






 本文介绍了如何将fastgpt的依赖从CPU计算的M3E模型切换到使用GPU的bgem3,通过在服务器上安装相关依赖并启动BGE-M3脚本,实现了显著的效率提升。操作步骤包括创建目录、下载脚本、安装依赖和更新API地址。
本文介绍了如何将fastgpt的依赖从CPU计算的M3E模型切换到使用GPU的bgem3,通过在服务器上安装相关依赖并启动BGE-M3脚本,实现了显著的效率提升。操作步骤包括创建目录、下载脚本、安装依赖和更新API地址。
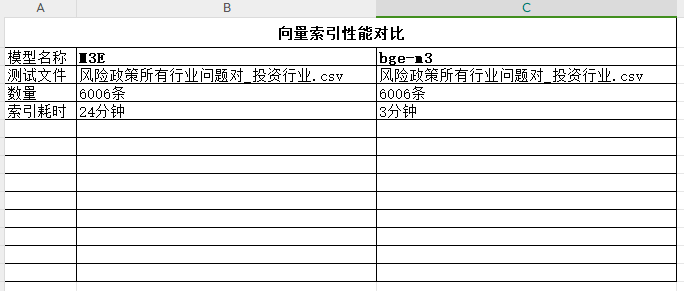
fastgpt自带的索引模型是M3E,因为它是依赖CPU做计算,导致速度非常慢。网上偶然发现可以用bgem3调用GPU做计算,效率提升了不少
操作步骤:
1、在服务器100.161.35.42新建目录/data/wenda/model/bgem3
2、在魔搭社区下载 git clone 魔搭社区
3、附件中的文件bge-m3.py放到/data/wenda/model/bgem3目录
4、安装依赖:pip install sentence-transformers -i Simple Index ,只要安装这一个依赖就行,因为前面已经安装好了fastgpt、docker等环境
5、执行bge-m3.py脚本启动bgem3,请从这里下载BGE-M3启动脚本 - 模板之家
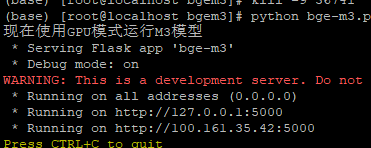
6、登陆one-api: http://127.0.0.1:18087,把旧的M3E地址http://127.0.0.1:6008修改为bgem3地址http://127.0.0.1:5000

















 1603
1603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









