










机器人技术的一大挑战是打造一个通用机器人,使其能够根据任意用户命令在非结构化环境中执行多种任务。这一努力的关键挑战是泛化:机器人必须应对新环境,识别和操纵从未见过的目标,并理解从未被要求执行的命令意图。从像素进行端到端学习,是建模此类通用机器人行为的灵活选择,因为对世界状态表示的假设很少。有了足够的现实世界数据,这些方法原则上应该能够使机器人在新的任务、物体和场景中进行泛化,而无需手工编码、特定于任务的表示。然而,实现这一目标通常仍然难以实现。
泛化需要目标任务拥有足够多样化的数据集,而收集这些数据集的成本可能高得令人望而却步。在计算机视觉等其他领域,通常利用共享的可重用数据集(例如 ImageNet)来克服这一挑战,但这在机器人技术领域已被证明难以实现。
基础模型通过在大型多任务机器人数据集上训练多任务“通才”模型,在实现可泛化行为方面展现出巨大潜力。大多数研究采用大视觉语言模型来直接预测动作,但是不同具身实体的差距还是限制了模型的泛化。
为了利用更容易获取的来源扩大数据收集,视觉和机器人社区一直致力于从人类视频中学习有意义的行为和模式。一些研究侧重于学习模拟器,这些模拟器使用生成模型从人类视频中紧密模拟机器人的真实环境,并使用这些模拟器训练策略,通过预测潜在的未来结果来做出决策。其他研究则使用互联网规模的人类视频来学习更高级的技能或 affordance。
泛化方法分成以下几种:
2.1 数据多样性
2.1.1 真实数据
Bridge Data 【1】是一个大型多领域多任务数据集,其中包含 10 个环境中 7,200 个演示,涵盖 71 个任务,并实证研究这些数据如何提升机器人在新环境中学习新任务的能力。其关键的假设,在于使用包含多任务和多领域的数据集,以便新用户在训练机器人执行新领域新任务时,可以将此数据集纳入训练过程,并从跨任务和跨领域的泛化中获益。
BridgeData v2 【4】是一个大规模机器人操作数据集,其中包含 24 个环境中的 60,096 条轨迹。该数据集包括拾取和放置、推动、清扫、堆放、折叠等技能。部分数据包括多个摄像头视图和深度数据,所有数据都包含自然语言标签。
数据集的设计目标,是促进大规模机器人学习的研究。该数据集应支持推广到新任务、环境甚至机构。该数据集还应支持通过目标图像或自然语言指令进行灵活的任务调节。为了支持多任务学习方法的评估,BridgeData v2在每个环境中同时收集了许多可能任务的数据。这确保了策略必须关注任务规范,而不是从观测中推断任务。
2.1.2 模拟数据
ManiSkill 【2】提出一个模拟部件交互环境SAPIEN (“SAPIEN: A simulated part-based interactive environment”)做操作技能基准测试,在全物理模拟器中对不同目标的操作技能进行基准测试。构建 ManiSkill 基准测试的目标,可以最好地描述为通过演示促进从 3D 视觉输入中学习可泛化的操作技能。目标级可泛化操作技能,定义为在对训练目标进行学习后可以泛化到未见过的测试目标操作技能,其中训练目标和测试目标属于同一类别。
下一代的SAPIEN,在ManiSkill2 【3】中发布,其包含 20 个操作任务系列,拥有 2000 多个目标模型和 400 多万个演示帧,涵盖固定/移动基座、单臂/双臂和刚体/软体操作任务,输入数据由全动态引擎模拟。它定义一个统一的接口和评估协议,支持各种算法(例如经典的感知-规划-动作、RL、IL)、视觉观测(点云、RGBD)和控制器(例如动作类型和参数化)。
ManiSkill 3 【8】的工程设计使其能够通过灵活的任务构建 API 轻松支持多种不同类型的任务类别,从而为 GPU 并行机器人模拟提供统一的接口。ManiSkill3支持许多方面的 GPU 并行化,包括模拟 + 渲染、异构模拟、点云 / 体素视觉输入等。其支持的多类别任务包括:桌面操作、移动操作、房间规模的操作场景、四足/人形运动、人形/双手操作、多智体机器人、绘画/清洁、灵巧操作、视觉-触觉操作、经典控制、数字孪生和软体操纵环境。
2.2 数据增强
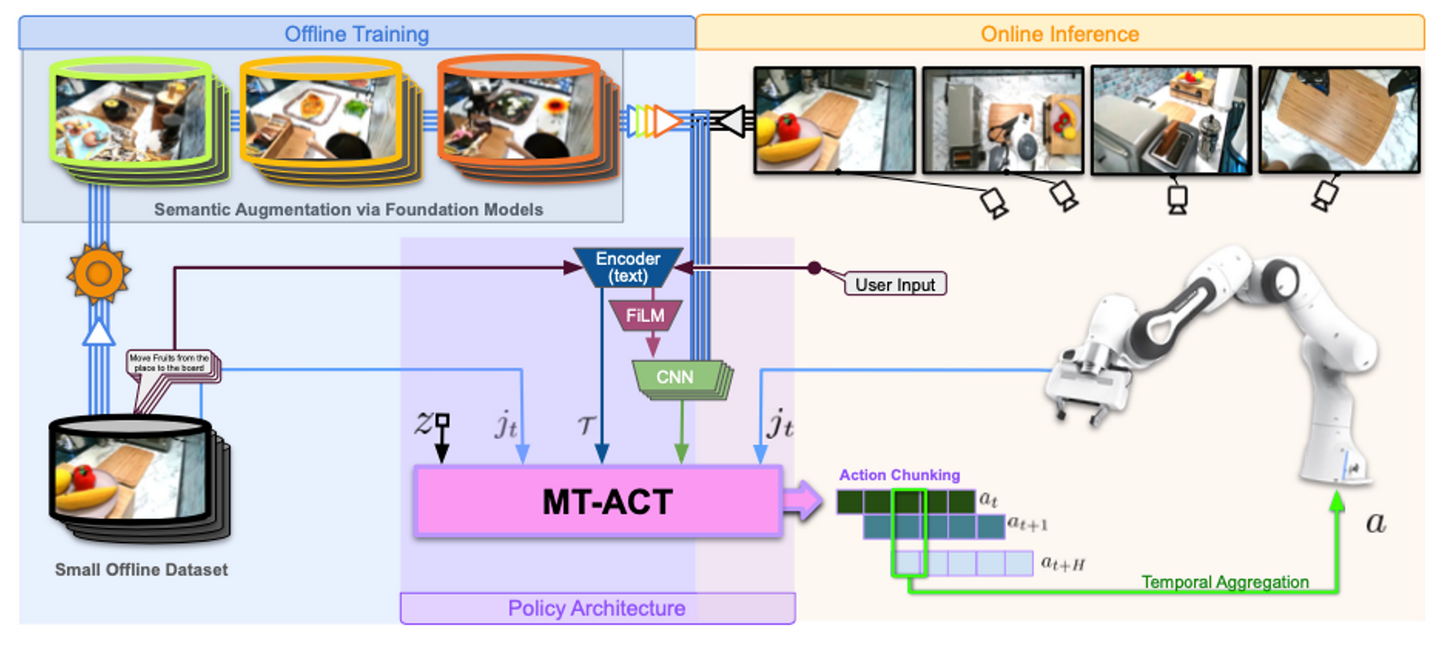
RoboAgent【5】采用 可以快速扩大现有数据集的语义增强和 动作表征,其通过小而多样化的多模态数据集RoboSet提取高性能策略而不会过拟合,训练具有多任务操纵技能的通用智体。其见解在于两个方面:(1)确保通过遥操作收集的数据集(包含 7500 条轨迹)充分覆盖不同场景中的不同技能;通过语义增强,将特定的机器人演示重新创建为多个演示,每个演示都有不同的语义上下文(目标、纹理、背景等),无需额外的人力/机器人成本,即可离线多样化收集的数据集,帮助在新情况下的泛化。(2)用 多任务的模型MT-ACT,能够处理多模态数据分布的多任务ACT,训练语言为条件的操作策略;其中预先收集的小型但多样化数据集RoboSet,确保对不同核心技能的充分覆盖,其中每个技能被定义为导致目标姿势合理变化的时间相关动作序列;示例技能包括关闭/打开铰接目标、滑动、擦拭,每个技能都在一组目标中实例化;将这种(技能,目标)组合称为“任务”,任务在不同的厨房场景中实例化。
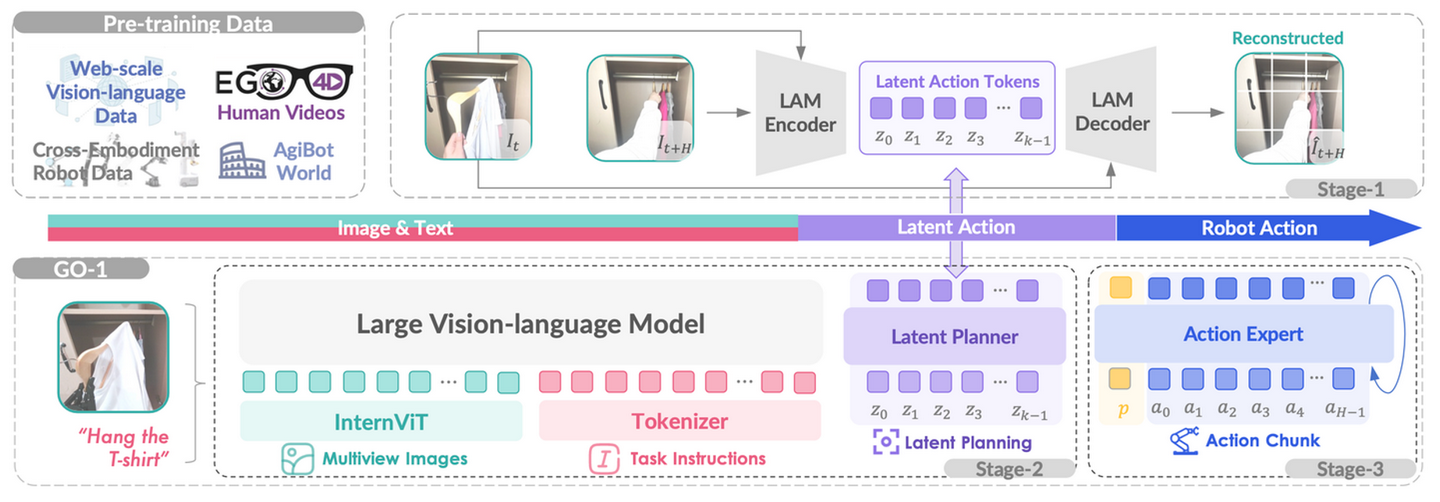
AgiBot World【25】是一个智元机器人公司开放的大型平台,包含五种部署场景中 217 个任务的 100 多万条轨迹,与现有数据集相比,其数据规模实现数量级的增长。通过标准化收集流水线和人机验证加速,AgiBot World 可确保高质量和多样化的数据分布。它可以从夹持器扩展到灵巧手和视觉触觉传感器,以实现细粒度的技能获取。在AgiBot World数据集的基础上,智元机器人 提出提出一个具有三训练阶段的分层视觉-语言-潜变量-动作 (ViLLA) 框架,开发出Genie Operator-1 (GO-1),一种通才机器人策略,它利用潜动作表征来最大化数据利用率,并随着数据量的增加而展示可预测的性能扩展。
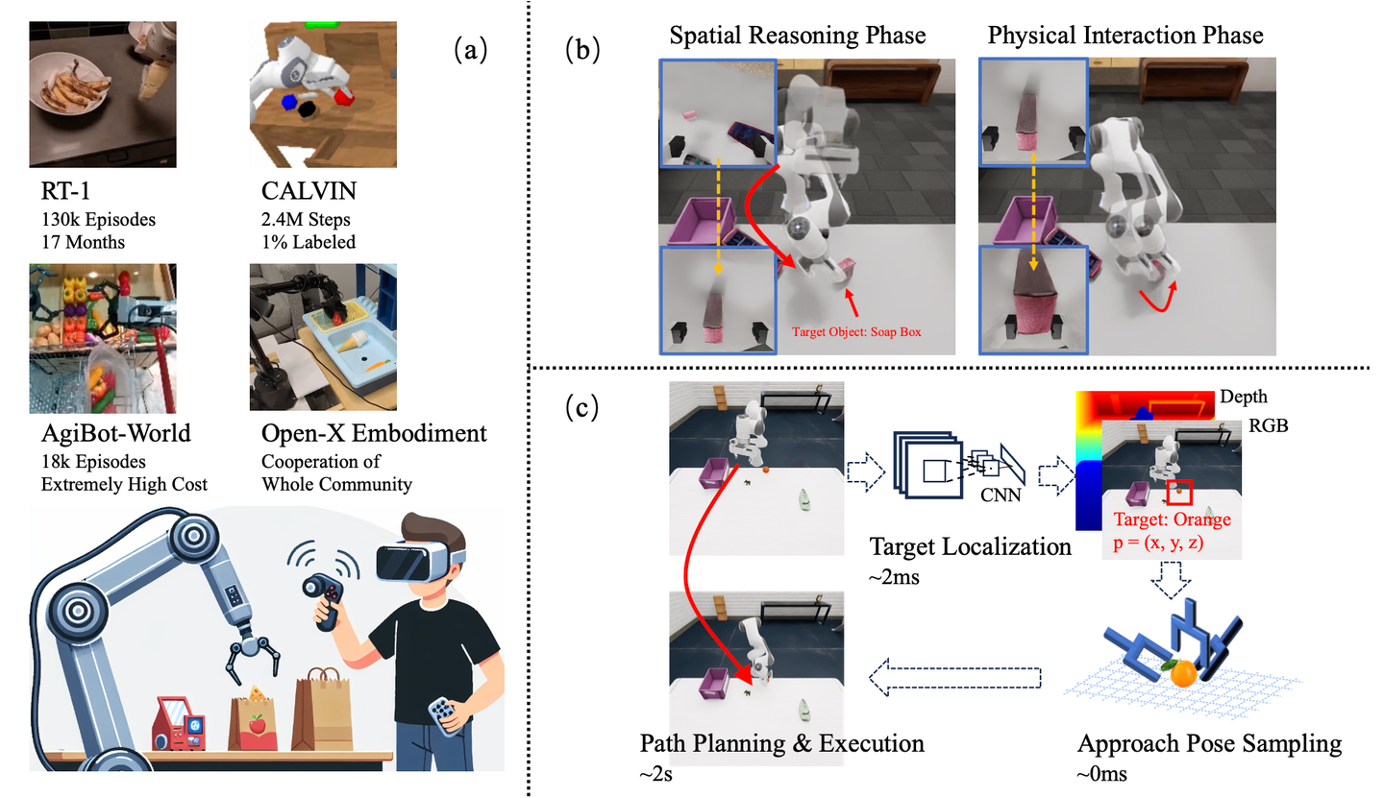
DataPlatter 【29】方法是一种将训练轨迹分解为不同任务阶段的框架,即空间推理阶段(SRP)和物理交互阶段(PIP),并利用大量易于收集的SRP数据来增强 VLA 模型的泛化能力。前一个阶段与目标无关,因为智体会探索广阔的工作空间,而不需要与目标进行任何密切交互,比如在操作前接近目标,这使得数据收集相对简单。相比之下,在后期阶段,需要根据物理定律对目标采取精确的动作,并预见到物体的反应,这对于人类或算法专家来说都是极其耗费人力的。通过分析,使用适当比例的额外 SRP 数据进行子任务特定训练可以作为机器人操作的性能催化剂,最大限度地利用昂贵的物理交互阶段 (PIP) 数据。
2.3 表征/Affordance/奖励学习
RT-Trajectory【6】是一种使用粗略轨迹草图(sketches)的策略条件方法,允许策略有效地执行原本难以执行的新任务。在足够详细以表达低级运动为中心的指导与足够粗糙以允许学习策略在情境视觉观察的上下文解释轨迹草图之间,轨迹草图可以取得平衡。
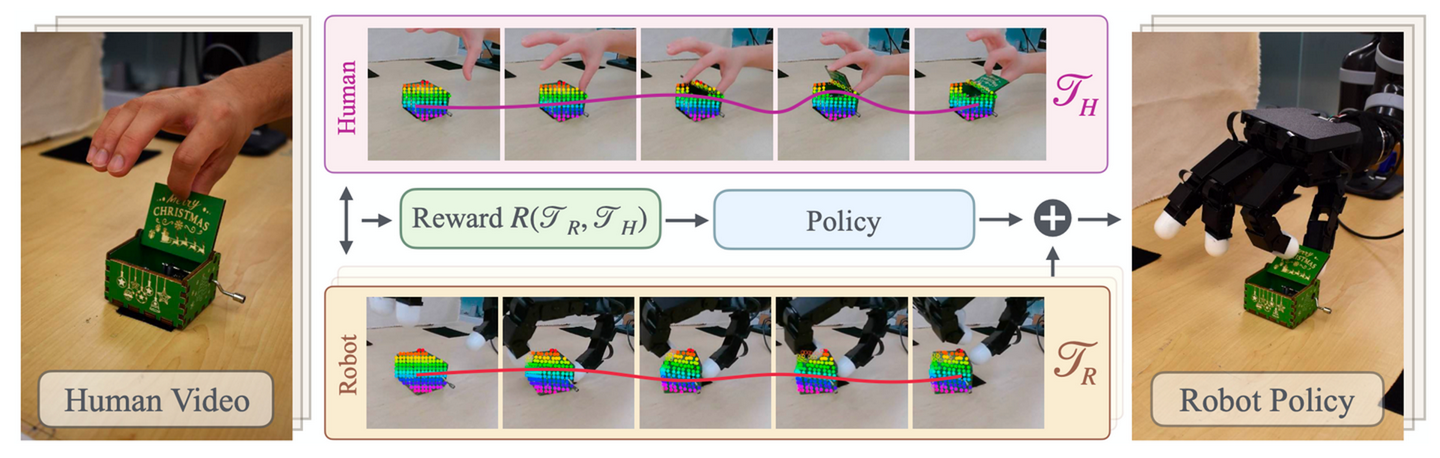
由于人-机形态差异以及视频中手势估计的误差,即使目标位于同一位置,单纯地在机器人上重放重定位的指尖轨迹通常也无法成功完成任务。为了缓解这个问题,利用强化学习 (RL) 来学习一种在线残差策略,以增强轨迹重放。HUDOR 【12】是一种面向目标的奖励学习技术,它能够通过直接从人类视频中计算奖励来在线微调策略。重要的是,该奖励函数基于从现成的点跟踪器中获取的面向目标轨迹构建,即使人手和机械手之间存在形态差异和视觉差异,也能提供有意义的学习信号。
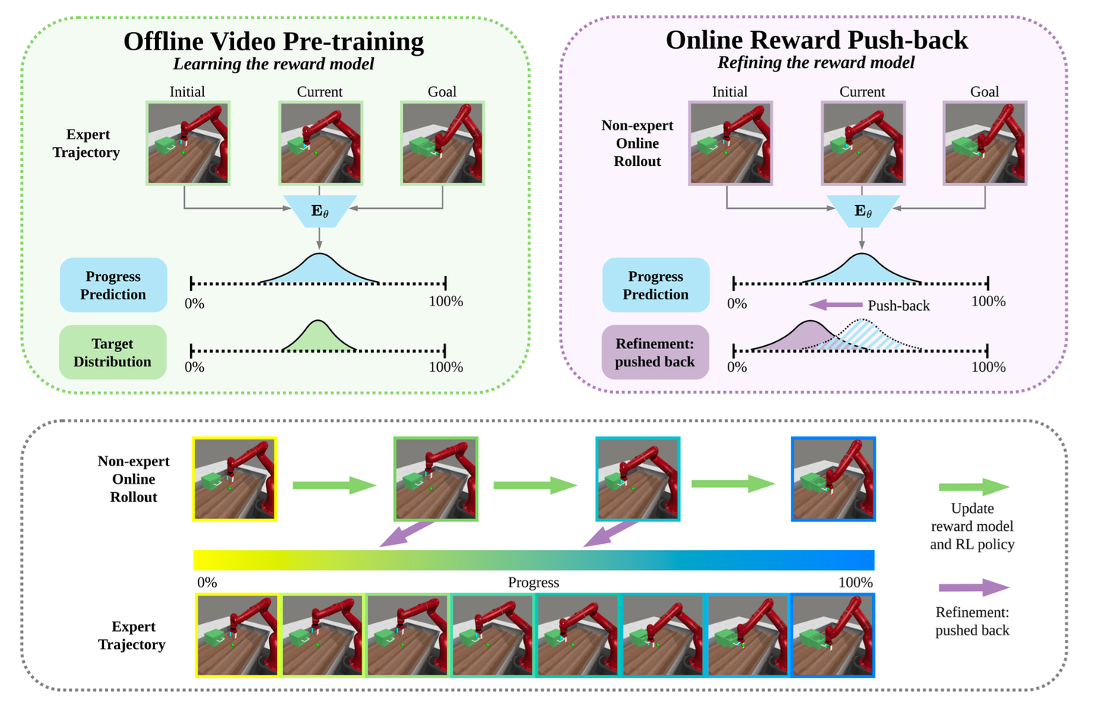
PROGRESSOR【14】是一个从视频中学习与任务无关的奖励函数,从而能够在无需人工监督的情况下,通过目标条件强化学习(RL)进行策略训练。该奖励的基础是对任务进度分布的估计,该估计是当前、初始和目标观测值的函数,并以自监督的方式学习。在线 RL 训练过程中,PROGRESSOR 是对抗性地反推分布外(OOD)观测值预测来优化奖励的,以减轻非专家观测值固有的分布漂移。通过将进度预测作为密集奖励,并结合对抗性反推,PROGRESSOR 能够使机器人在无需任何外部监督的情况下学习复杂的行为。
OmniManip 【17】是一种开放词汇操作方法,它弥合视觉语言模型(VLM)的高级推理与低级精度之间的差距,具有规划和执行方面的闭环能力。其提出一种以目标为中心的表征,目标的规范空间由其功能 affordance 定义,提供一种结构化且语义上有意义的方式来描述交互原语,例如点和方向。这些原语充当桥梁,将 VLM 的常识推理转化为可操作的 3D 空间约束。在此背景下,引入双闭环:一个闭环用于通过原始重采样、交互渲染和 VLM 检查进行高级规划,另一个闭环用于通过 6D 姿势跟踪进行低级执行。这种设计确保强大的实时控制,而无需 VLM 微调。
机器人动作表示为图像上的短视域二维轨迹。这些动作,或Motion Tracks,捕捉人手或机器人末端执行器的预测运动方向。实例化一种名为运动轨迹策略 (MT-π) 的 IL 策略【18】,它接收图像观测并将运动轨迹输出为动作。通过利用这个统一的跨具身动作空间,MT-π 仅需几分钟的人类视频和有限的额外机器人演示就能成功完成任务。在测试时,从两个摄像头视角预测运动轨迹,并通过多视角合成恢复六自由度轨迹。
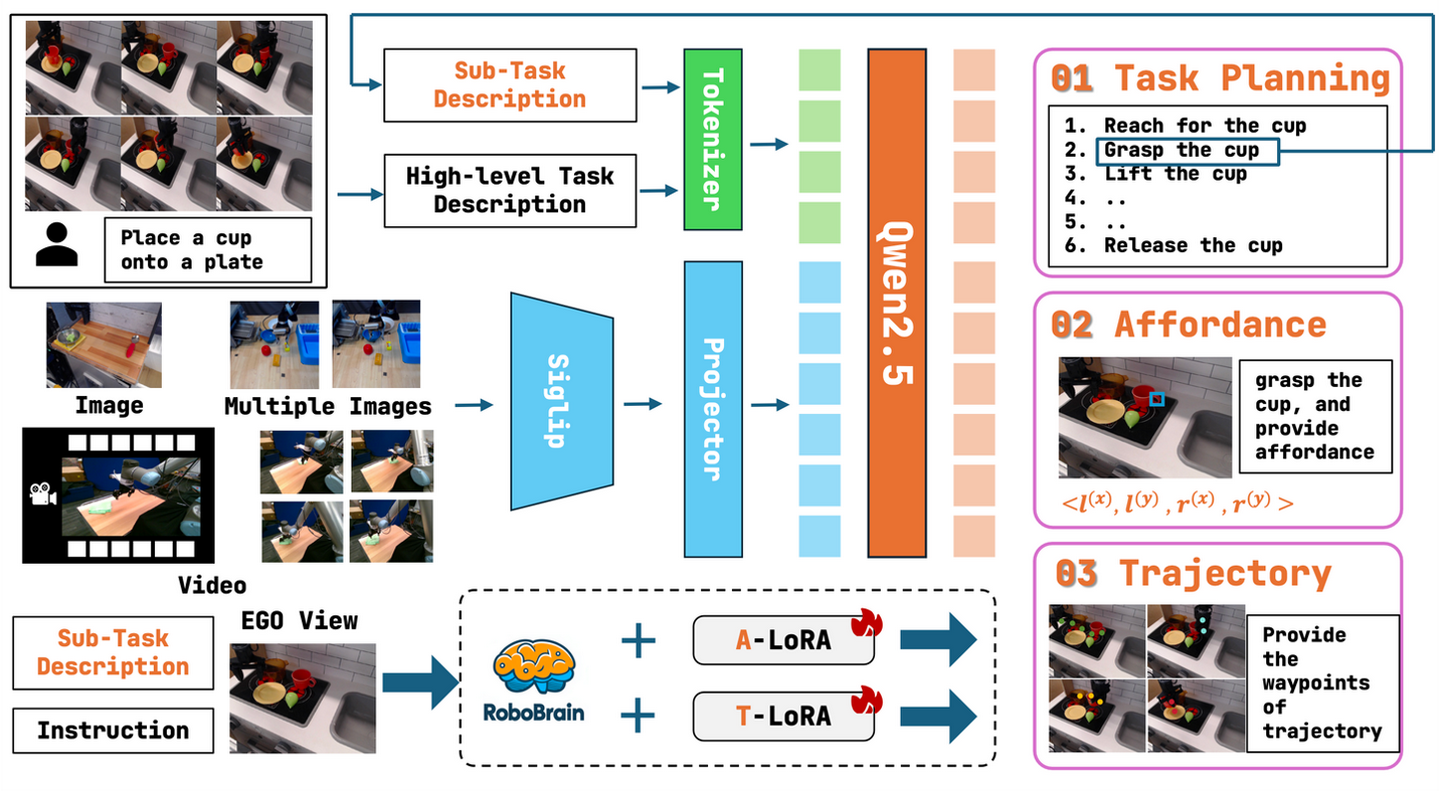
RoboBrain【23】是一个基于 MLLM 的模型,它结合机器人和通用多模态数据集ShareRobot,采用多阶段训练策略,并结合长视频和高分辨率图像来提高其机器人操控能力。ShareRobot是一个高质量的异构数据集,可标记任务规划、目标affordance和末端执行器轨迹等多维信息。ShareRobot 的多样性和准确性,经过多个人类注释员的改进。
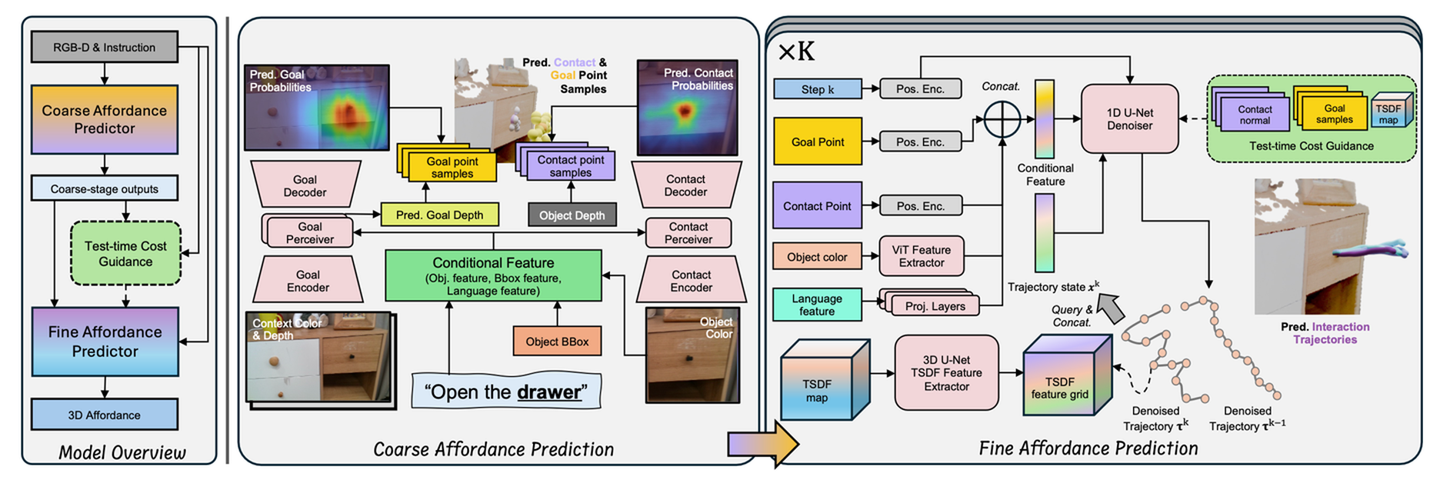
VidBot【26】是一个实现零样本机器人操作的框架,使用从自然单目 RGB 人类视频中学习的 3D affordance。VidBot 利用一个流水线提取显式表征,即来自视频的 3D 手部的轨迹,结合深度基础模型和运动结构技术来重建与具身无关、时间一致、度量-尺度的 3D affordance 表征。其引入一种由粗到细的 affordance 学习模型,该模型首先从像素空间中识别粗略动作,然后利用扩散模型生成细粒度的交互轨迹。该模型以粗略动作为条件,并由测试时间约束引导,用于上下文-觉察的交互规划,从而能够大规模泛化到新的场景和具身。
2.4 共享动作基元
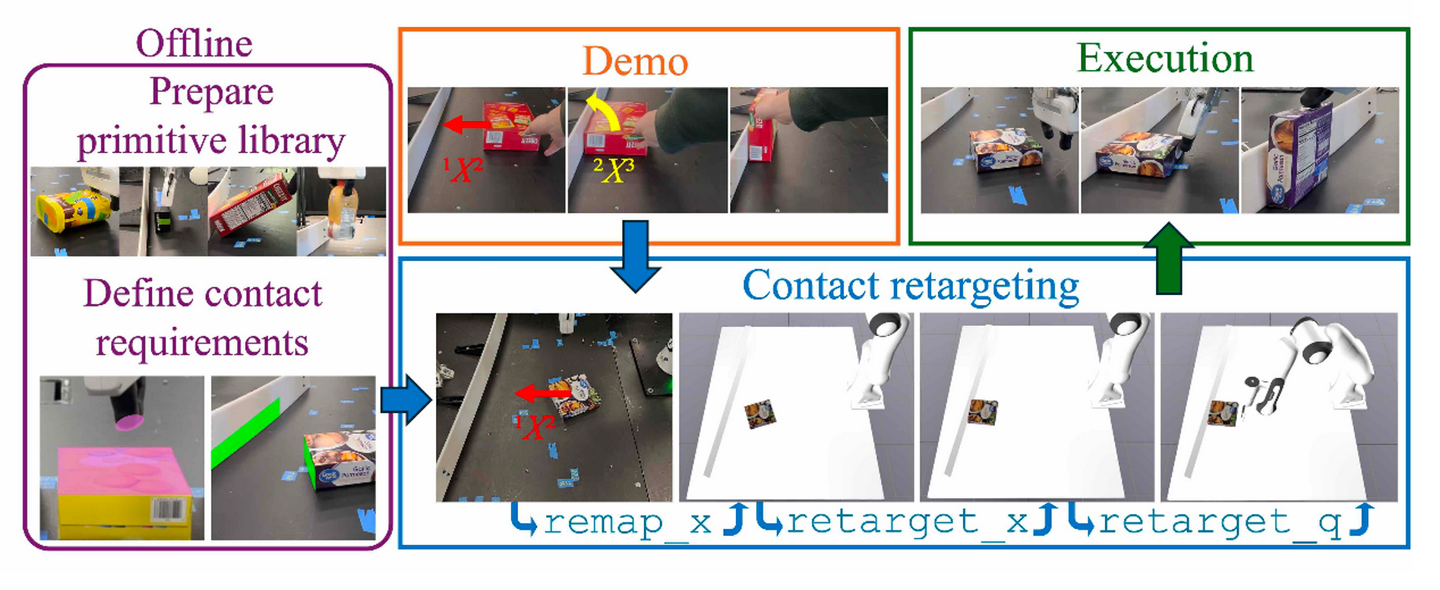
由于场景多样性、动作空间大和接触动力学困难,在机器人、目标和环境之间编排长范围(long-horizon)接触交互序列极具挑战性。斯坦福大学的工作【7】基于这样的看法:大多数外部操纵都是短范围操作基元的组合,每个基元都强烈依赖于从理想的接触配置进行初始化才能成功。因此,通过重定位(retargeting)接触要求,将一种外部操纵轨迹泛化到不同的目标和环境。其建立一个强大的短距离、目标条件基元策略库(目前是4个基元动作,即推、旋转、拉和抓握),并设计一个框架来组成源自每个基元接触规范的状态约束。这样,给定一个测试场景和一个规范基元序列的单个演示,该方法会在测试场景上强制执行状态约束,并使用逆运动学(IK)找到中间目标状态,然后由基元策略跟踪目标。
AnyBimanual【15】引入一个技能管理器,将单手基础模型中的动作策略分解为技能基元,并集成双手系统的基元。它将技能基元与面向任务的补偿线性组合来表示双手操作指令。设计一种无监督的自动技能发现方法,在训练过程中从离线双手操作数据集中学习技能表征及其模式。在测试阶段,技能管理器根据高级语言指令预测不同加权的基元技能组合来协调每只手臂,从而能够将预训练的单手策略有效地迁移到不同的双手操作任务。为了缓解单手和双手系统之间的观察差异,提出一个视觉对齐器,生成用于工作区视觉嵌入的软掩码,旨在将单手策略模型中每只手臂的视觉输入与预训练阶段的视觉输入对齐,从而增强策略可迁移性。
原子技能库(ASL)的构建【20】首先用视觉-语言-规划(VLP)将任务划分为子任务;然后,通过抽象子任务形成原子技能定义。最后,通过数据收集和视觉-语言-动作(VLA)微调构建原子技能库。随着原子技能库通过这三轮更新策略动态扩展,其可覆盖的任务范围自然增长。通过这种方式,该方法将重点从端到端任务转移到原子技能,在保持高性能的同时显著降低数据成本,并能够高效地适应新任务。
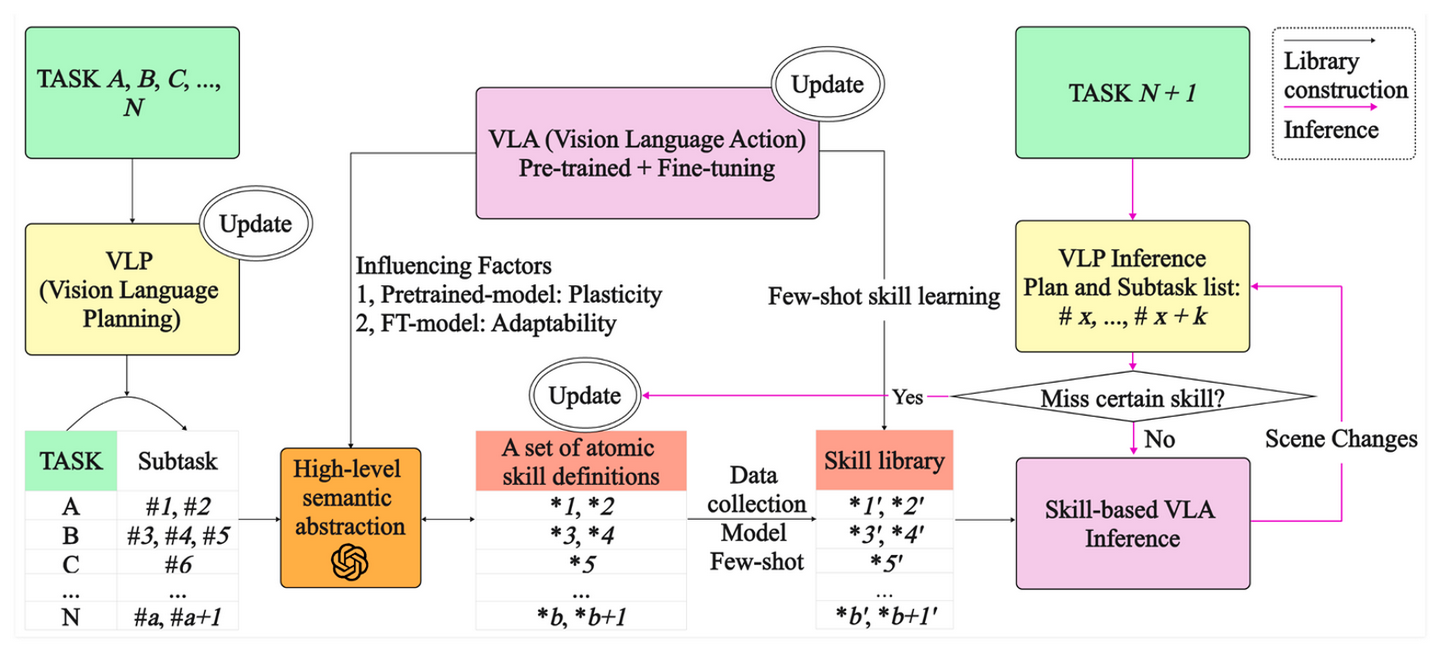
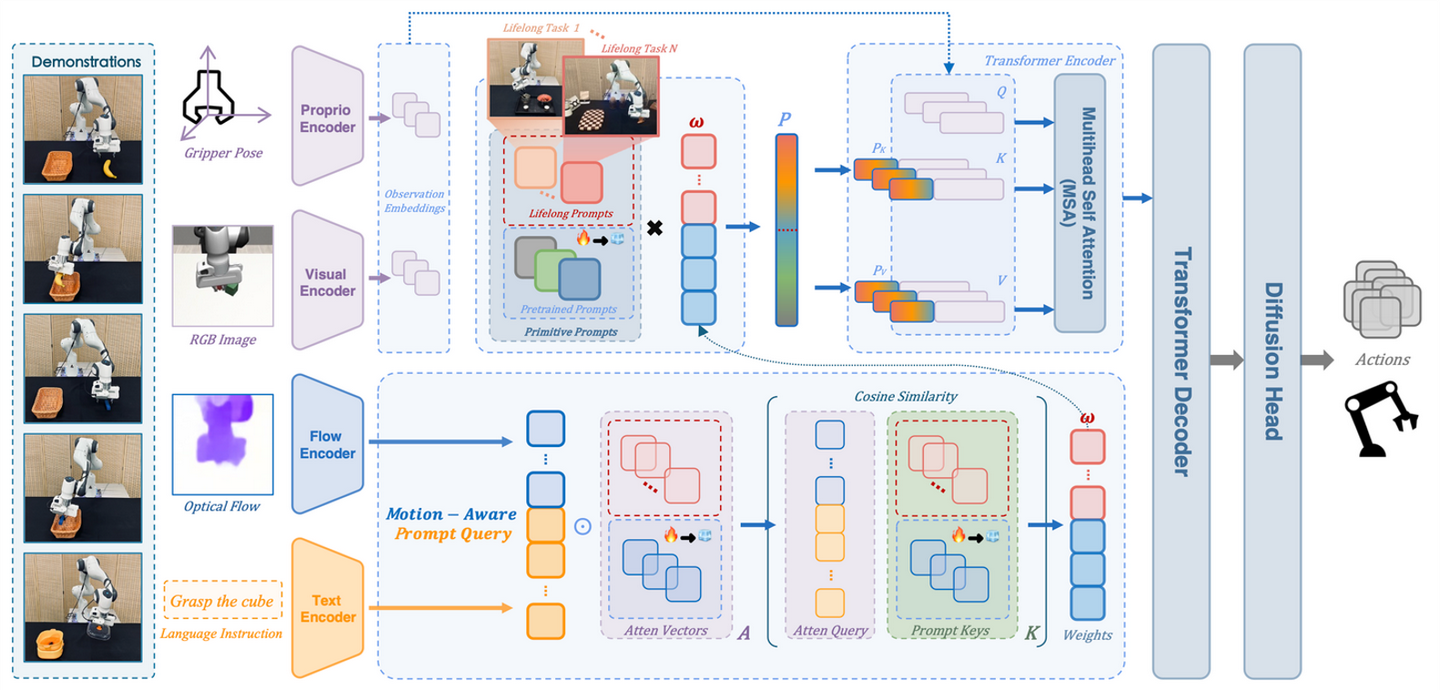
原语提示学习(PPL)【32】通过可重用和可扩展的原语,实现终身机器人操作。在其两阶段学习方案中,首先通过多技能预训练阶段学习一组原语提示来表示共享原语,在此阶段学习运动感知提示来捕获不同技能之间的语义和运动共享原语。其次,在终身获取新技能时,终身提示会附加并使用冻结的预训练提示进行优化,从而通过将知识从旧技能转移到新技能来促进学习。
2.5 统一的动作空间
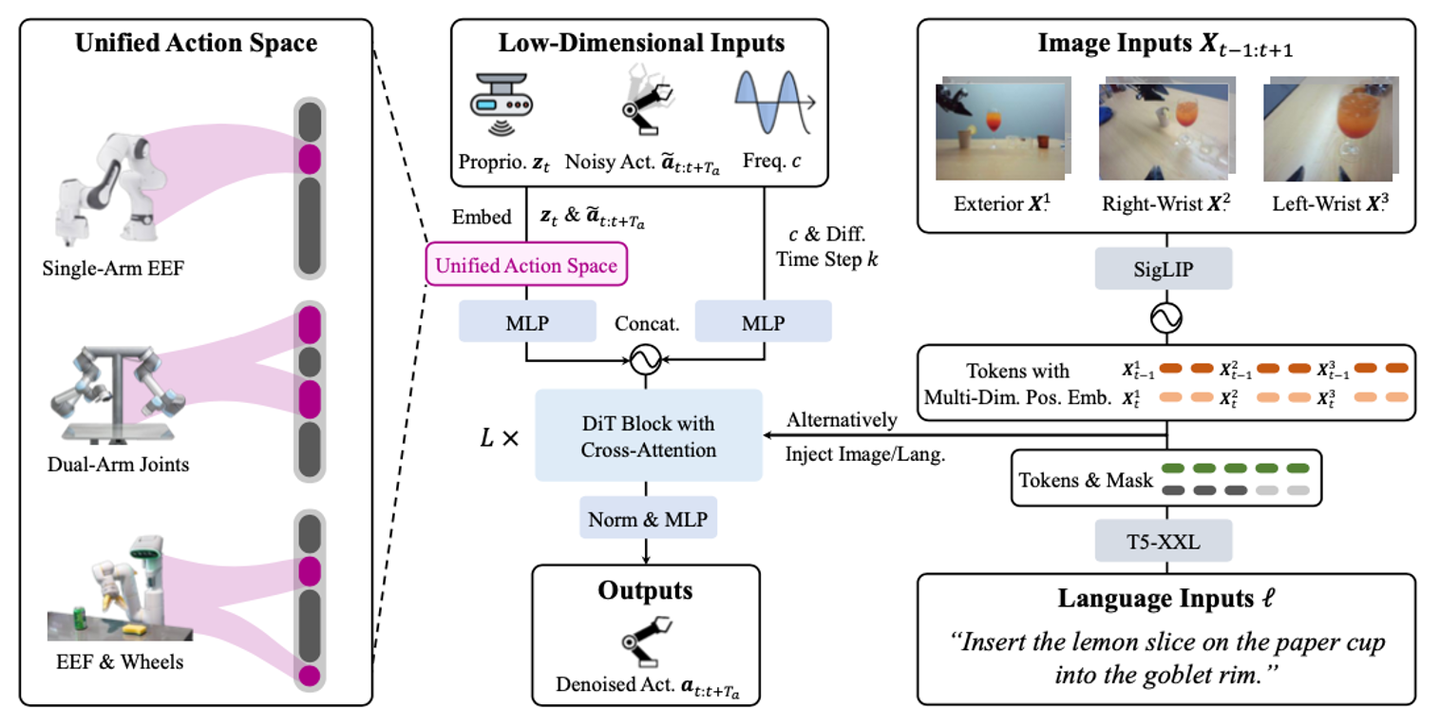
RDT-1B【10】是一种用于双手机器人操作的扩散基础模型。RDT 以扩散模型为基础,有效地表示多模态,以可扩展的Transformer来处理多模态输入的异质性并捕获机器人数据的非线性和高频性。为了能够在异构多机器人数据上进行训练,需要一个在各个机器人之间共享的统一动作空间,该空间可以为多机器人动作提供统一的格式。从机器人的原始动作空间到统一动作空间的映射应该是物理上可解释的,每个维度都应该具有明确的物理意义。这可以鼓励模型从不同的机器人数据中学习共享的物理定律,从而提高从不同机器人数据中学习的效率。
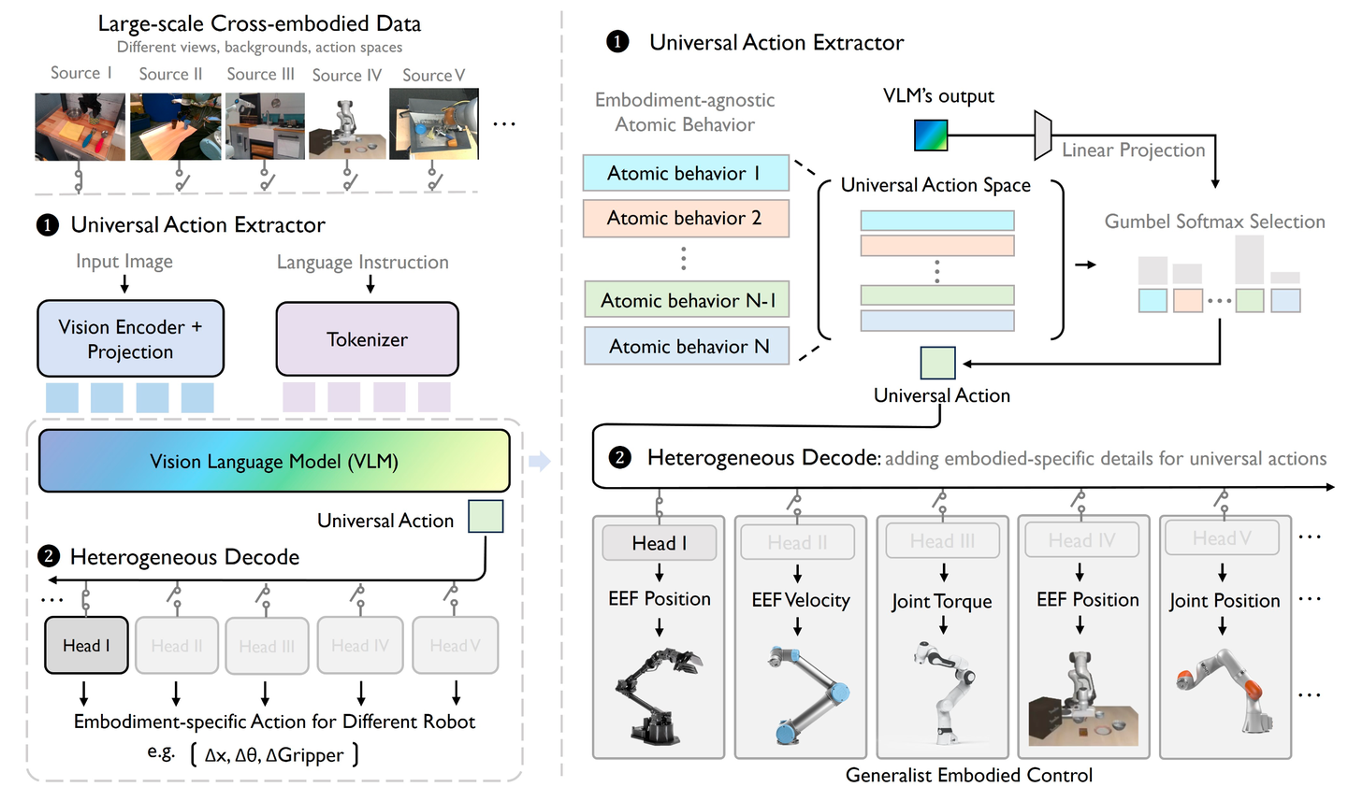
理想的通用动作空间是,所有由来自不同具身、异构控制信号驱动的运动都可以蒸馏为共享的潜原子行为,尽管它们具有不同的物理含义。将这些抽象的行为表示称为通用动作,它们在所有物理具身之间共享。UniAct【19】是一个在token化通用动作空间中运行具身基础建模框架。学习的通用动作,通过利用不同机器人共享的结构特征来捕捉它们之间的通用原子行为,并通过消除异质性来实现增强的跨域数据使用和跨具身泛化。只需添加特定于具身的细节,就可以将通用动作有效地转换回异构可操作命令,从而快速适应新机器人变得简单而直接。
人类动作 Transformer (HAT) 【28】是一种人形机器人行为策略,在统一的以人为中心的状态动作表征空间中预测未来的手指轨迹。首先其收集一个以自我为中心的、面向任务的数据集 PH^2D,该数据集与人形机器人的操作演示直接对齐。然后, HAT 的状态-动作空间对于人类和人形机器人是统一的,并且可以可微分地重定向到机器人动作。通过与小规模机器人数据联合训练,HAT 可以直接将人形机器人和人类建模为不同的具身,而无需额外的监督。人类数据可以显著提高 HAT 的数据收集效率,从而提升 HAT 的泛化能力和鲁棒性。

多模态模型 RoboMM 以及数据集 RoboData【16】一同实现一体化的机器人操作。RoboMM 通过相机参数和占用监督增强 3D 感知。它以 OpenFlamingo 为基础,结合了模态-隔离-掩码和多模态解码器模块,改善了模态融合和细粒度感知。RoboData 通过整合几个著名的数据集提供完整的评估系统,实现了多视角图像、相机参数、深度图和动作的首次融合,空间对齐有利于从不同的机器人数据集中进行全面学习。配备RoboData 和统一的物理空间,RoboMM 变成一种通用策略,可以同时评估多个数据集内的所有任务,而不是专注于有限的数据或任务选择。
2.6 快慢系统的VLA模型
受人类认知 Dual-Process 理论的启发,HiRT【9】 是一种用于 VLA 模型的分层交互式模仿学习框架,可实现灵活的频率和性能权衡。HiRT 利用系统 2 提取高级、缓慢变化的信息,以指导轻量级系统 1 模块。这个由较小模型实现的系统 1 可以对环境变化做出快速反应。尽管轻量级,但 HiRT 中的系统 1 可以利用系统 2 的指导,保持与原始 VLM 相当的性能,同时获得显著的速度提升。这样,HiRT 使 VLM 保持低频运行以捕获暂时不变的特征,同时通过缓慢更新特征引导的高频基于视觉策略实现实时交互。
RoboDual【11】是一种协同双-系统,旨在利用系统 1 和系统 2 的优势并促进大型通才策略的实际部署,它可以补充机器人在通才策略和专家策略两方面的优点。基于扩散Transformer的专家,被设计用于多步动作部署,精确地以基于视觉-语言-动作 (VLA) 的通才策略高级任务理解和离散化动作输出为条件。
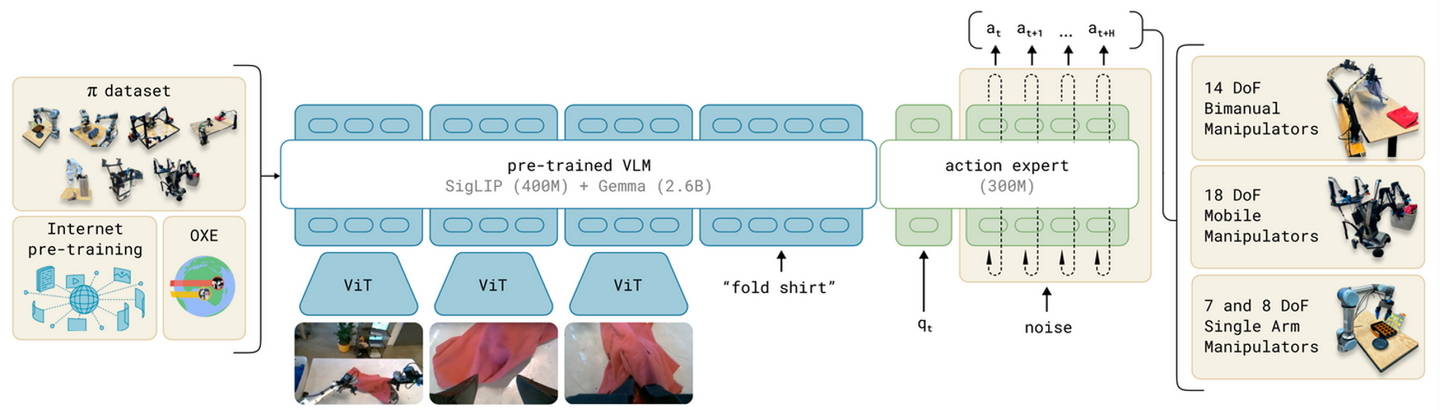
具身智能创业公司 PI 提出一个VLA流模型π0【13】,可以微调视觉-语言模型 (VLM) 以通过流匹配(扩散的变型)产生动作。这样能够处理高频的动作块(高达 50 Hz)和高度灵巧的任务。流匹配为模型提供了高精度和多模态建模能力,使其特别适合高频灵巧任务。π0使用预训练的VLM主干,以及具有各种灵巧操作任务的多样化跨具身数据集。添加单独的动作专家,其通过流匹配产生连续动作,这样模型可适应机器人控制,从而实现精确流畅的操作技能。然后,该模型可直接用于基于一个提示执行任务,或根据高质量数据进行微调,实现复杂的多步任务。
LMM-3DP【21】是一个可以整合 LMM 规划器和 3D 技能策略的智体框架。该方法包括三个关键角度:高级规划、低级控制和有效集成。对于高级规划,LMM-3DP 支持对环境干扰的动态场景理解、具有自我反馈的批评智体、历史策略记忆和失败后的重试。对于低级控制,LMM-3DP 利用语义感知的 3D 特征场进行精确操作。在协调机器人动作的高级和低级控制时,代表高级策略的语言嵌入与 3D Transformer 中的 3D 特征场共同参与,以实现无缝集成。
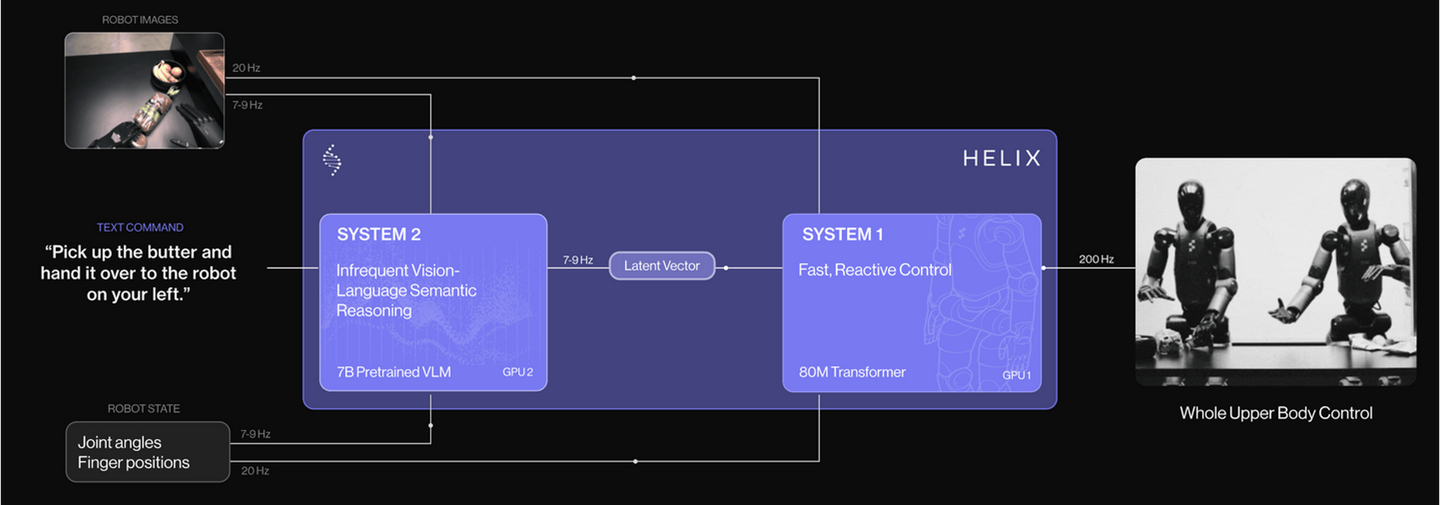
Helix 【24】是Figure.AI公司开发的一种通才视觉-语言-动作 (VLA) 模型,它将感知、语言理解和学习控制统一起来。Helix 是一个“系统 1、系统 2” VLA 模型,用于高速、灵巧地控制整个人形机器人上半身。Helix 通过两个互补的系统解决慢思考和快反应的权衡,这两个系统经过端到端的训练,可以进行通信:系统 2 是一个机载互联网预训练的 VLM,以 7-9 Hz 运行,用于场景理解和语言理解,实现跨目标和上下文的广泛泛化;系统 1 是一种快速反应的视觉运动策略,可将 系统2 产生的潜语义表征转换为 200 Hz 的精确连续机器人动作。这种解耦架构,允许每个系统在其最佳时间尺度上运行。
Being-0【27】是一个集成基础模型(FM)和模块化技能库的分层智体框架。基础模型负责处理指令理解、任务规划和推理等高级认知任务,而技能库则为低级控制提供稳定的运动和灵巧的操作。为了弥合这些层次之间的差距,提出一个连接器模块,它由轻量级视觉语言模型 (VLM) 驱动。连接器通过将基于语言的规划转化为可操作的技能命令,并动态协调运动和操作来提高任务成功率,从而增强 FM 的具身能力。由于 Being-0 的所有组件(FM 除外)均可部署在低成本的机载计算设备上,因此它能够在配备灵巧手和主动视觉的全尺寸人形机器人上实现高效的实时性能。
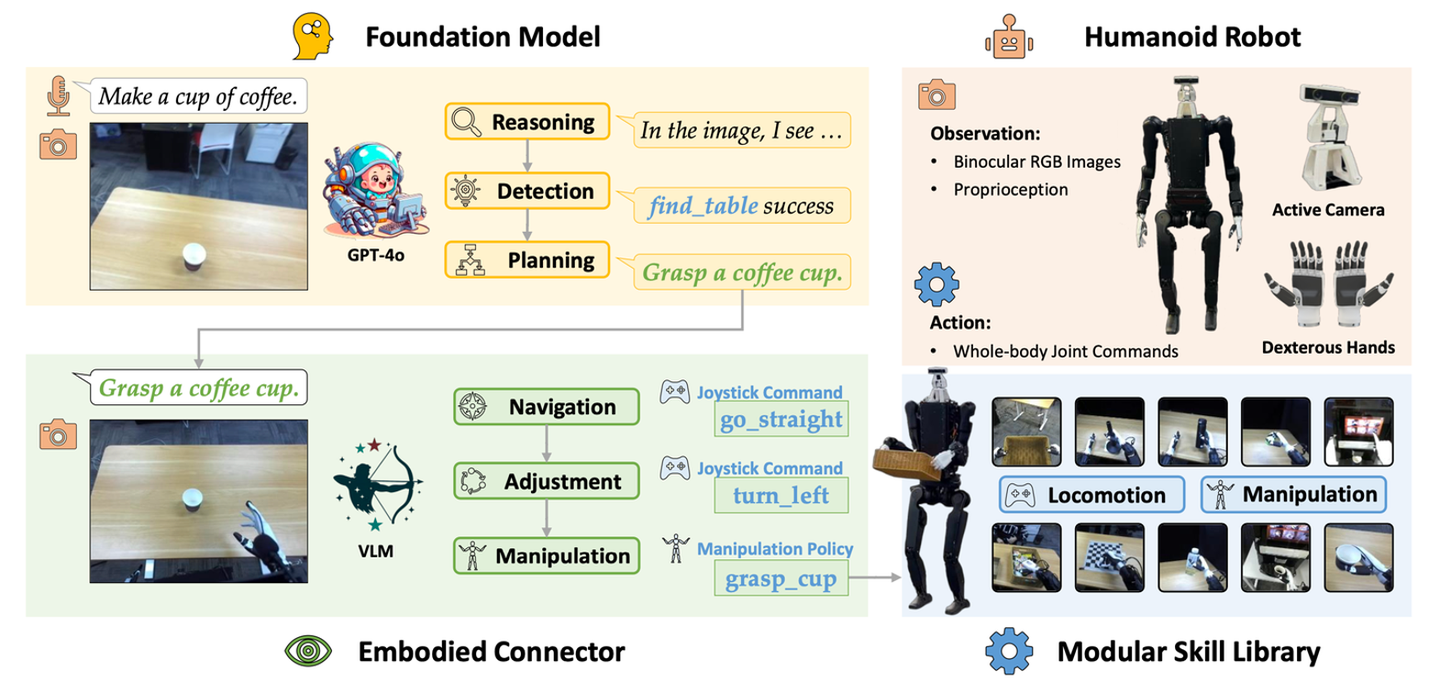
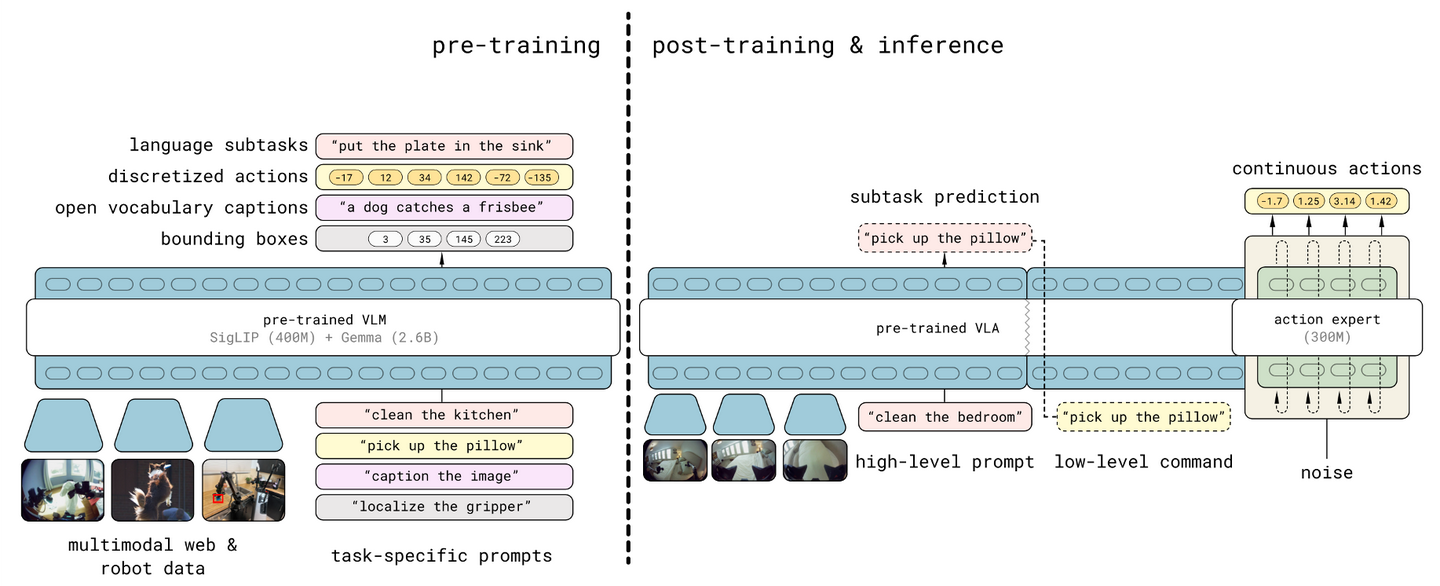
Figure.AI推出一个基于 π0 的演进模型 π0.5【34】,它利用异构任务的协同训练来实现广泛的泛化。π0.5 使用来自多个机器人、高级语义预测、网络数据和其他来源的数据,以实现泛化的现实世界机器人操作。该系统结合协同训练和混合多模态示例,这些示例结合图像观察、语言命令、目标检测、语义子任务预测和低级动作。该模型可以控制移动机械手执行各种家务,即使在训练期间从未见过的家庭中也可以执行。
2.7 人类数据的使用
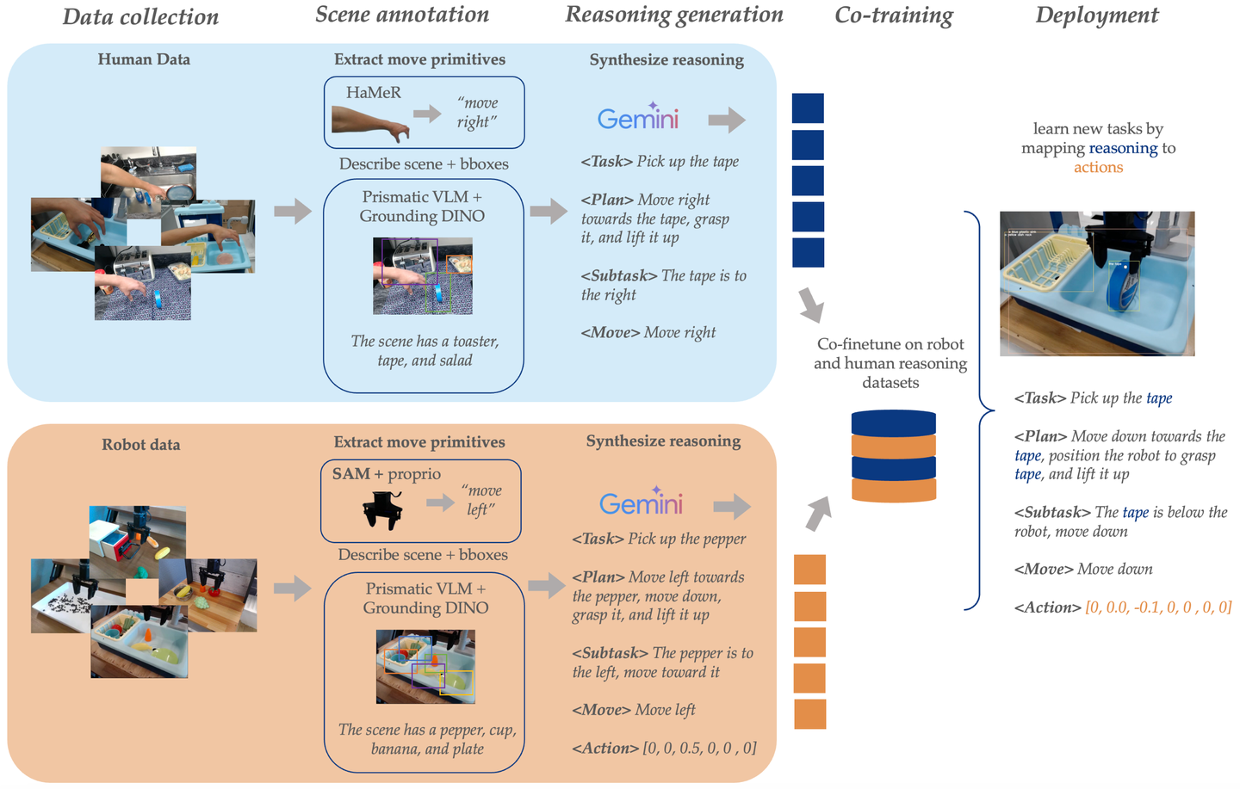
人类视频包含大量指导机器人动作预测的高级推理,这些推理信息可以通过语言捕获。无动作数据的推理 (RAD)【22】利用人类视频中的语言推理来训练可泛化的机器人策略。RAD 从机器人演示数据(带有推理和动作标签)和无动作人类视频数据(仅带有推理标签)中学习。机器人数据教会模型将推理映射到低级动作,而无动作数据则增强推理能力。此外,将发布一个与 Bridge V2 基准兼容的 3,377 人手演示的新数据集。该数据集包括思维链推理注释和手部跟踪数据,以帮助促进未来推理驱动的机器人学习工作。
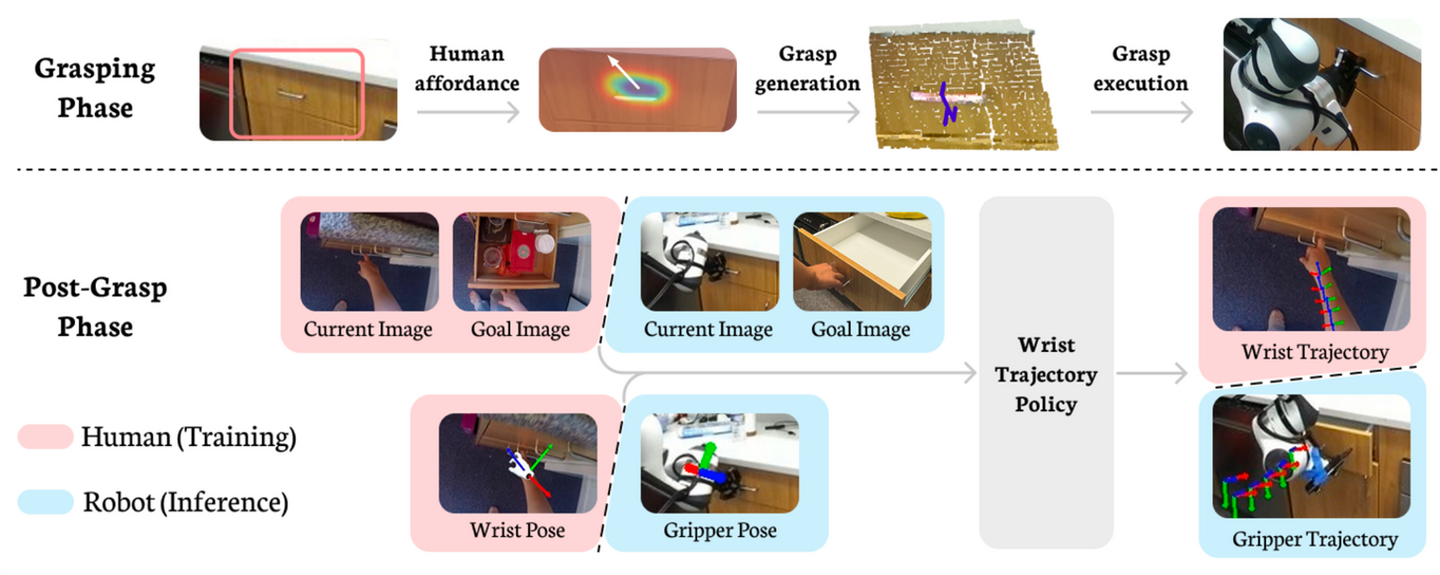
ZeroMimic【31】,它可以为几种常见的操作任务类别(打开、关闭、倾倒、拾取和放置、切割和搅拌)生成可立即部署的图像目标条件技能策略,每种策略都能够作用于不同的目标和不同的未见过任务设置。ZeroMimic 经过设计,利用人类视频的语义和几何视觉理解方面的成果,以及现代抓握 affordance 检测器和模仿策略。操作工作专注于分解的两个阶段:抓取阶段,包括接近和抓取适合目标任务的感兴趣目标;抓取后阶段,包括在稳定地夹住目标的同时进行刚性操作。这包括拾取和放置、滑轨打开和关闭、铰链打开和关闭、倾倒、切割和搅拌等多种技能。ZeroMimic 对这两个阶段特有的组件进行预训练,然后将它们组合在一起。
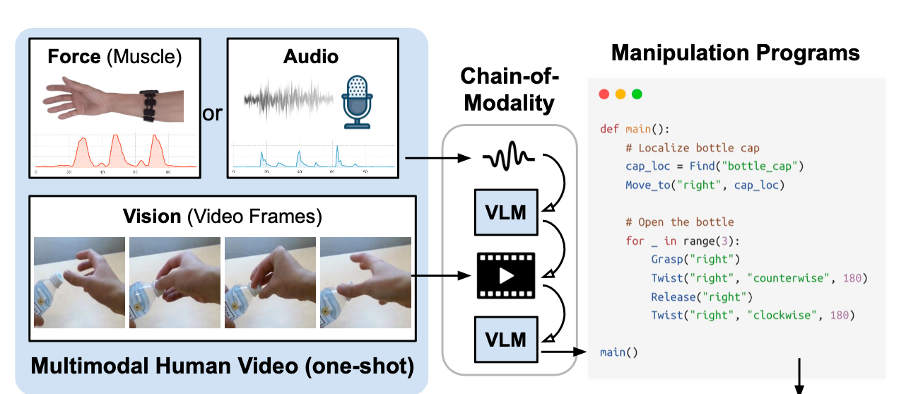
模态链(CoM)【33】是一种提示策略,使视觉-语言模型能够推理多模态人类演示数据——视频与肌肉或音频信号相结合。它促使 VLM 逐个分析每个模态,通过整合来自每个模态的新信息逐步完善答案。通过逐步整合来自各个模态的信息,CoM 可以完善任务规划并生成详细的控制参数,使机器人能够基于单个多模态人类视频提示执行操作任务。
2.8 智体行为
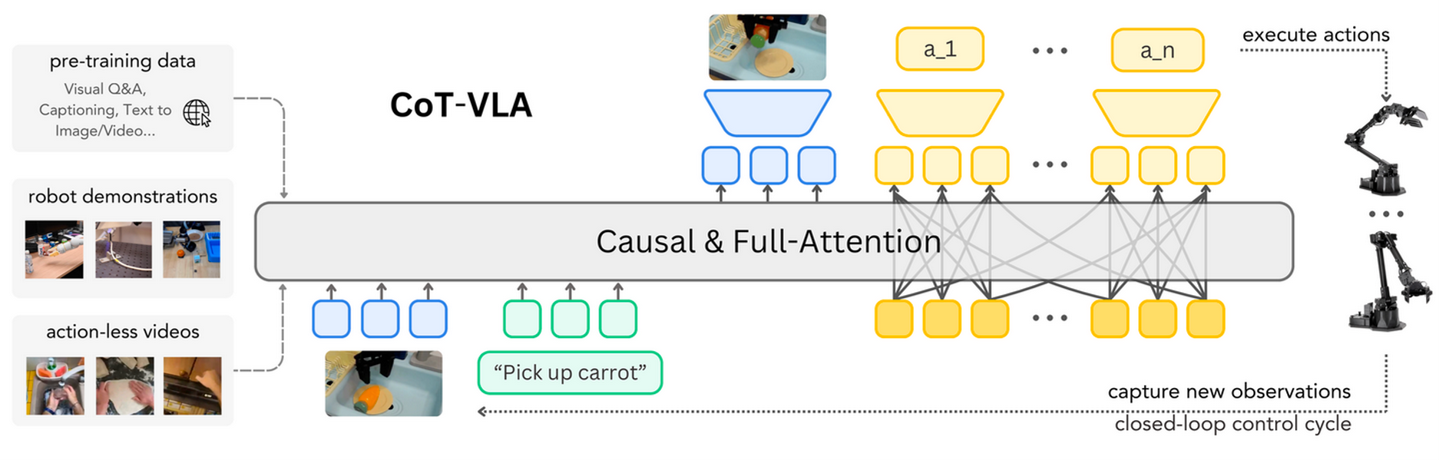
CoT-VLA【30】是一种 7B VLA,可以理解和生成视觉和动作 tokens。其将显式视觉-思维链 (CoT) 推理融入视觉-语言-动作模型 (VLA),通过自回归地预测未来图像帧作为视觉目标,然后生成一个简短的动作序列来实现这些目标。
References
[1] F Ebert et al., “Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets”, arXiv 2109.13396, 2021
[2] T Mu et al., “ManiSkill: Generalizable Manipulation Skill Benchmark with Large-Scale Demonstrations” (SAPIEN), arXiv 2107.14483, 2021
[3] J Gu et al., “ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills”, arXiv2302.04659, 2023
[4] H Walke et al., “BridgeData v2: A Dataset for Robot Learning at Scale”, arXiv 2308.12952, 2023
[5] H Bharadhwaj et al., “RoboAgent: Generalization and Efficiency in Robot Manipulation via Semantic Augmentations and Action Chunking”, arXiv 2309.01918, 2023
[6] J Gu et al., “RT-Trajectory: Robotic Task Generalization via Hindsight Trajectory Sketches”, arXiv 2311.01977, 2023
[7] A Wu et al., “One-Shot Transfer of Long-Horizon Extrinsic Manipulation Through Contact Retargeting” (Action Primitive), arXiv 2404.07468, 2024
[8] S Tao et al., “ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI”, arXiv 2410.00425, 2024
[9] J Zhang et al., “HiRT: Enhancing Robotic Control with Hierarchical Robot Transformers”, arXiv 2410.05273, 2024
[10]S Liu et al., “RDT-1B: A Diffusion Foundation Model for Bimanual Manipulation”, arXiv 2410.07864, 2024
[11]Q Bu et al., “Towards Synergistic, Generalized and Efficient Dual-system For Robotic Manipulation” (RoboDual), arXiv 2410.08001, 2024
[12]I Guzey et al., “Bridging the Human to Robot Dexterity Gap through Object-Oriented Rewards” (HuDOR), arXiv 2410.23289, 2024
[13]K Black et al., “π0: A Vision-Language-Action Flow Model for General Robot Control”, arXiv 2410.24164, 2024
[14]T Ayalev et al., “PROGRESSOR: A Perceptually Guided Reward Estimator with Self-Supervised Online Refinement”, arXiv 2411.17764, 2024
[15]G Lu et al., “AnyBimanual: Transferring Unimanual Policy for General Bimanual Manipulation”, arXiv 2412.06779, 2024
[16]F Yan et al., “RoboMM: All-in-One Multimodal Large Model for Robotic Manipulation”, arXiv 2412.07215, 2024
[17]M Pan et al., “OmniManip: Towards General Robotic Manipulation via Object-Centric Interaction Primitives as Spatial Constraints”, arXiv 2501.03841, 2025
[18]J Ren et al., “Motion Tracks: A Unified Representation for Human-Robot Transfer in Few-Shot Imitation Learning”(MT-π), arXiv 2501.06994, 2025
[19]J Zheng et al., “Universal Actions for Enhanced Embodied Foundation Models” (UniAct), arXiv 2501.10105, 2025
[20]D Li et al., “An Atomic Skill Library Construction Method for Data-Efficient Embodied Manipulation”, arXiv 2501.15068, 2025
[21]Y Li et al., “Integrating LMM Planners and 3D Skill Policies for Generalizable Manipulation” (LLM-3DP), arXiv 2501.18733, 2025
[22]J Clark et al., “Action-Free Reasoning for Policy Generalization” (RAD), arXiv 2502.03729, 2025
[23]Y Ji et al., “RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete”, arXiv 2502.21257, 2025
[24]Figure.AI, “Helix: A Vision-Language-Action Model for Generalist Humanoid Control”, https://www.figure.ai/news/helix, Feb., 2025
[25]AgiBot World, “AgiBot World Colosseo: Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems” (GO-1), arXiv 2503.06669, 2025
[26]H Chen et al., “VidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation”, arXiv 2503.07135, 2025
[27]H Yuan et al., “Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills”, arXiv 2503.12533, 2025
[28]R-Z Qiu et al., “Humanoid Policy ∼ Human Policy” (HAT+PH^2D), arXiv 2503.13441, 2025
[29]L Zheng et al., “DataPlatter: Boosting Robotic Manipulation Generalization with Minimal Costly Data”, arXiv 2503.19516, 2025
[30]Q Zhao et al., “CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models”, arXiv 2503.22020, 2025
[31]J Shi et al., “ZeroMimic: Distilling Robotic Manipulation Skills from Web Videos”, arXiv 2503.23877, 2025
[32]Y Yao et al., “Think Small, Act Big: Primitive Prompt Learning for Lifelong Robot Manipulation” (PPL), arXiv 2504.00420, 2025
[33]C Wang et al., “Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models”, arXiv 2504.13351, 2025
[34]PI, “π0.5: a Vision-Language-Action Model with Open-World Generalization”, arXiv 2504.16054, 2025


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









