










 本文探讨了如何通过RAFT方法训练语言模型,使其在面对开放书本考试场景时,能有效利用检索到的信息生成准确答案,同时处理干扰信息和增强推理能力。重点介绍了训练数据的构造策略和RAFT模型在提升垂直领域知识应用中的作用。
本文探讨了如何通过RAFT方法训练语言模型,使其在面对开放书本考试场景时,能有效利用检索到的信息生成准确答案,同时处理干扰信息和增强推理能力。重点介绍了训练数据的构造策略和RAFT模型在提升垂直领域知识应用中的作用。
动机

- 传统考试与开放书本考试:
- 闭卷考试:在闭卷考试中,学生不能参考任何外部资料,必须依靠自己的记忆和学习来回答问题。在语言模型的情境中,这相当于模型仅依赖于预训练阶段学习到的知识来生成回答,而不访问额外的信息。
- 开放书本考试:在开放书本考试中,学生可以查阅特定的书籍或资料来帮助回答问题。在语言模型的情境中,这相当于模型在回答问题时可以访问和引用相关的外部文档或资料。
- 类比中的两种学习方法:
- 无准备的开放书本考试:如果学生在考试前没有学习或准备,即使可以在考试时查阅资料,也可能无法有效找到和利用正确的信息来回答问题。在语言模型的情境中,这相当于模型虽然可以访问外部文档,但因为没有适当的训练,无法有效地从文档中提取和利用相关信息。
- 通过学习准备的开放书本考试:如果学生在考试前通过学习和练习(例如,通过解决类似问题和阅读相关资料)来准备考试,他们将更有可能在考试中找到并利用正确的信息。在语言模型的情境中,这相当于模型通过RAFT训练方法,学习如何有效地利用检索到的文档来生成准确的回答。
RAFT
RAFT方法的核心:
- 结合检索和生成:RAFT方法训练模型不仅要学会如何从检索到的文档中找到相关信息,还要学会如何将这些信息整合到生成的回答中。
- 处理干扰信息:在开放书本考试的类比中,干扰文档相当于考试时可能与问题无关的资料。RAFT训练模型识别并忽略这些干扰信息,只关注对回答问题有帮助的文档。
- 链式推理:RAFT还强调生成包含推理过程的回答,这类似于学生在解答问题时展示他们的思考过程和如何从资料中得出结论。
因此,提出了一种新的训练策略,通过在训练数据中引入“干扰文档”(distractor documents),训练模型忽略那些对回答问题没有帮助的文档。RAFT通过引用相关文档中的确切序列来帮助回答问题,并结合“思维链”(chain-of-thought)风格的响应来提高模型的推理能力。
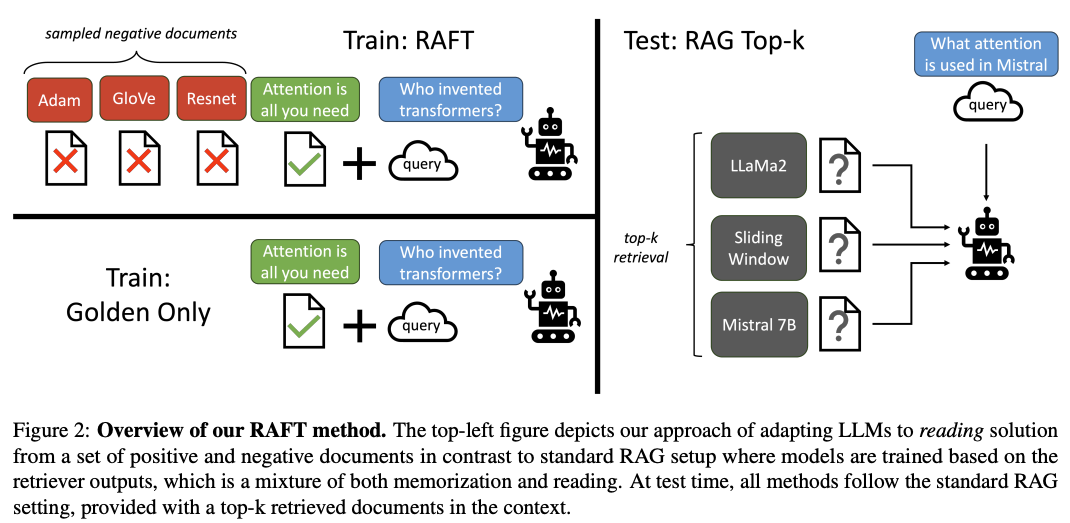
其他不赘述,总结就是微调一个垂域的LLM做RAG。主要看下训练数据的构造步骤。
训练数据构造步骤
-
文档切分成chunks;
使用
OpenAIEmbeddings将文本分成指定数量的doc块:def get_chunks( file_path: str, doctype: DocType = "pdf", chunk_size: int = 512, openai_key: str | None = None ) -> list[str]: """ Takes in a `file_path` and `doctype`, retrieves the document, breaks it down into chunks of size `chunk_size`, and returns the chunks. """ chunks = [] if doctype == "api": with open(file_path) as f: api_docs_json = json.load(f) chunks = list(api_docs_json) chunks = [str(api_doc_json) for api_doc_json in api_docs_json] for field in ["user_name", "api_name", "api_call", "api_version", "api_arguments", "functionality"]: if field not in chunks[0]: raise TypeError(f"API documentation is not in the format specified by the Gorilla API Store: Missing field `{field}`") else: if doctype == "json": with open(file_path, 'r') as f: data = json.load(f) text = data["text"] elif doctype == "pdf": text = "" with open(file_path, 'rb') as file: reader = PyPDF2.PdfReader(file) num_pages = len(reader.pages) for page_num in range(num_pages): page = reader.pages[page_num] text += page.extract_text() elif doctype == "txt": with open(file_path, 'r') as file: data = file.read() text = str(data) else: raise TypeError("Document is not one of the accepted types: api, pdf, json, txt") num_chunks = len(text) / chunk_size text_splitter = SemanticChunker(OpenAIEmbeddings(openai_api_key=OPENAPI_API_KEY), number_of_chunks=num_chunks) chunks = text_splitter.create_documents([text]) chunks = [chunk.page_content for chunk in chunks] return chunks -
使用gpt4为每个chunk生成query:
def generate_instructions_gen(chunk: Any, x: int = 5) -> list[str]: """ Generates `x` questions / use cases for `chunk`. Used when the input document is of general types `pdf`, `json`, or `txt`. """ response = client.chat.completions.create( model="gpt-4", messages=[ {"role": "system", "content": "You are a synthetic question-answer pair generator. Given a chunk of context about some topic(s), generate %s example questions a user could ask and would be answered using information from the chunk. For example, if the given context was a Wikipedia paragraph about the United States, an example question could be 'How many states are in the United States?'" % (x)}, {"role": "system", "content": "The questions should be able to be answered in a few words or less. Include only the questions in your response."}, {"role": "user", "content": str(chunk)} ] ) queries = response.choices[0].message.content.split('\n') queries = [strip_str(q) for q in queries] queries = [q for q in queries if any(c.isalpha() for c in q)] return queries -
答案生成
对于每个问题,从“oracle”文档中提取出回答问题所需的信息,并生成一个详细且准确的答案(A∗)。这个答案不仅包括最终的回答,还包括一个链式思考(Chain-of-Thought)的过程,展示如何从文档中提取信息并推导出答案。在生成答案时,使用特定的格式来明确指出答案的推理过程和引用的文档内容。例如,使用
##begin_quote##和##end_quote##标记来引用文档中的相关内容,并提供基于这些引用得出结论的详细解释。def encode_question_gen(question, chunk) -> list[str]: """ Encode multiple prompt instructions into a single string for the general case (`pdf`, `json`, or `txt`). """ prompts = [] prompt = """ Question: {question}\nContext: {context}\n Answer this question using the information given in the context above. Here is things to pay attention to: - First provide step-by-step reasoning on how to answer the question. - In the reasoning, if you need to copy paste some sentences from the context, include them in ##begin_quote## and ##end_quote##. This would mean that things outside of ##begin_quote## and ##end_quote## are not directly copy paste from the context. - End your response with final answer in the form <ANSWER>: $answer, the answer should be succint. """.format(question=question, context=str(chunk)) prompts.append({"role": "system", "content": "You are a helpful question answerer who can provide an answer given a question and relevant context."}) prompts.append({"role": "user", "content": prompt}) return prompts -
训练数据
选择query和chunk(doc):从特定领域的数据集中选择一个问题( Q Q Q)和一组相关的文档( D k D_k Dk)。这些文档包括“oracle”文档( D ∗ D∗ D∗),即包含回答问题所需信息的文档,以及“干扰”文档( D i D_i Di),即不包含相关信息的文档。
构造策略如下:
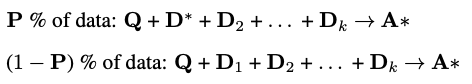
对于数据集中的一部分问题(P%),保留“oracle”文档和干扰文档一起作为训练数据。而对于剩余的问题(1-P%),则只包含干扰文档。这种设置迫使模型学习在有和没有正确文档的情况下都能生成准确的答案。
训练数据格式:

性能
-
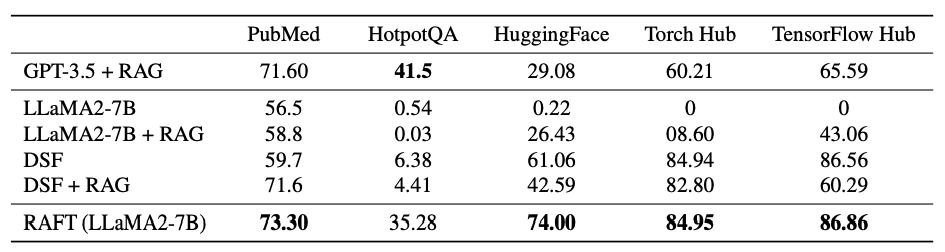
对比传统RAG实验
-
COT的影响实验

-
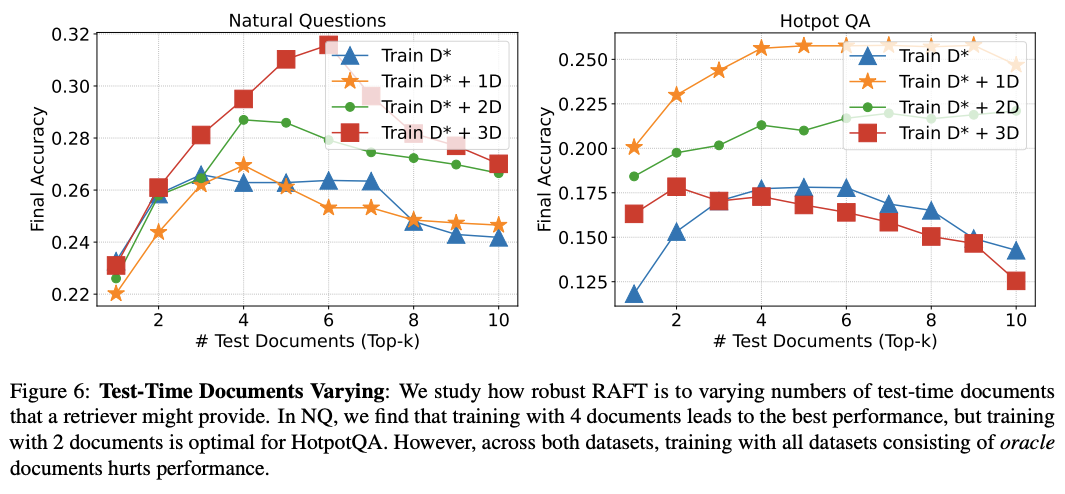
训练数据的上下文包含不相关文档的数量对效果的影响实验
总结
本文主要记录了RAFT方法如何构造训练数据,微调LLM提高对垂域知识的适应性,为大型语言模型在特定领域内的应用提供了一种有效的提升途径。
参考文献
【1】RAFT: Adapting Language Model to Domain Specific RAG,https://arxiv.org/pdf/2403.10131.pdf
【2】https://github.com/ShishirPatil/gorilla/blob/main/raft/raft.py

















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









