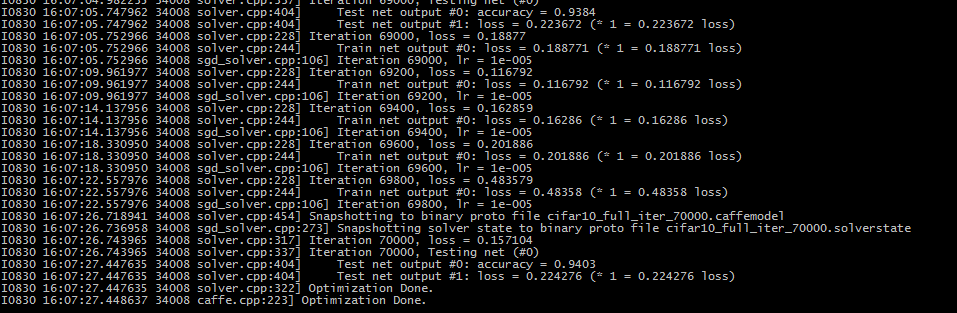
最后得到的model的准确率为94.03%,效果还是很好的
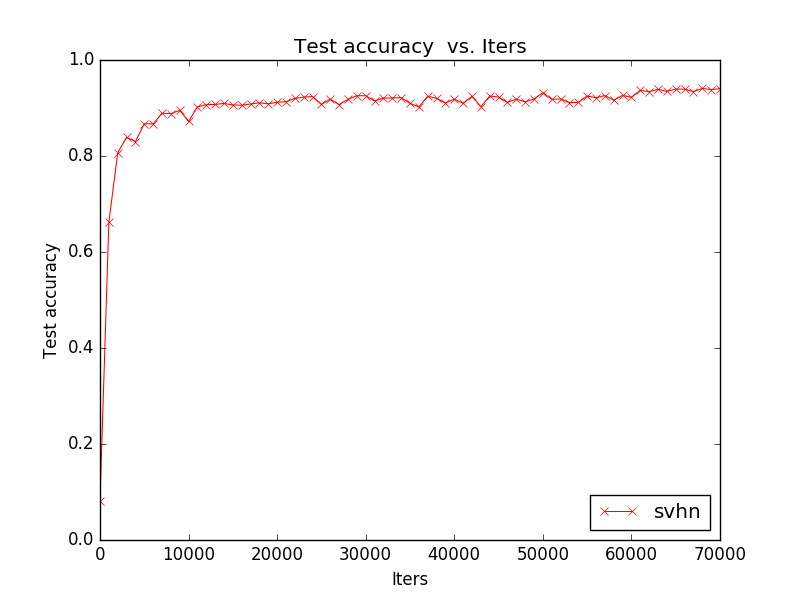
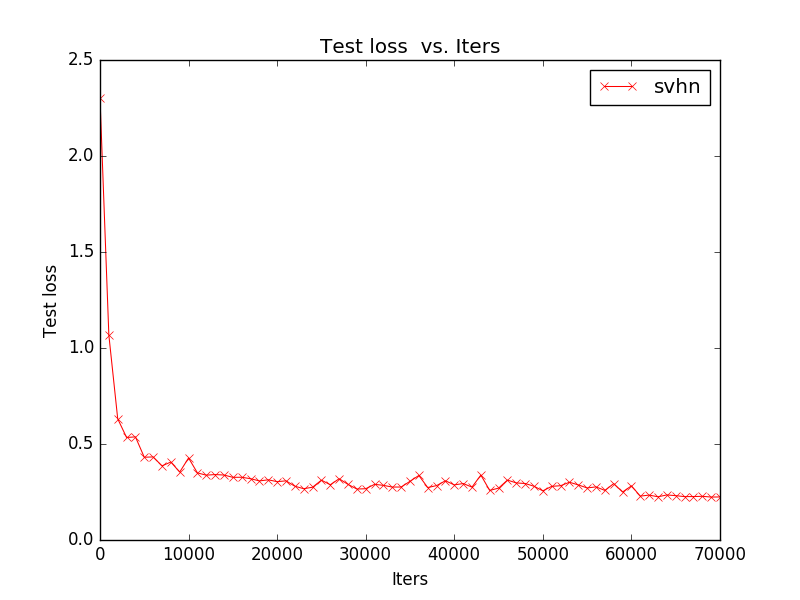
四.总结
经过这两篇文章,可以看出,对于一般的数据集,如果要在caffe中训练的话,一般有以下几步:
1.data->lmdb:将数据转换为lmdb数据,其实caffe也支持很多其他格式的输入,如IMAGEDATA,HDF5DATA,但经过实验,这些数据消耗的大量io操作会大大加剧训练的时间
2.data augmentation:常见的几种数据加强方式均在上文cifar100中有所阐释
3.data pre-processing:对于图像数据来说,最常见的数据预处理就是减去图像的均值
4.model designing:最后一步自然是设计模型,进行训练了
到这里对caffe训练过程已经是非常熟悉了,下一步让我们深入一点,看一下caffe的源码结构和实现细节,敬请期待!
PS:文中的Script和训练配置文件均在github上:https://github.com/fish145/uncommon-datasets-caffe















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









