







 文章介绍了一种新的深度检测器MVDNet,它有效融合激光雷达和雷达信号,利用激光雷达的高分辨率和雷达的冗余信息。MVDNet采用多帧输入和自/跨注意力机制,针对雾天条件下的ORR数据集进行了实验验证。
文章介绍了一种新的深度检测器MVDNet,它有效融合激光雷达和雷达信号,利用激光雷达的高分辨率和雷达的冗余信息。MVDNet采用多帧输入和自/跨注意力机制,针对雾天条件下的ORR数据集进行了实验验证。
Challenge:
现有的目标检测器主要融合激光雷达和相机,通常提供丰富和冗余的视觉信息
利用最先进的成像雷达,其分辨率比RadarNet和LiRaNet中使用的分辨率要细得多,提出了一种有效的深度后期融合方法来结合雷达和激光雷达信号。
MVDNet本质是将雷达强度图与激光雷达点云深度融合,以利用它们的互补能力。
Contribution:
1.提出了一种深度后期融合检测器MVDNet,可以有效地利用激光雷达和雷达的互补优势。
2.在雾天条件下引入了一个具有细粒度激光雷达和雷达点云的标记数据集。(同步ORR数据集中雷达和激光雷达,扫描频率不同)
Method:
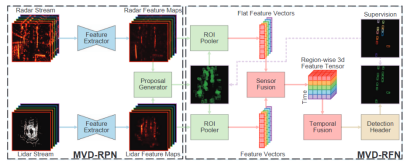
MVDNet
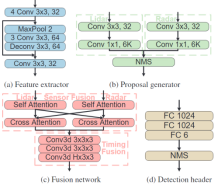
多帧(H frames)输入,2D卷积提取特征图,连接每个传感器所有帧的特征图卷积生成RoI,两个传感器生成的建议通过非最大抑制(NMS)合并。再用RoI在2*H个特征图中进行RoI Pooling得到2*H*C*W*L RoI特征图,两个传感器的特征图进行Self Attention和Cross Attention后按时间维度concat起来进行refinement。
Self Attention和Cross Attention如下:简单说就用自己(Self)和另一个传感器数据(Cross)计算出注意力加权图进行加权(引用AtLoc)
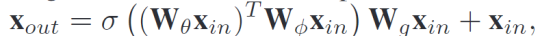
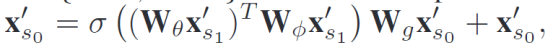
Dataset Preparation
ORR:radar scans at a step of 0.9 every 0.25 s and lidar at a step of 0.33 every 0.05 s.
对于一个radar,收集连续N=5帧的lidar,从这5帧lidar中,选择属于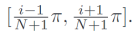
扇区的lidar点,重新组合为lidar完成同步。而不是简单选择最接近的一帧(不管哪帧始终有一部分是偏移的)。
同步前后的可视化:

Experiments
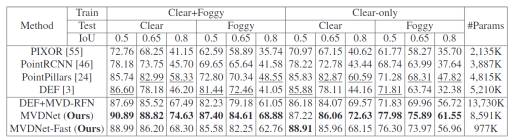
精度对比(BEV)
可视化验证Radar的帮助:


















 4377
4377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









