







文章目录
作者:小猪快跑
基础数学&计算数学,从事优化领域7年+,主要研究方向:MIP求解器、整数规划、随机规划、智能优化算法
常用离散分布(二项分布、泊松分布、超几何分布、几何分布与负二项分布)的数学期望、方差、特征函数具体推导。
如有错误,欢迎指正。如有更好的算法,也欢迎交流!!!——@小猪快跑
相关教程
- 常用分布的数学期望、方差、特征函数
- 【推导过程】常用离散分布的数学期望、方差、特征函数
- 【推导过程】常用连续分布的数学期望、方差、特征函数
- Z分位数速查表
- 【概率统计通俗版】极大似然估计
- 【附代码&原理】正态分布检验
- 【附代码&原理】偏正态分布的数据处理方法
- 【超详图文】多少样本量用 t分布 OR 正态分布
- 【推导过程】常用共轭先验分布
- 【机器学习】【通俗版】EM算法(待更新)
相关文献
- [1]茆诗松,周纪芗.概率论与数理统计 (第二版)[M].中国统计出版社,2000.
常用离散分布的数学期望&方差&特征函数
| 分布名称 | 概率分布或密度函数 p ( x ) p(x) p(x) | 数学期望 | 方差 | 特征函数 |
|---|---|---|---|---|
| 单点分布 |
p
c
=
1
\begin{array}{c}{p_{c}=1}\end{array}
pc=1 ( c c c 为常数) | c c c | 0 0 0 | e i c t e^{ict} eict |
| 0 − 1 0-1 0−1分布 | p 0 = 1 − p , p 1 = p ( 0 < p < 1 ) \begin{array}{c} p_{0}=1-p,p_{1}=p\\ (0<p<1)\end{array} p0=1−p,p1=p(0<p<1) | p p p | p ( 1 − p ) p(1-p) p(1−p) | 1 − p + p e i t 1-p+pe^{it} 1−p+peit |
| 二项分布 b ( n , p ) b(n,p) b(n,p) | p k = ( n k ) p k ( 1 − p ) n − k k = 0 , 1 , 2 , ⋯ , n ( 0 < p < 1 ) p_{k}=\binom{n}{k}p^{k}(1-p)^{n-k}\\k=0,1,2,\cdots,n\\(0<p<1) pk=(kn)pk(1−p)n−kk=0,1,2,⋯,n(0<p<1) | n p np np | n p ( 1 − p ) np(1-p) np(1−p) | ( 1 − p + p e i t ) n (1-p+pe^{it})^{n} (1−p+peit)n |
| 泊松分布 P ( λ ) P(\lambda) P(λ) | p k = λ k k ! e − k k = 0 , 1 , 2 , ⋯ ; ( λ > 0 ) p_{k}=\frac{\lambda^{k}}{k!}e^{-k}\\k=0,1,2,\cdots;(\lambda>0) pk=k!λke−kk=0,1,2,⋯;(λ>0) | λ \lambda λ | λ \lambda λ | e λ ( e i t − 1 ) e^{\lambda(e^{it}-1)} eλ(eit−1) |
| 超几何分布 h ( n , N , M ) h(n,N,M) h(n,N,M) | p k = ( M k ) ( N − M n − k ) ( N n ) M ⩽ N , n ⩽ N , M , N , n 正整数, k = 0 , 1 , 2 , ⋯ , min ( M , N ) p_{k}=\frac{\displaystyle\binom{M}{k}\binom{N-M}{n-k}}{\displaystyle\binom{N}{n}}\\M\leqslant N,n\leqslant N,M,N,n\text{ 正整数,}\\k=0,1,2,\cdots,\min(M,N) pk=(nN)(kM)(n−kN−M)M⩽N,n⩽N,M,N,n 正整数,k=0,1,2,⋯,min(M,N) | n M N n\displaystyle\frac MN nNM | n M N ( 1 − M N ) N − n N − 1 \displaystyle\frac{nM}N(1-\frac MN)\frac{N-n}{N-1} NnM(1−NM)N−1N−n | ∑ k = 0 n ( M k ) ( N − M n − k ) ( N n ) e i t k \displaystyle\sum_{k=0}^n\frac{\displaystyle\binom Mk\binom{N-M}{n-k}}{\displaystyle\binom Nn}e^{itk} k=0∑n(nN)(kM)(n−kN−M)eitk |
| 几何分布 G e ( p ) Ge(p) Ge(p) | p k = ( 1 − p ) k − 1 p k = 1 , 2 , ⋯ ( 0 < p < 1 ) p_{k}=(1-p)^{k-1}p\\k=1,2,\cdots\\(0<p<1) pk=(1−p)k−1pk=1,2,⋯(0<p<1) | 1 p \displaystyle\frac1p p1 | 1 − p p 2 \displaystyle\frac{1-p}{p^2} p21−p | p e i t 1 − ( 1 − p ) e i t \displaystyle\frac{pe^{it}}{1-(1-p)e^{it}} 1−(1−p)eitpeit |
| 负二项分布 帕斯卡分布 N b ( r , p ) Nb(r,p) Nb(r,p) | p k = ( k − 1 r − 1 ) ( 1 − p ) k − r p r r 正整数 , k = r , r + 1 , ⋯ ( 0 < p < 1 ) \begin{gathered}p_{k}={\binom{k-1}{r-1}}(1-p)^{k-r}p^{r} \\r正整数,k=r,r+1,\cdots \\(0<p<1) \end{gathered} pk=(r−1k−1)(1−p)k−rprr正整数,k=r,r+1,⋯(0<p<1) | r p \displaystyle\frac rp pr | r ( 1 − p ) p 2 \displaystyle\frac{r(1-p)}{p^2} p2r(1−p) | ( p e i t 1 − ( 1 − p ) e i t ) r \left(\displaystyle\frac{pe^{it}}{1-(1-p)e^{it}}\right)^r (1−(1−p)eitpeit)r |
二项分布
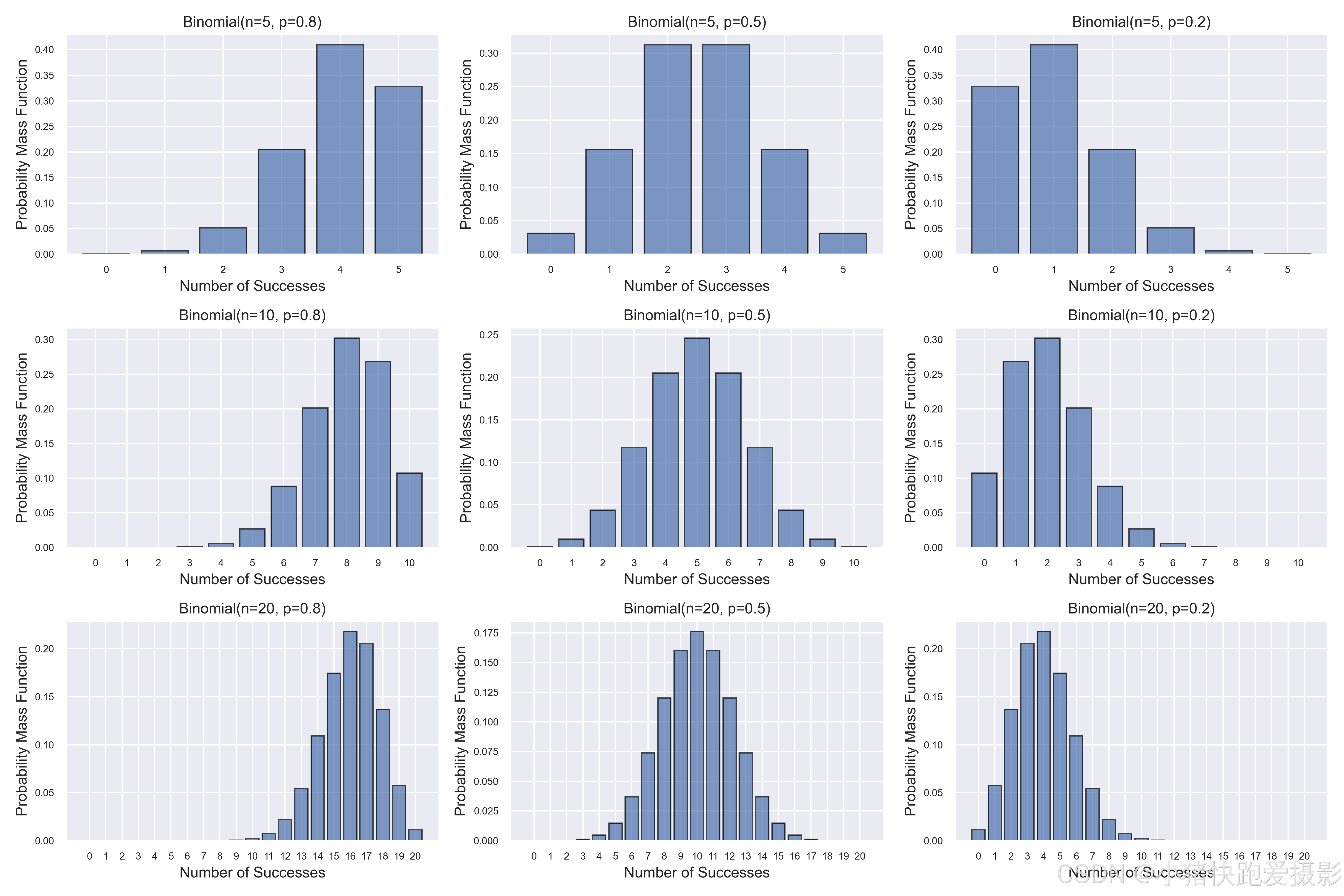
如果记 X X X 为 n n n 重伯努利试验中成功(记为事件 A A A )的次数,则 X X X 的可能取值为 0 , 1 , ⋯ , n 0,1,\cdots,n 0,1,⋯,n。 记 p p p 为每次试验中 A A A 发生的概率,即 P ( A ) = p P(A)=p P(A)=p,则 P ( A ˉ ) = 1 − p P(\bar A)=1-p P(Aˉ)=1−p。
因为
n
n
n重伯努利试验的基本结果可以记作
ω
=
(
ω
1
,
ω
2
,
⋯
,
ω
n
)
\omega = (\omega_1, \omega_2, \cdots , \omega_n)
ω=(ω1,ω2,⋯,ωn)
其中
ω
i
\omega_i
ωi 或者为
A
A
A,或者为
A
ˉ
\bar A
Aˉ。 这样的
ω
\omega
ω 共有
2
n
2^n
2n 个,这
2
n
2^n
2n 个样本点
ω
\omega
ω 组成了样本空间
Ω
\Omega
Ω。
下面求
X
X
X 的分布列,即求事件
{
X
=
k
}
\{X=k\}
{X=k} 的概率。若某个样本点
ω
=
(
ω
1
,
ω
2
,
⋯
,
ω
n
)
∈
{
X
=
k
}
\omega = (\omega_1,\omega_2,\cdots,\omega_n) \in \{ X = k \}
ω=(ω1,ω2,⋯,ωn)∈{X=k}
意味着
ω
1
,
ω
2
,
⋯
,
ω
n
\omega_1,\omega_2,\cdots,\omega_n
ω1,ω2,⋯,ωn 中有
k
k
k个
A
,
n
−
k
A,n-k
A,n−k个
A
ˉ
\bar A
Aˉ,所以由独立性知
P
(
ω
)
=
p
k
(
1
−
p
)
n
−
k
P(\omega) = p^k(1-p)^{n-k}
P(ω)=pk(1−p)n−k
而事件
{
X
=
k
}
\{X=k\}
{X=k} 中这样的
ω
\omega
ω 共有
(
n
k
)
\binom nk
(kn) 个,所以
X
X
X 的分布列为
P ( X = k ) = ( n k ) p k ( 1 − p ) n − k , k = 0 , 1 , ⋯ , n P(X=k)=\binom{n}{k}p^k(1-p)^{n-k}, k=0,1,\cdots,n P(X=k)=(kn)pk(1−p)n−k,k=0,1,⋯,n
数学期望
E ( X ) = ∑ k = 0 n k ( n k ) p k ( 1 − p ) n − k = n p ∑ k = 1 n ( n − 1 k − 1 ) p k − 1 ( 1 − p ) ( n − 1 ) − ( k − 1 ) = n p [ p + ( 1 − p ) ] n − 1 = n p \begin{aligned} E(X)& =\sum_{k=0}^nk\binom nkp^k(1-p)^{n-k} \\ &=np\sum_{k=1}^n\binom{n-1}{k-1}p^{k-1}(1-p)^{(n-1)-(k-1)} \\ &=np[p+(1-p)]^{n-1}=np \end{aligned} E(X)=k=0∑nk(kn)pk(1−p)n−k=npk=1∑n(k−1n−1)pk−1(1−p)(n−1)−(k−1)=np[p+(1−p)]n−1=np
方差
E ( X 2 ) = ∑ k = 0 n k 2 ( n k ) p k ( 1 − p ) n − k = ∑ k = 1 n ( k − 1 + 1 ) k ( n k ) p k ( 1 − p ) n − k = ∑ k = 1 n k ( k − 1 ) ( n k ) p k ( 1 − p ) n − k + ∑ k = 1 n k ( n k ) p k ( 1 − p ) n − k = ∑ k = 2 n k ( k − 1 ) ( n k ) p k ( 1 − p ) n − k + n p = n ( n − 1 ) p 2 ∑ k = 2 n ( n − 2 k − 2 ) p k − 2 ( 1 − p ) ( n − 2 ) − ( k − 2 ) + n p = n ( n − 1 ) p 2 + n p . \begin{align*} E(X^2) & = \sum_{k=0}^nk^2\binom nkp^k(1-p)^{n-k} \\ & = \sum_{k=1}^n(k-1+1)k\binom nkp^k(1-p)^{n-k} \\ & = \sum_{k=1}^nk(k-1)\binom nkp^k(1-p)^{n-k} + \sum_{k=1}^nk\binom nkp^k(1-p)^{n-k} \\ & = \sum_{k=2}^nk(k-1)\binom nkp^k(1-p)^{n-k} + np \\ & = n(n-1)p^2\sum_{k=2}^n\binom{n-2}{k-2} p^{k-2} (1-p)^{(n-2)-(k-2)} + np \\ & = n(n-1)p^2 + np. \end{align*} E(X2)=k=0∑nk2(kn)pk(1−p)n−k=k=1∑n(k−1+1)k(kn)pk(1−p)n−k=k=1∑nk(k−1)(kn)pk(1−p)n−k+k=1∑nk(kn)pk(1−p)n−k=k=2∑nk(k−1)(kn)pk(1−p)n−k+np=n(n−1)p2k=2∑n(k−2n−2)pk−2(1−p)(n−2)−(k−2)+np=n(n−1)p2+np.
V a r ( X ) = E ( X 2 ) − [ E ( X ) ] 2 = n ( n − 1 ) p 2 + n p − ( n p ) 2 = n p ( 1 − p ) \mathrm{Var}(X) = E(X^2) - [E(X)]^2 = n(n-1)p^2 + np - (np)^2 = np(1-p) Var(X)=E(X2)−[E(X)]2=n(n−1)p2+np−(np)2=np(1−p)
泊松分布
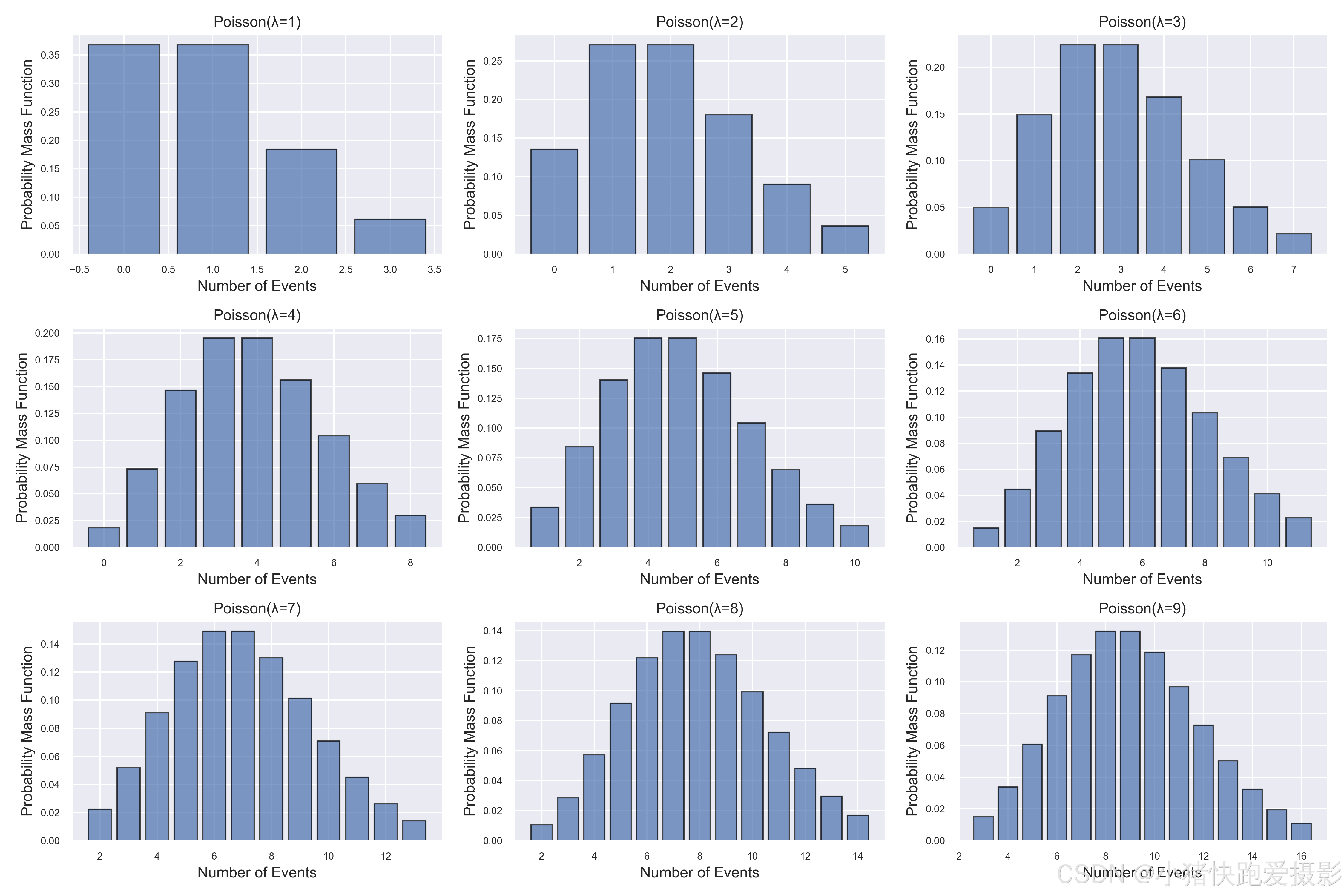
-
在单位时间内,电话总机接到用户呼唤的次数
-
在单位时间内,一电路受到外界电磁波的冲击次数
-
1平方米内,玻璃上的气泡数
-
一铸件上的砂眼数
-
在单位时间内,某种放射性物质分裂到某区域的质点数等等
设随机变量
X
∼
P
(
λ
)
X\sim P(\lambda)
X∼P(λ)
P
(
X
=
k
)
=
λ
k
k
!
e
−
λ
,
k
=
0
,
1
,
2
,
⋯
,
P(X=k)=\frac{\lambda^k}{k!}\mathrm{e}^{-\lambda}, k=0, 1,2,\cdots,
P(X=k)=k!λke−λ,k=0,1,2,⋯,
泊松定理
在
n
n
n重伯努利试验中,记事件
A
A
A 在一次试验中发生的概率为
p
n
p_n
pn(与试验次数
n
n
n 有关),如果当
n
→
+
∞
n\to+\infty
n→+∞ 时,有
n
p
n
→
λ
np_n\to\lambda
npn→λ,则
lim
n
→
+
∞
(
n
k
)
p
n
k
(
1
−
p
n
)
n
−
k
=
λ
k
k
!
e
−
λ
.
\lim_{n\to+\infty} \binom nk p_n^k(1-p_n)^{n-k} = \frac{\lambda^k}{k!}\mathrm{e}^{-\lambda}.
n→+∞lim(kn)pnk(1−pn)n−k=k!λke−λ.
记
n
p
n
=
λ
n
np_n=\lambda_n
npn=λn,记
p
n
=
λ
n
/
n
p_n=\lambda_n/n
pn=λn/n,我们可得
(
n
k
)
p
n
k
(
1
−
p
n
)
n
−
k
=
n
(
n
−
1
)
⋯
(
n
−
k
+
1
)
k
!
(
λ
n
n
)
k
(
1
−
λ
n
n
)
n
−
k
=
λ
n
k
k
!
(
1
−
1
n
)
(
1
−
2
n
)
⋯
(
1
−
k
−
1
n
)
(
1
−
λ
n
n
)
n
−
k
.
\begin{align*} \binom nk p_n^k(1-p_n)^{n-k} & = \frac{n(n-1)\cdots(n-k+1)}{k!}\left( \frac{\lambda_n}n \right)^k \left( 1 - \frac{\lambda_n}n \right)^{n-k} \\ & = \frac{\lambda_n^k}{k!}\left( 1 - \frac1n \right)\left( 1 - \frac2n \right) \cdots \left( 1 - \frac{k-1}n \right) \left( 1 - \frac{\lambda_n}n \right)^{n-k}. \end{align*}
(kn)pnk(1−pn)n−k=k!n(n−1)⋯(n−k+1)(nλn)k(1−nλn)n−k=k!λnk(1−n1)(1−n2)⋯(1−nk−1)(1−nλn)n−k.
对固定的
k
k
k 有
lim
n
→
+
∞
λ
n
=
λ
lim
n
→
+
∞
(
1
−
λ
n
n
)
n
−
k
=
e
−
λ
lim
n
→
+
∞
(
1
−
1
n
)
⋯
(
1
−
k
−
1
n
)
=
1
\begin{align*} & \lim_{n\to+\infty}\lambda_n = \lambda \\ & \lim_{n\to+\infty}\left( 1 - \frac{\lambda_n}n \right)^{n-k} = \mathrm{e}^{-\lambda} \\ & \lim_{n\to+\infty}\left( 1 - \frac1n \right) \cdots \left( 1 - \frac{k-1}n \right) = 1 \end{align*}
n→+∞limλn=λn→+∞lim(1−nλn)n−k=e−λn→+∞lim(1−n1)⋯(1−nk−1)=1
从而
lim
n
→
+
∞
(
n
k
)
p
n
k
(
1
−
p
n
)
n
−
k
=
λ
k
k
!
e
−
λ
\lim_{n\to+\infty} \binom nk p_n^k(1-p_n)^{n-k} = \frac{\lambda^k}{k!}\mathrm{e}^{-\lambda}
n→+∞lim(kn)pnk(1−pn)n−k=k!λke−λ
对任意的
k
k
k(
k
=
0
,
1
,
2
,
⋯
k=0,1,2,\cdots
k=0,1,2,⋯)成立。
数学期望
E ( X ) = ∑ k = 0 + ∞ k λ k k ! e − λ = λ e − λ ∑ k = 1 + ∞ λ k − 1 ( k − 1 ) ! = λ e − λ e λ = λ E(X) = \sum_{k=0}^{+\infty} k\frac{\lambda^k}{k!}\mathrm{e}^{-\lambda} = \lambda\mathrm{e}^{-\lambda} \sum_{k=1}^{+\infty}\frac{\lambda^{k-1}}{(k-1)!} = \lambda\mathrm{e}^{-\lambda} \mathrm{e}^\lambda = \lambda E(X)=k=0∑+∞kk!λke−λ=λe−λk=1∑+∞(k−1)!λk−1=λe−λeλ=λ
方差
E ( X 2 ) = ∑ k = 0 + ∞ k 2 λ k k ! e − λ = ∑ k = 1 + ∞ k λ k ( k − 1 ) ! e − λ = ∑ k = 1 + ∞ [ ( k − 1 ) + 1 ] λ k ( k − 1 ) ! e − λ = λ 2 e − λ ∑ k = 2 + ∞ λ k − 2 ( k − 2 ) ! + λ e − λ ∑ k = 1 + ∞ λ k − 1 ( k − 1 ) ! = λ 2 + λ . \begin{aligned} E(X^{2})& =\sum_{k=0}^{+\infty}k^{2}\frac{\lambda^{k}}{k!}\mathrm{e}^{-\lambda}=\sum_{k=1}^{+\infty}k \frac{\lambda^{k}}{(k-1)!}\mathrm{e}^{-\lambda} \\ &=\sum_{k=1}^{+\infty}[(k-1)+1]\frac{\lambda^k}{(k-1)!}\mathrm{e}^{-\lambda} \\ &=\lambda^{2}\mathrm{e}^{-\lambda}\sum_{k=2}^{+\infty}\frac{\lambda^{k-2}}{(k-2)!}+\lambda\mathrm{e}^{-\lambda}\sum_{k=1}^{+\infty}\frac{\lambda^{k-1}}{(k-1)!} \\ &=\lambda^{2}+\lambda. \end{aligned} E(X2)=k=0∑+∞k2k!λke−λ=k=1∑+∞k(k−1)!λke−λ=k=1∑+∞[(k−1)+1](k−1)!λke−λ=λ2e−λk=2∑+∞(k−2)!λk−2+λe−λk=1∑+∞(k−1)!λk−1=λ2+λ.
V a r ( X ) = E ( X 2 ) − [ E ( X ) ] 2 = λ 2 + λ − λ 2 = λ \mathrm{Var}(X)=E(X^2)-[E(X)]^2=\lambda^2+\lambda-\lambda^2=\lambda Var(X)=E(X2)−[E(X)]2=λ2+λ−λ2=λ
超几何分布
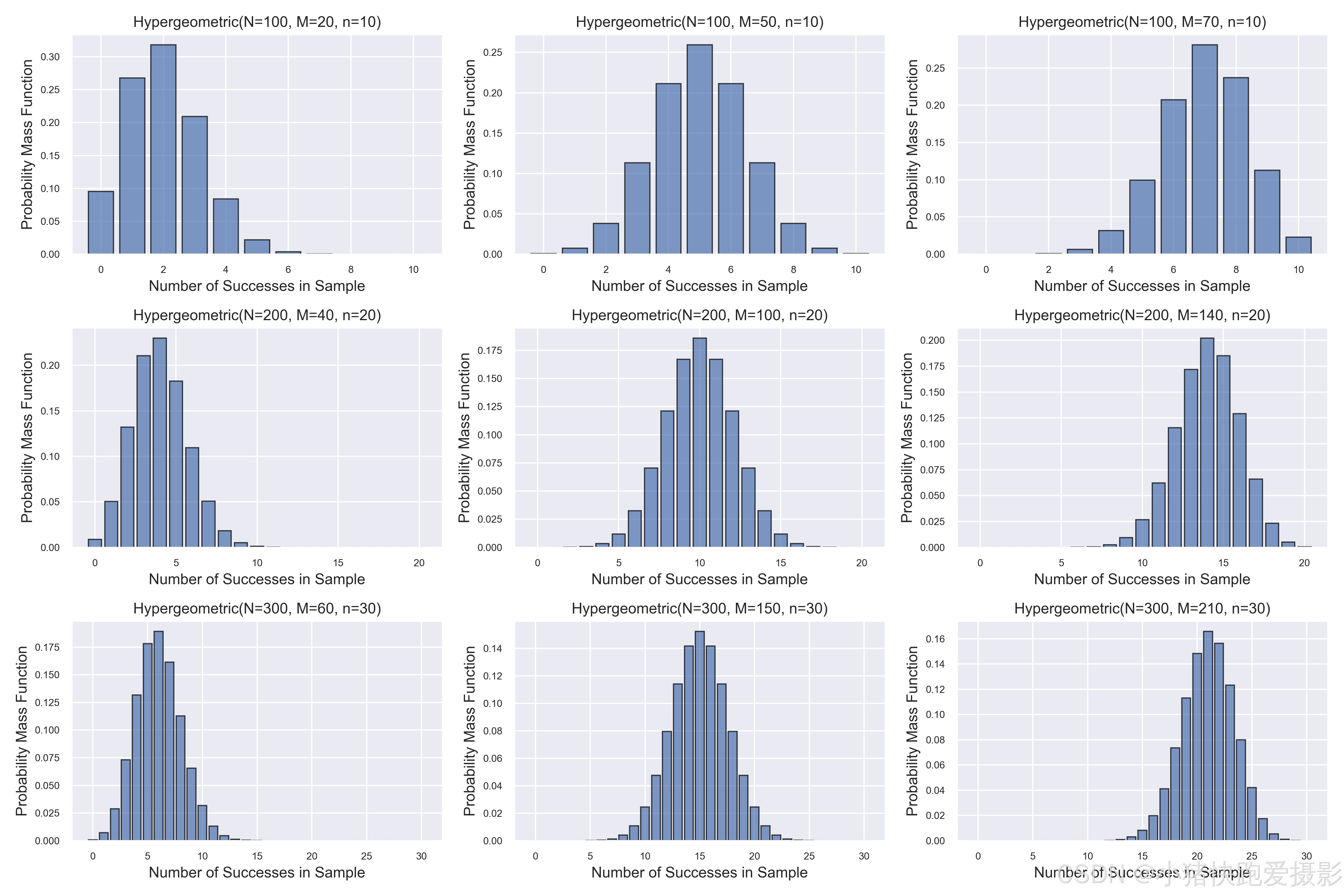
从一个有限总体中进行不放回抽样常会遇到超几何分布。
设有
N
N
N 个产品,其中有
M
M
M 个不合格品。若从中不放回地随机抽取
n
n
n 个,则其中含有的不合格品的个数
X
X
X 服从超几何分布,记为
X
∼
h
(
n
,
N
,
M
)
X\sim h(n,N,M)
X∼h(n,N,M)。超几何分布的概率分布列为
P
(
X
=
k
)
=
(
M
k
)
(
N
−
M
n
−
k
)
(
N
n
)
,
k
=
0
,
1
,
⋯
,
r
P(X = k) = \frac{\binom Mk \binom{N-M}{n-k}} {\binom Nn},\; k = 0,1,\cdots,r
P(X=k)=(nN)(kM)(n−kN−M),k=0,1,⋯,r
其中 r = min { M , n } r=\min\{M,n\} r=min{M,n},且 M ≤ N , n ≤ N , n , N , M M\le N,n\le N,n,N,M M≤N,n≤N,n,N,M 均为正整数。
超几何分布的二项近似
当
n
≪
N
n\ll N
n≪N 时,即抽取个数
n
n
n 远小于产品总数
N
N
N 时,每次抽取后,总体中的不合格品率
p
=
M
/
N
p=M/N
p=M/N 改变甚徽,所以不放回抽样可近似地看成放回抽样,这时超几何分布可用二项分布近似:
(
M
k
)
(
N
−
M
n
−
k
)
(
N
n
)
≅
(
n
k
)
p
k
(
1
−
p
)
n
−
k
,
其中
p
=
M
N
\frac{\binom Mk \binom{N-M}{n-k}} {\binom Nn} \cong \binom nkp^k(1-p)^{n-k},\;\text{其中}\,p = \frac MN
(nN)(kM)(n−kN−M)≅(kn)pk(1−p)n−k,其中p=NM
数学期望
若
X
∼
h
(
n
,
N
,
M
)
X\sim h(n,N,M)
X∼h(n,N,M),则
X
X
X 的数学期望为
E
(
X
)
=
∑
k
=
0
r
k
(
M
k
)
(
N
−
M
n
−
k
)
(
N
n
)
=
n
M
N
∑
k
=
1
r
(
M
−
1
k
−
1
)
(
N
−
M
n
−
k
)
(
N
−
1
n
−
1
)
=
n
M
N
E(X) = \sum_{k=0}^rk\frac{\binom Mk \binom{N-M}{n-k}} {\binom Nn} = n\frac MN \sum_{k=1}^r \frac{\binom {M-1}{k-1} \binom{N-M}{n-k}} {\binom {N-1}{n-1}} = n\frac MN
E(X)=k=0∑rk(nN)(kM)(n−kN−M)=nNMk=1∑r(n−1N−1)(k−1M−1)(n−kN−M)=nNM
方差
E ( X 2 ) = ∑ k = 1 r k 2 ( M k ) ( N − M n − k ) ( N n ) = ∑ k = 2 r k ( k − 1 ) ( M k ) ( N − M n − k ) ( N n ) + n M N = M ( M − 1 ) ( N n ) ∑ k = 2 r k ( k − 1 ) ( M − 2 k − 2 ) ( N − M n − k ) + n M N = M ( M − 1 ) ( N n ) ( N − 2 n − 2 ) + n M N = M ( M − 1 ) n ( n − 1 ) N ( N − 1 ) + n M N , \begin{align*} E(X^2) & = \sum_{k=1}^rk^2\frac{\binom Mk \binom{N-M}{n-k}} {\binom Nn} = \sum_{k=2}^r k(k-1) \frac{\binom Mk \binom{N-M}{n-k}} {\binom Nn} + n \frac MN \\ & = \frac{M(M-1)}{\binom Nn} \sum_{k=2}^rk(k-1) \binom{M-2}{k-2} \binom{N-M}{n-k} + n\frac MN \\ & = \frac{M(M-1)}{\binom Nn} \binom{N-2}{n-2} + n \frac MN = \frac{M(M-1)n(n-1)}{N(N-1)} + n \frac MN, \end{align*} E(X2)=k=1∑rk2(nN)(kM)(n−kN−M)=k=2∑rk(k−1)(nN)(kM)(n−kN−M)+nNM=(nN)M(M−1)k=2∑rk(k−1)(k−2M−2)(n−kN−M)+nNM=(nN)M(M−1)(n−2N−2)+nNM=N(N−1)M(M−1)n(n−1)+nNM,
由此得
X
X
X 的方差为
V
a
r
(
X
)
=
E
(
X
2
)
−
[
E
(
X
)
]
2
=
n
M
(
N
−
M
)
(
N
−
n
)
N
2
(
N
−
1
)
\mathrm{Var}(X) = E(X^2) - [E(X)]^2 = \frac{nM(N-M)(N-n)}{N^2(N-1)}
Var(X)=E(X2)−[E(X)]2=N2(N−1)nM(N−M)(N−n)
几何分布
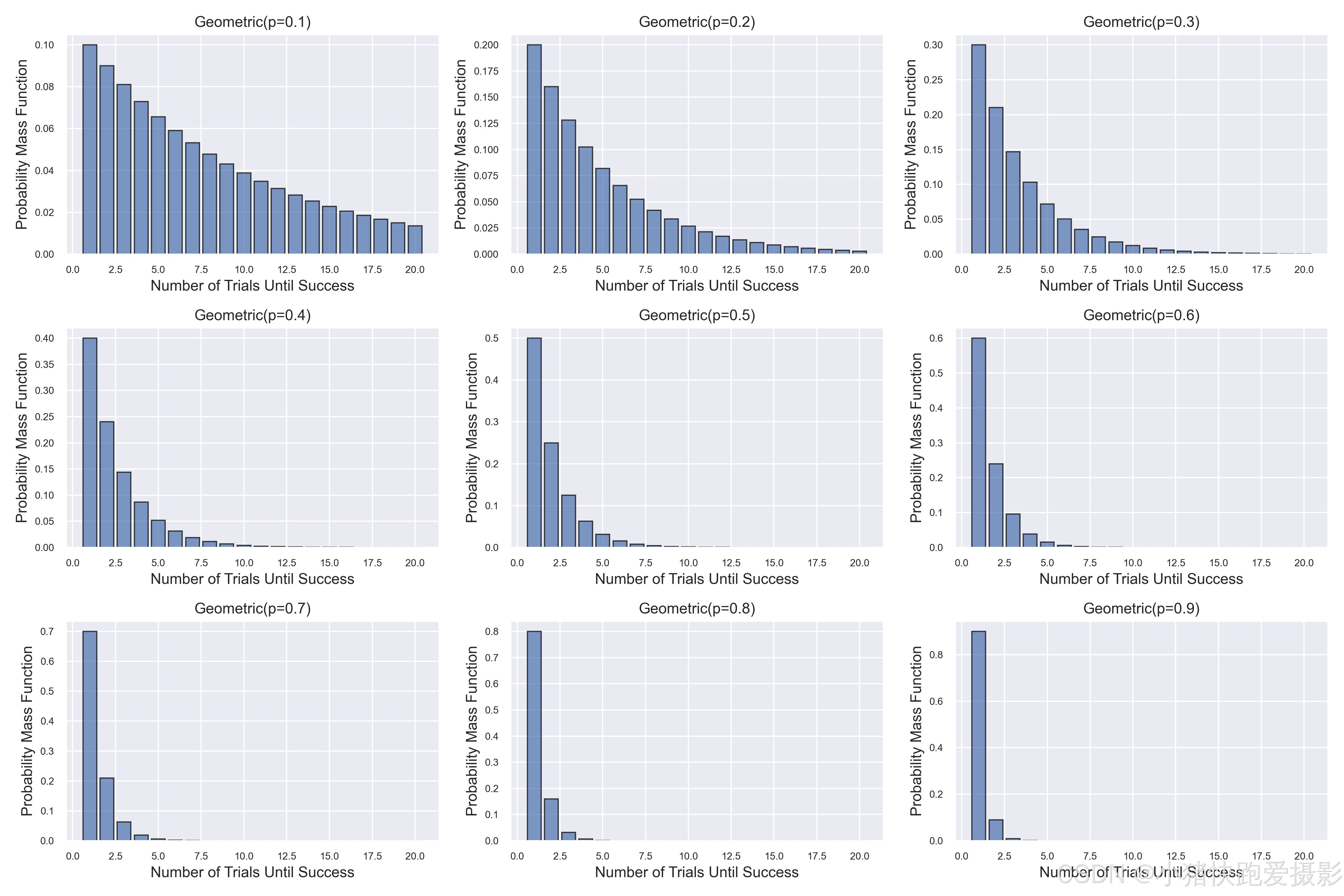
在伯努利试验序列中,记每次试验中事件
A
A
A发生的概率为
p
p
p,如果
X
X
X为事件
A
A
A首次出现时的试验次数,则
X
X
X的可能取值为
1
,
2
,
⋯
1,2,\cdots
1,2,⋯,称
X
X
X服从几何分布,记为
X
∼
G
e
(
p
)
X\sim Ge(p)
X∼Ge(p),其分布列为
P
(
X
=
k
)
=
(
1
−
p
)
k
−
1
p
,
k
=
1
,
2
,
⋯
P(X = k) = (1 - p)^{k-1}p,\; k = 1,2,\cdots
P(X=k)=(1−p)k−1p,k=1,2,⋯
实际中有不少随机变量服从几何分布,譬如,
-
某产品的不合格率为0.05,则首次查到不合格品的检查次数 X ∼ G e ( 0.05 ) X\sim Ge(0.05) X∼Ge(0.05)
-
某射手的命中率为0.8,则首次击中目标的射击次数 Y ∼ G e ( 0.8 ) Y\sim Ge(0.8) Y∼Ge(0.8)
-
掷一颗骰子,首次出现6点的投掷次数 Z ∼ G e ( 1 / 6 ) Z\sim Ge(1/6) Z∼Ge(1/6)
-
同时掷两颗骰子,首次达到两个点数之和为8的投掷次数 W ∼ G e ( 5 / 36 ) W\sim Ge(5/36) W∼Ge(5/36)
几何分布的无记忆性
设
X
∼
G
e
(
p
)
X\sim Ge(p)
X∼Ge(p),则对任意正整数
m
m
m与
n
n
n有
P
(
X
>
m
+
n
∣
X
>
m
)
=
P
(
X
>
n
)
P(X > m + n| X > m) = P(X > n)
P(X>m+n∣X>m)=P(X>n)
在证明之前先解释上述概率等式的含义.在一列伯努利试验序列中,若首次成功
(
A
)
(A)
(A)出现的试验次数X服从几何分布,则事件“
X
>
m
X>m
X>m”表示前
m
m
m次试验中
A
A
A没有出现.假如在接下去的
n
n
n次试验中
A
A
A仍未出现,这个事件记为“
X
>
m
+
n
X>m+n
X>m+n”.这个定理表明:在前
m
m
m次试验中
A
A
A没有出现的条件下,则在接下去的
n
n
n次试验中
A
A
A仍未出现的概率只与
n
n
n有关,而与以前的
m
m
m次试验无关,似乎忘记了前
m
m
m次试验结果,这就是无记忆性。
因为
P
(
X
>
n
)
=
∑
k
=
n
+
1
+
∞
(
1
−
p
)
k
−
1
p
=
p
(
1
−
p
)
n
1
−
(
1
−
p
)
=
(
1
−
p
)
n
P(X > n) = \sum_{k=n+1}^{+\infty}(1-p)^{k-1}p = \frac{p(1-p)^n}{1-(1-p)} = (1-p)^n
P(X>n)=k=n+1∑+∞(1−p)k−1p=1−(1−p)p(1−p)n=(1−p)n
所以对任意的正整数
m
m
m 与
n
n
n,条件概率
P
(
X
>
m
+
n
∣
X
>
m
)
=
P
(
X
>
m
+
n
)
P
(
X
>
m
)
=
(
1
−
p
)
m
+
n
(
1
−
p
)
m
=
(
1
−
p
)
n
=
P
(
X
>
n
)
\begin{align*} P(X > m + n | X > m) & = \frac{P(X>m+n)}{P(X>m)} = \frac{(1-p)^{m+n}}{(1-p)^m} \\ & = (1 - p)^n = P(X > n) \end{align*}
P(X>m+n∣X>m)=P(X>m)P(X>m+n)=(1−p)m(1−p)m+n=(1−p)n=P(X>n)
数学期望
设随机变量
X
X
X服从几何分布
G
e
(
p
)
Ge(p)
Ge(p),令
q
=
1
−
p
q=1-p
q=1−p,利用逐项微分可得
X
X
X的数学期望为
E
(
X
)
=
∑
k
=
1
+
∞
k
p
q
k
−
1
=
p
∑
k
=
1
+
∞
k
q
k
−
1
=
p
∑
k
=
1
+
∞
d
q
k
d
q
=
p
d
d
q
(
∑
k
=
0
+
∞
q
k
)
=
p
d
d
q
(
1
1
−
q
)
=
p
(
1
−
q
)
2
=
1
p
\begin{align*} E(X) & = \sum_{k=1}^{+\infty} kpq^{k-1} = p\sum_{k=1}^{+\infty}kq^{k-1} = p\sum_{k=1}^{+\infty}\frac{\mathrm dq^k}{\mathrm dq} \\ & = p\frac{\mathrm d}{\mathrm dq}\Big( \sum_{k=0}^{+\infty}q^k \Big) = p \frac{\mathrm d}{\mathrm dq}\left( \frac1{1-q} \right) = \frac p{(1-q)^2} = \frac1p \end{align*}
E(X)=k=1∑+∞kpqk−1=pk=1∑+∞kqk−1=pk=1∑+∞dqdqk=pdqd(k=0∑+∞qk)=pdqd(1−q1)=(1−q)2p=p1
方差
E ( X 2 ) = ∑ k = 1 + ∞ k 2 p q k − 1 = p [ ∑ k = 1 + ∞ k ( k − 1 ) q k − 1 + ∑ k = 1 + ∞ k q k − 1 ] = p q ∑ k = 1 + ∞ k ( k − 1 ) q k − 2 + 1 p = p q ∑ k = 1 + ∞ d 2 d q 2 q k + 1 p = p q d 2 d q 2 ( ∑ k = 1 + ∞ q k ) + 1 p = p q d 2 d q 2 ( 1 1 − q ) + 1 p = p q 2 ( 1 − q ) 3 + 1 p = 2 q p 2 + 1 p \begin{align*} E(X^2) & = \sum_{k=1}^{+\infty} k^2pq^{k-1} = p \bigg[ \sum_{k=1}^{+\infty} k(k-1)q^{k-1} + \sum_{k=1}^{+\infty} kq^{k-1} \bigg] \\ & = pq\sum_{k=1}^{+\infty} k(k-1)q^{k-2} + \frac1p = pq \sum_{k=1}^{+\infty}\frac{\mathrm d^2}{\mathrm dq^2}q^k + \frac1p \\ & = pq\frac{\mathrm d^2}{\mathrm dq^2}\Big(\sum_{k=1}^{+\infty}q^k\big) + \frac1p = pq \frac{\mathrm d^2}{\mathrm dq^2}\left( \frac1{1-q}\right) + \frac1p \\ & = pq\frac2{(1-q)^3} + \frac1p = \frac{2q}{p^2} + \frac1p \end{align*} E(X2)=k=1∑+∞k2pqk−1=p[k=1∑+∞k(k−1)qk−1+k=1∑+∞kqk−1]=pqk=1∑+∞k(k−1)qk−2+p1=pqk=1∑+∞dq2d2qk+p1=pqdq2d2(k=1∑+∞qk)+p1=pqdq2d2(1−q1)+p1=pq(1−q)32+p1=p22q+p1
由此得
X
X
X的方差为
V
a
r
(
X
)
=
E
(
X
2
)
−
[
E
(
X
)
]
2
=
2
q
p
2
+
1
p
−
1
p
2
=
1
−
p
p
2
\mathrm{Var}(X) = E(X^2) - [E(X)]^2 = \frac{2q}{p^2} + \frac1p - \frac1{p^2} = \frac{1-p}{p^2}
Var(X)=E(X2)−[E(X)]2=p22q+p1−p21=p21−p
负二项分布
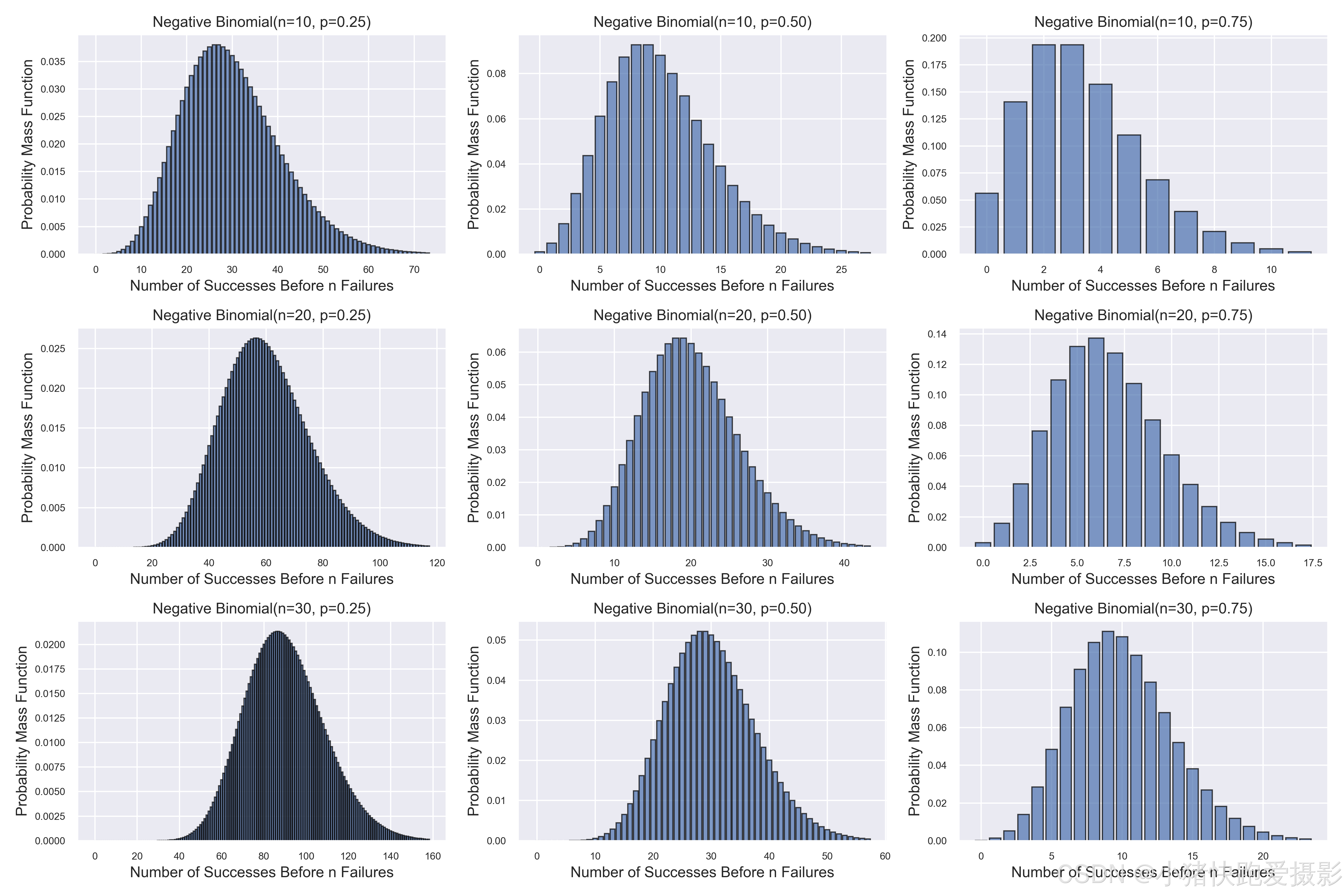
作为几何分布的一种延伸,我们注意下面的负二项分布,巴斯卡分布:
在伯努利试验序列中,记每次试验中事件
A
A
A发生的概率为
p
p
p,如果
X
X
X为事件
A
A
A第
r
r
r次出现时的试验次数,则
X
X
X的可能取值为
r
,
r
+
1
,
⋯
,
r
+
m
,
⋯
r,r+1,\cdots,r+m,\cdots
r,r+1,⋯,r+m,⋯. 称
X
X
X服从负二项分布或巴斯卡分布,其分布列为
P
(
X
=
k
)
=
(
k
−
1
r
−
1
)
p
r
(
1
−
p
)
k
−
r
,
k
=
r
,
r
+
1
,
⋯
P(X = k) = \binom{k-1}{r-1} p^r(1-p)^{k-r},\; k=r,r+1,\cdots
P(X=k)=(r−1k−1)pr(1−p)k−r,k=r,r+1,⋯
记为
X
∼
N
b
(
r
,
p
)
X\sim Nb(r,p)
X∼Nb(r,p)。当
r
=
1
r=1
r=1时,即为几何分布。
这是因为在次伯努利试验中,最后一次一定是 A A A,而前 k − 1 k-1 k−1次中 A A A应出现 r − 1 r-1 r−1次,由二项分布知其概率为 ( k − 1 r − 1 ) p r − 1 ( 1 − p ) k − r \binom{k-1}{r-1}p^{r-1}(1-p)^{k-r} (r−1k−1)pr−1(1−p)k−r,再乘以最后一次出现 A A A的概率 p p p,即得。
可以算得负二项分布的数学期望为 r / p r/p r/p,方差为 r ( 1 − p ) / p 2 r(1-p)/p^2 r(1−p)/p2。从直观上看这是合理的,因为首次出现 A A A的平均试验次数是 1 / p 1/p 1/p,那么第 r r r个 A A A出现所需的平均试验次数是 r / p r/p r/p。
如果将第一个 A A A出现的试验次数记为 X 1 X_1 X1,第二个 A A A出现的试验次数(从第一个 A A A出现之后算起)记为 X 2 X_2 X2,第 r r r个 A A A出现的试验次数(从第 r − 1 r-1 r−1个 A A A出现之后算起)记为 X r X_r Xr,则 X i X_i Xi独立同分布,且 X i ∼ G e ( p ) X_i\sim Ge(p) Xi∼Ge(p).此时有 X = X 1 + X 2 + ⋯ + X r ∼ N b ( r , p ) X=X_1+X_2+\cdots+X_r\sim Nb(r,p) X=X1+X2+⋯+Xr∼Nb(r,p),即负二项分布的随机变量可以表示成 r r r个独立同分布的几何分布随机变量之和。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









