










24年1月阿联酋科技创新研究院、孟加拉国伊斯兰科技大学、斯坦福大学、亚马逊公司和南卡大学AI研究院的论文“The What, Why, and How of Context Length Extension Techniques in Large Language Models – A Detailed Survey“。
LLM通常面临上下文长度外推方面的限制。 理解和扩展LLM的上下文长度对于提高其在各种 NLP 应用程序中的性能至关重要。 该综述深入探讨了其多方面问题,以及可能给 NLP 应用带来的潜在转变。 研究延长上下文长度相关的固有挑战,并对现有策略进行概述。 还讨论评估上下文扩展技术的复杂性,并强调该领域面临的开放挑战。 此外,探讨研究界是否就评估标准达成共识,并确定需要进一步达成一致的领域。
如图是LLM中上下文长度扩展技术的分类。 该图将这些技术分为插值和外推,其中它们进一步分为零样本和微调分支。 在上下文长度扩展领域,基于位置编码、检索、注意和 RoPE 的技术得到最多的探索。
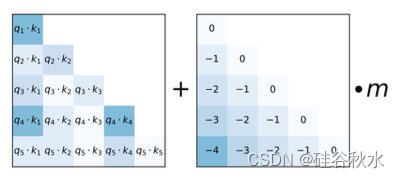
与绝对位置嵌入不同,相对位置嵌入是根据K和Q之间的差异制定的(Shaw,2018)。 Transformer-XL 中引入相对位置嵌入的普遍变化(Dai,2019b;Yang,2019)。 K和Q之间的注意计算已被更改,集成与相对位置相对应的可训练嵌入。 与绝对位置嵌入相比,配备相对位置嵌入的 Transformer 展示泛化到超过训练中长度序列的能力,展示了外推的熟练程度(Press et al., 2021b)。 与位置编码相关的一个反复出现的约束是无法超出训练期间观察的上下文窗口。
外推技术旨在将模型的理解扩展到超出其最初观察长度的序列,采用创新策略来捕获扩展范围内的依赖性。
**
零样本外推
**
在LLM领域,零样本上下文长度外推表示模型固有的能力,能够理解和生成比原始训练期间遇到长度更长的输入序列内容。 这种独特的熟练程度不需要对较长序列进行显式微调或额外训练,从而展示模型对给定任务中扩展上下文长度的适应性。 这种能力在以可变输入文本长度为特征的实际应用中非常重要。 该模型通过展示处理更广泛的上下文范围而无需针对特定任务进行调整的能力,强调了即使面对超出其训练范围的上下文,其在做出有意义的预测和生成连贯文本方面的多功能性。 这种内在的能力增强了模型在输入长度可能变化的各种现实场景中实用性,有助于其在各种上下文复杂性中处理和生成内容的有效性。
1 位置编码
位置编码在这种情况下成为关键组件,为模型提供了对输入序列顺序结构的洞察。 通过注入有关tokens位置的信息,这些技术在增强模型推断为扩展长度序列方面发挥了基础作用,而无需进行特定的微调。
RoPE(Rotary Position Embedding)
ALiBi(Attention with Linear Biases)
随机位置编码 Randomized Positional Encodings
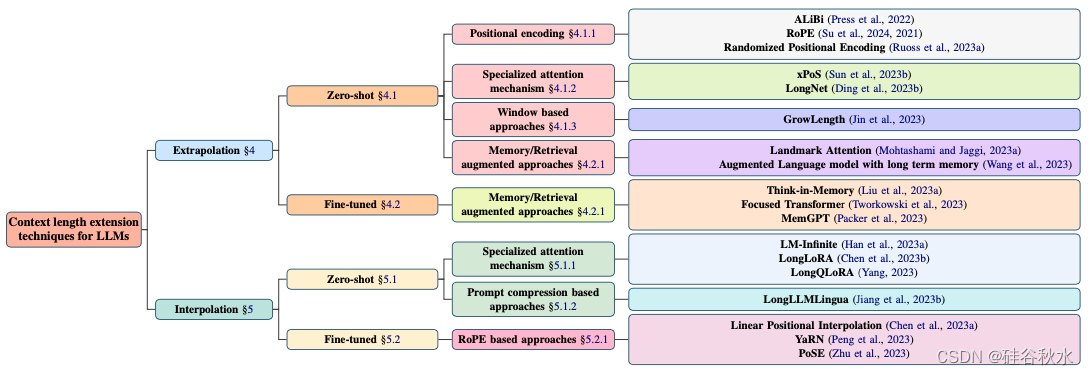
如图RoPE(Su et al., 2024),它使用旋转矩阵来捕获tokens序列中精确的绝对位置信息。 以不同的速度旋转Q和K投影矩阵的片段,RoPE 可确保独特的旋转,从而影响注意分数。 该图强调 RoPE 对相对距离的依赖,以改善自注意模型中tokens关系的理解。
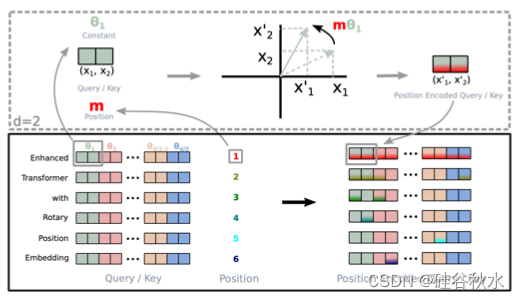
如图是ALiBi 的实施(Press,2021b)。 在神经网络中计算注意时,在应用 softmax 函数之前为每个注意分数添加固定偏差。 对于特定头的所有注意分数,这种偏差都是相同的。 其余计算保持不变。 变量“m”是特定于每个注意头的常量,并且在训练期间设置而不进行调整。 这种方法适用于不同类型的文本、各种模型和不同的计算资源。
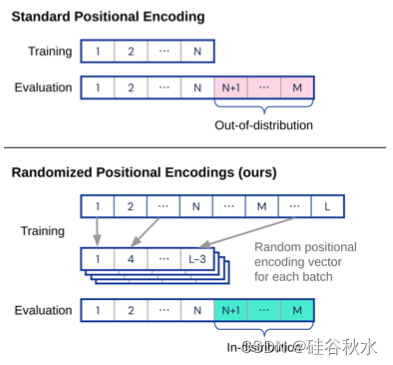
如图是随机位置编码的实现(Ruoss,2023b)。 当测试具有较长输入序列的模型时,添加位置信息的典型方法可能会导致训练期间未见过的值。 方案是分配一个随机(或有序)位置编码向量来解决这个问题,该向量覆盖每个训练样本测试期间可能位置的整个范围。
2 特殊注意机制
注意机制是关键工具,对输入序列不同部分的重要性进行细致的分配。 这些技术使模型能够动态地关注输入中的特定区域,适应上下文信息的不同重要性。 通过将不同级别的注意分配给序列的不同部分,这些机制增强模型辨别和捕获相关上下文的能力,这对于需要理解跨多样和扩展上下文依赖关系的任务至关重要。
长度可外推Transformer:xPos(Extrapolatable Position Embedding)
LongNet
如图实现块级因果注意,使用因果掩码对类似于常规 Transformers 的短文本进行训练。 对于测试期间较长的序列,采用块因果注意,它可以有效地重用重叠部分,例如K和V向量(Sun,2022)。所提出的策略共同构成长度可外推 Transformer 的框架,提供一种改进 Transformer 模型中长度外推的综合方法。
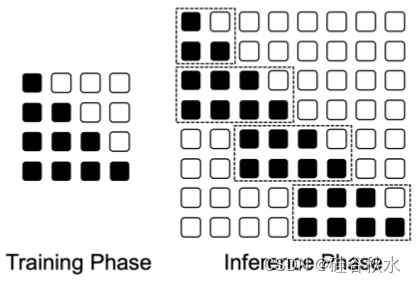
如图是实施的扩张注意。 LONGNET(Ding et al., 2023a)神经网络中扩展注意的基本组成部分是旨在捕获短期和长期依赖关系的注意模式。 网络可以根据输入序列的长度调整注意模式的数量。
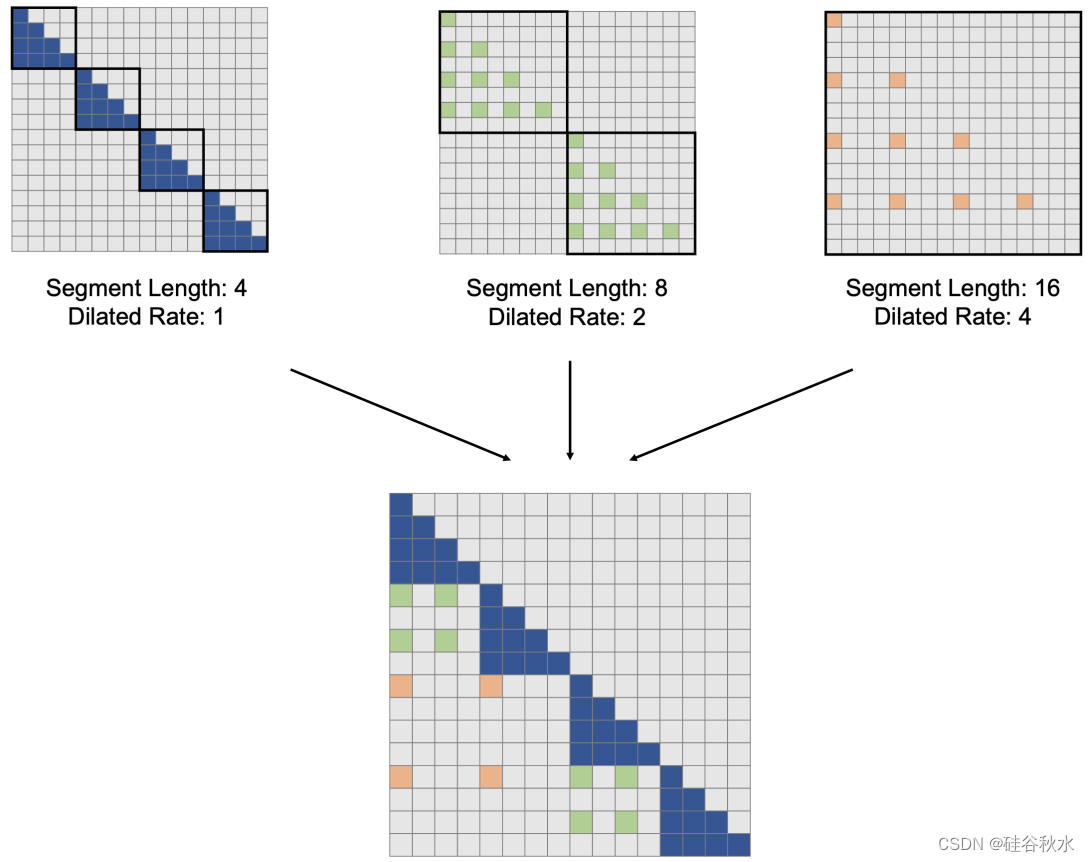
3 基于窗的方法
在推进LLM领域,一系列技术在预训练阶段逐步延长训练长度来提高计算效率。 这种策略性的调整可以作为一种通用的解决方案,解决平衡模型复杂性和计算成本的永久挑战。 通过系统地增加训练长度,这些技术提高了效率,使模型能够掌握扩展的上下文细微差别,而无需施加过度的计算成本。
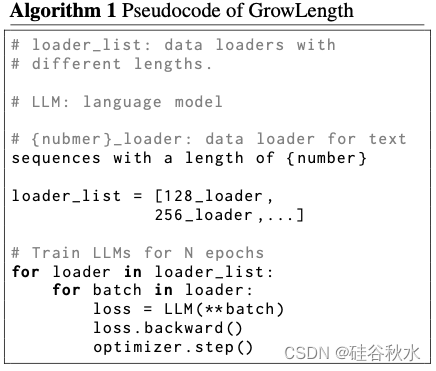
GrowLength
如下是GrowLength的算法总结:
4 记忆/搜索增强方法
记忆增强架构作为一个关键类别出现,引入创新策略来增强模型的扩展上下文理解能力。 这些方法结合了外部存储模块或机制,为模型提供了在更广泛的背景下存储和检索信息的能力。 通过赋予模型某种形式的外部存储器,这些架构努力增强即时上下文窗口之外的信息的保留和利用。
地标注意 Landmark Attention
长时记忆增强的语言模型 LONGMEM(Augmented Language Model with Long Term Memory)
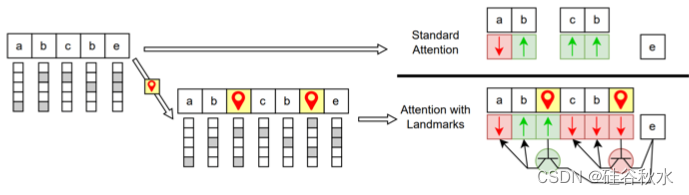
如图比较标准注意和地标注意。 使用 lblock = 2 的块大小,它显示当前tokens对先前tokens的注意如何受到与块对应的K向量和地标向量的相似性影响。 这解释了为什么相同的tokens在不同的块中可以具有不同的注意分数,尽管最初具有相同的表示。 地标tokens最初共享表示,但通过网络层以不同的方式演变,影响注意行为。 (Mohtashami & Jaggi,2023a)
如图是LongMem(Wang,2023)架构概述,其中向现有模型添加单独的内存模块来增强语言模型,有效地使用来自很久以前的上下文信息。 还引入了轻量级 SideNet 来有效地集成内存上下文信息。 图中展示了语言建模问题和 SideNet,并且还描绘了编码、存储、回忆和整合过去记忆以实现更好的语言建模的过程。
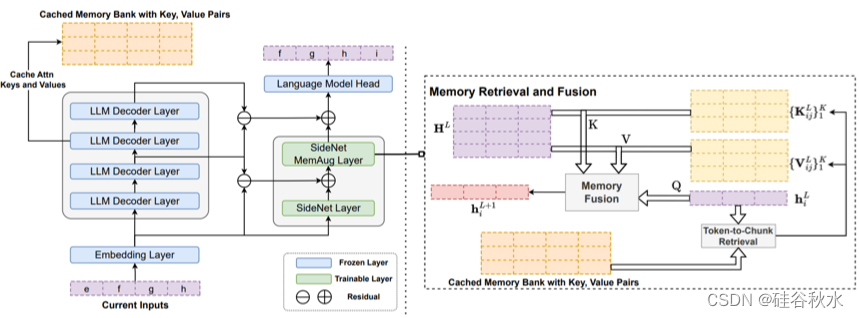
**
微调外推
**
LLM背景下的微调外推法代表了 NLP 领域的复杂演变。 这个过程涉及专门完善模型的现有功能,不仅可以理解而且可以准确生成超出其初始训练数据参数的文本。 与零样本学习(模型利用其预训练的知识而无需进一步调整)不同,微调外推侧重于通过额外的、有针对性的训练来提高模型的熟练程度。 这对于需要高精度生成上下文丰富且细致入微文本的应用程序尤其重要。
通过微调,LLM变得善于处理复杂而冗长的输入,在适应新的内容类型和结构方面表现出非凡的灵活性。 这种增强的能力确保模型可以产生更加连贯、适合上下文和复杂的响应,从而显着提高其在从高级对话界面到综合内容创建等无数场景中的适用性。 微调外推法的出现标志着朝着更加智能、响应灵敏和多功能的语言模型迈出的关键一步,这些模型能够以技巧驾驭人类语言的复杂性。
**
记忆/搜索增强方法
**
TiM(Think-in-Memory)和FOT(Focused Transformer)这两种著名的方法已经出现,解决LLM中扩展有效上下文长度的挑战。 TiM引入动态记忆机制,消除重复推理和增强历史思维,促进长期交互中性能的提高。 另一方面,FOT 采用对比学习启发的训练过程,有效地扩展了注意层中的(K,V)空间,可以访问外部内存。 FOT 通过微调大模型演示其功效,展示在需要更长上下文的任务中的增强性能。 这两种方法都有助于克服与有效上下文长度相关的限制,为优化现实应用中的LLM提供通用的解决方案。
TiM(Think-in-Memory)
FOT(Focused Transformer)
MemGPT
如图是训练过程中 Focused Transformer 的概述(Tworkowski,2023)。 FOT 结合了记忆注意层并采用交叉批量训练方法。 记忆注意层允许模型在推理过程中从附加上下文中访问信息,从而有效地扩展上下文。
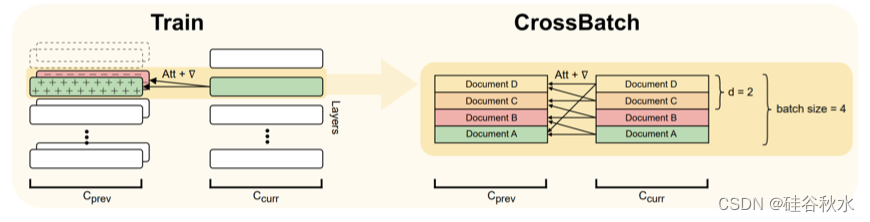
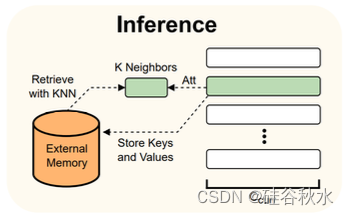
如图是推理期间的 Focused Transformer 概述(Tworkowski,2023)。 在推理过程中,FOT 中的记忆注意层有助于从扩展上下文中检索信息,从而增强模型的理解。 这是模型训练阶段在交叉批次训练过程指导下学习的(K,V)表示来实现的。 该过程鼓励模型获取与记忆注意层特别兼容的表示,从而优化其利用较长上下文信息的性能。
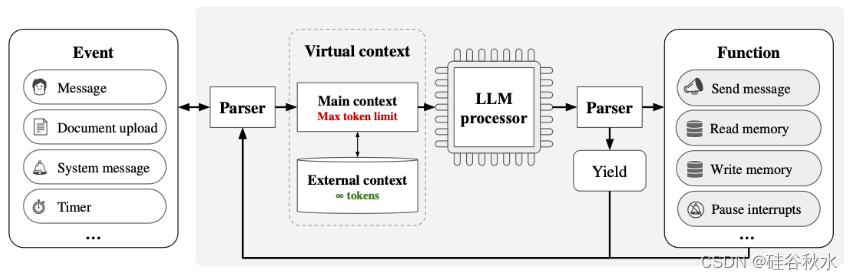
如图是MemGPT 的组成部分(Packer,2023)。 在 MemGPT 中,固定上下文语言模型通过分层记忆系统得到增强。 处理器管理其记忆,使用函数在主上下文和外部上下文之间传输数据。 它通过解析器生成文本,产生或进行函数调用,并预先请求链接函数的控制。 处理器在生成期间暂停,直到下一个外部事件发生。
另一方面,插值技术专注于改进模型的能力,以平滑地扩展其对观察范围内上下文的理解,从而增强在最初遇到上下文长度内序列的性能。
上下文长度外推上下文中的插值技术侧重于微调或优化模型,以有效地处理训练期间遇到的上下文长度范围内的序列。 重点是完善模型在观察范围内平滑扩展其对上下文的理解的能力,从而增强其在最初遇到上下文长度内序列的性能。 这些技术有助于在训练限制内更细致地、更好地理解上下文,确保模型在训练期间所接触的上下文长度内实现最佳性能。
**
零样本
**
插值技术的微调外推,涉及调整预训练的语言模型来处理初始训练期间未遇到的较长输入序列。 在对指定长度范围内的序列(插值)进行初步训练后,模型会经历微调过程以提高其在较长序列上的性能。 这种适应提高了模型泛化到扩展上下文的能力,确保无缝处理最初观察的和推断的输入长度。
对于插值,模型通常在观察的上下文长度内进行微调或优化。 在这种情况下,零样本外推法评估模型在较长序列上的表现,而无需对这些长度进行任何特定的调整。 这需要评估模型对未明确属于其训练数据的上下文长度进行零样本泛化。
1 特殊注意机制
LM-Infinite (Han et al., 2023b),一种提出 Λ- 形注意掩码和动态长度泛化距离限制的解决方案; LongQLoRA (Yang, 2023),一种结合位置插值 (Chen, 2023a)、QLoRA (Dettmers, 2023) 和 Shift Short Attention (Chen, 2023b) 的有效方法,用于用最少的训练资源扩展上下文长度; LongLoRA(Chen,2023b)是一种微调方法,可以有效扩展上下文大小,同时保持与现有技术的兼容性。 这些论文共同促进了特殊注意机制的进步,旨在减轻LLM中零样本上下文长度外推的挑战。
LM-Infinite (Han et al., 2023b)
LongLoRA (Chen et al., 2023b)
LongQLoRA (Yang, 2023)
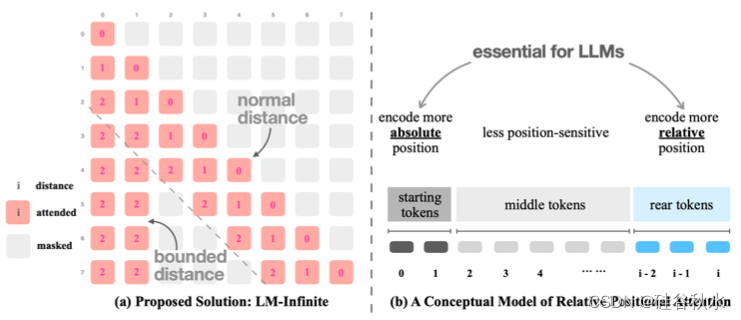
如图是LM-Infinite (Han et al., 2023b) 针对不同 LLM 的易于使用增强,涉及 Λ -形掩模和注意期间的距离约束。 此外,还提供一个概念模型来解释如何描述相对位置编码功能。
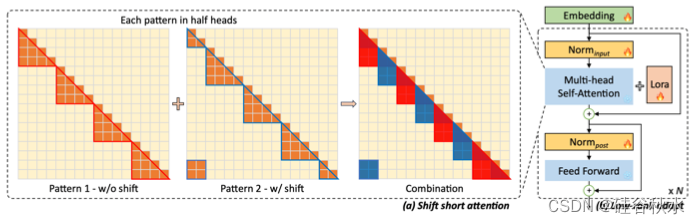
如图是LongLoRA(Chen,2023b)设计概述。 在微调过程中加入了shifted sparse attention(S2-Attn),而训练后的模型在推理过程中保持其原始的标准自注意。 除了线性层中的 LoRA 权重之外,LongLoRA 还使嵌入层和归一化层可训练来扩展训练。 此扩展对于扩展上下文至关重要,并且它仅引入最少数量的额外可训练参数。
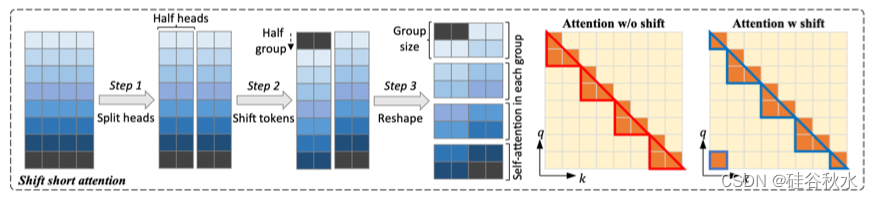
如图是shift short attention示意图。 它涉及三个步骤,特征沿着头维度分成两个块。 一个块中的tokens移动了组大小的一半,然后对tokens进行分组和重整形。 注意是在每个组内计算的,组间信息流通过转移(Chen,2023b)。
2 基于提示压缩方法
提示压缩技术构成了LLM上下文长度外推领域内的一个关键探索领域。 由于LLM的目标是处理更长的输入序列或生成扩展的输出,因此有效处理广泛提示的挑战就摆在了首位。 提示压缩技术侧重于从冗长的提示中提取基本信息的策略,同时保持输入的完整性和相关性。 这些方法旨在使LLM能够有效地管理扩展上下文,而不牺牲计算效率。
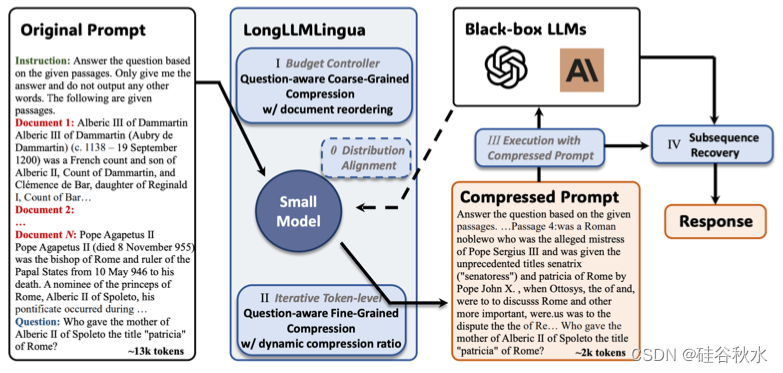
LongLLMLingua
如图LLMLingua(Jiang,2023a)提示压缩的说明:引入用于动态压缩分配的预算控制器,在演示级应用粗粒度压缩,详细说明用于知识保留的迭代提示算法,并引入对齐以解决紧凑型和黑盒模型之间的分配差距。
**
微调
**
插值技术的微调外推涉及调整预训练的语言模型来处理初始训练期间未遇到的较长输入序列。 在对指定长度范围内的序列(插值)进行初步训练后,模型会经历微调过程以提高其在较长序列上的性能。 这种适应提高了模型泛化到扩展上下文的能力,确保无缝处理最初观察的和推断的输入长度。
基于RoPE的方法
线性位置内插 Linear Positional Interpolation
YaRN(Yet another RoPE extensioN)
PoSE(Positional Skip-wisE)
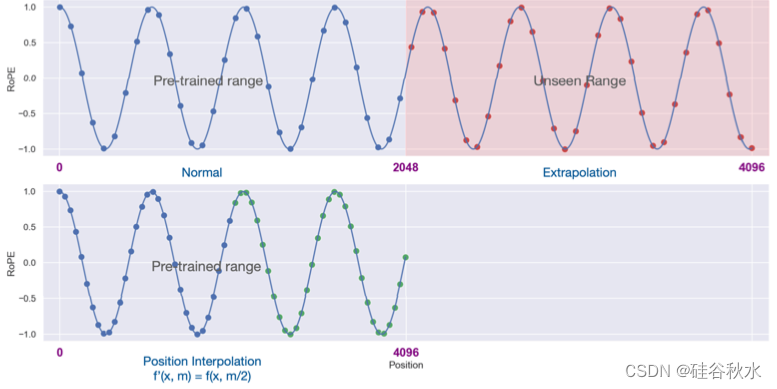
如图是位置插值(Chen,2023a)方法。 对于具有 2048 个位置预训练上下文窗口的 Llama 模型,左上角显示标准用法。 在长度外推(右上)中,模型处理最多 4096 个看不见的位置(红点)。位置插值(左下)将位置索引(蓝色和绿点)从 [0, 4096] 缩小到 [0, 2048], 使它们保持在预训练的范围内。
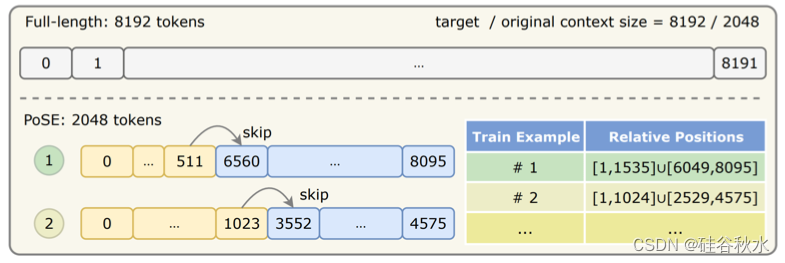
如图是全长度微调与 PoSE(Zhu et al., 2023)微调的图示,用于将上下文从 2,048 个tokens扩展到 8,192 个tokens。 全长度微调直接使用全部 8,192 个tokens,而 PoSE 通过独特的跳偏差项调整 2,048 个tokens的位置索引。 这使得模型在微调时能够适应不同的相对位置。
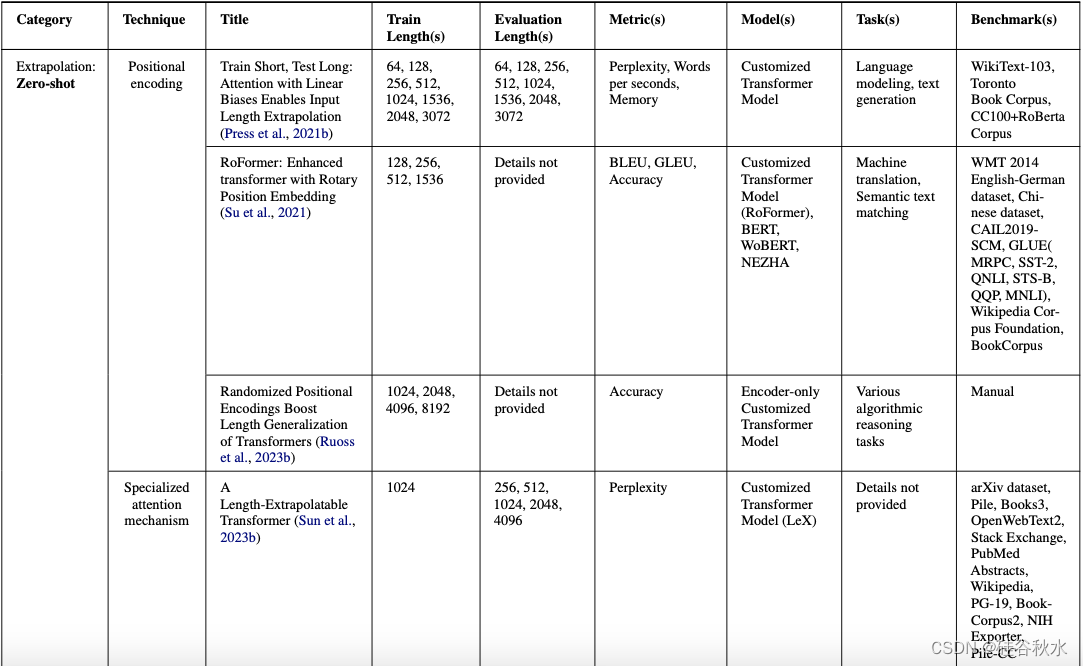
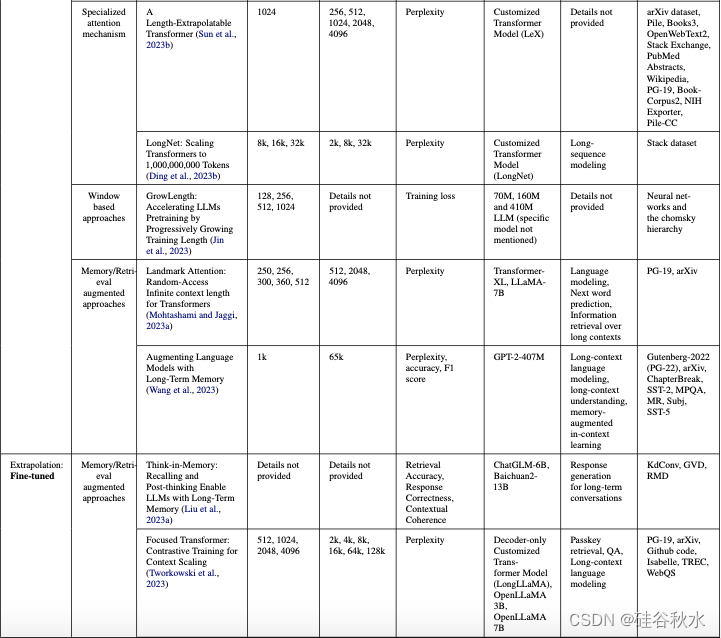
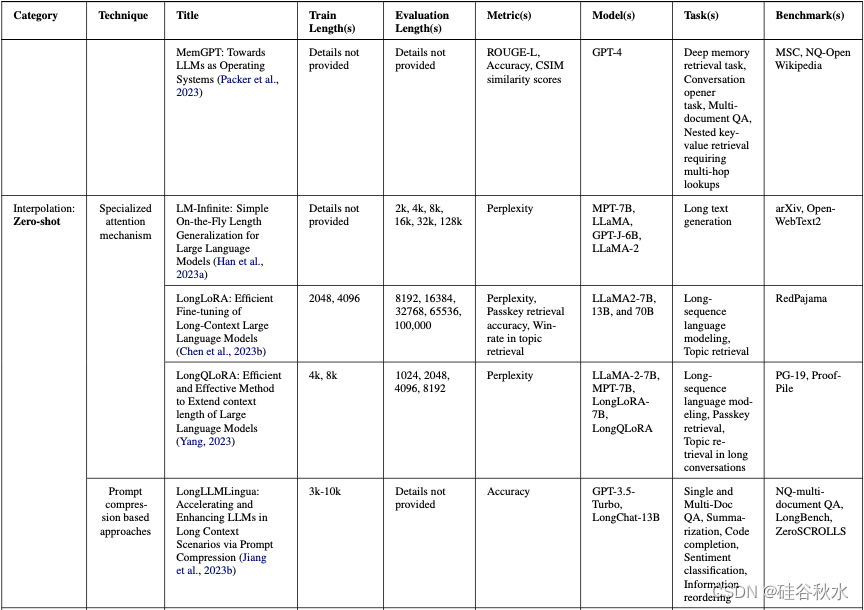
下表是与上下文长度扩展技术相关所有工作的总结。 按以下因素划分每项工作:1. 技术,2. 训练长度,3. 评估长度,4. 指标,5. 模型,6. 任务,和 7. 基准。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









