










24年3月BAAI、中科院计算所、中科院大学、Dartmouth、北邮和北大的论文“A Survey on Game Playing Agents and Large Models: Methods, Applications, and Challenges”。
大模型(LMs)的快速发展,无论是以语言为中心的还是多模态的,都引起了学术界和工业界的广泛关注。本文就复杂的游戏场景和仍然存在的挑战,提供对LM使用的综述。其试图系统地审查游戏的基于LM智体(LMA)的现有架构,并总结其共性、挑战和任何见解。此外,还提出未来研究途径的展望。
在人工通用智能(AGI)研究的背景下,数字游戏因其提供需要高级推理和认知能力的复杂挑战而被认为是重要的,它是评估智体和系统能力的理想基准[79;6]。与真实世界的实验相比,游戏环境中的数据采集过程在成本效益、可控性、安全性和多样性方面具有优势,同时保留了重大挑战。分析或形式化游戏AI智体及其组件即使在学术界之外也不是最近出现的现象[42;43;44],但研究复杂游戏环境中LMA的性能对于描述其当前限制和评估自主性、可泛化性、了解新架构的设计以及接近潜在AGI的进展至关重要。本文算是LMA与游戏应用程序集成(例如,作为主要参与者,协助人类玩家,控制NPC)的概述。
人脑的功能是一个复杂的信息处理系统,它首先将感官信息转换为感知表征,然后使用这些表征来构建关于世界的知识并做出决策,最后通过行动来实施决策[13]。由于这个抽象序列反映了在游戏智体中观察到的典型迭代周期,其中包括感知、推理和动作,本文遵循了类似的组织。如图说明了综述结构,涵盖了感官信息如何转化为行动的本质,以及LM如何在每个步骤中发挥作用。
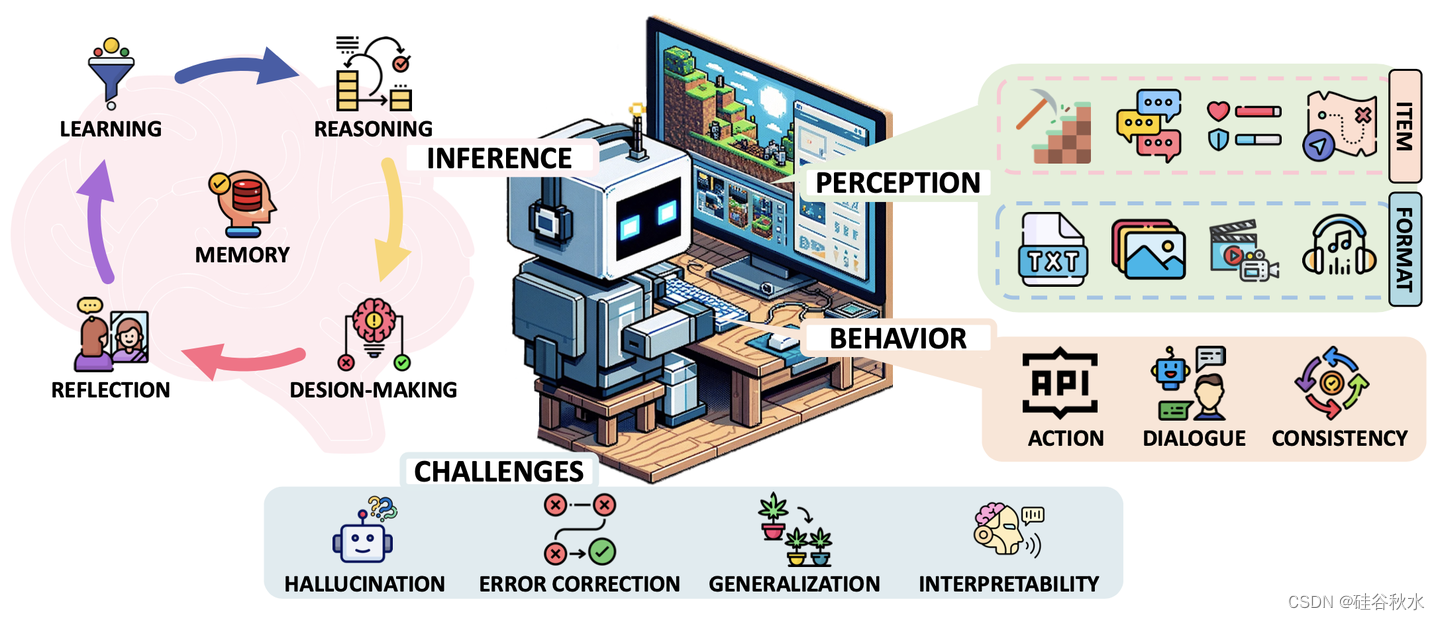
感知涉及将游戏过程中的原始观察信息转换为可操作的见解,支持后续交互。最初的研究侧重于通过文本理解语义信息[64;83],而最近的工作侧重于整合视觉信息(例如,[91])。
推理包括游戏智体的关键能力,包括记忆、学习、推理、反思和决策;通常建立在全面的认知框架之上。通用框架适用于各种应用环境,这意味着并非所有单个组件在每个场景中都是必要的。具体来说,记忆是关于有效存储和检索所学知识,以增强常识和游戏特定见解[94;24]。学习通常涉及通过多智体系统中的经验和协作努力获得技能和战略适应[14]。推理是处理和合成信息以解决问题的过程[48]。复杂博弈中的决策制定需要多轮推理[34]和长期规划[24],结合顺序任务分解和协作决策,以有效地响应动态博弈。而反思意味着自我完善的过程,智体根据反馈评估和调整其策略[64]。这些组件使LM授权的智体能够在现代数字游戏的动态和不断发展的环境中有效地行动。
动作涵盖与游戏环境的交互,即智体执行的操作,作为对游戏状态和环境反馈的响应。使用生成编码,使用迭代提示[64]、特定于角色的工程[14]或代码生成[64;62]等技术来执行。对话交互跨越智体-智体和人-智体的通信,采用协作框架[12],并为动态交互提供对话驱动控制[77]。智体中的行为一致性可以通过结构方法来强调,例如,用于逻辑动作进展的有向无环图(DAG)[78],与用于环境适应的反馈机制[94]相结合,并通过用于连贯动作选择的强化学习(RL)等策略来加强[84]。这些方法使LMA不仅能够处理复杂的任务,还能够调整行为,在动态游戏环境中保持与游戏目标的一致性和对齐。
尽管如此,挑战仍然存在于以上所有阶段(以及其他游戏场景)。其中四个在LMA中特别重要:i)解决批评者智体和结构化推理中的幻觉问题[24;78];ii)通过迭代学习或反馈来纠正错误(例如,[32]);iii)将所学知识推广到未见的任务,可能使用零样本学习或结构化适应性[64;90];以及iv)可解释性,这需要透明的决策过程。虽然这些在各种人工智能系统中都得到了证明,但它们也突出了LM的固有限制对游戏环境这个特定需求的影响。
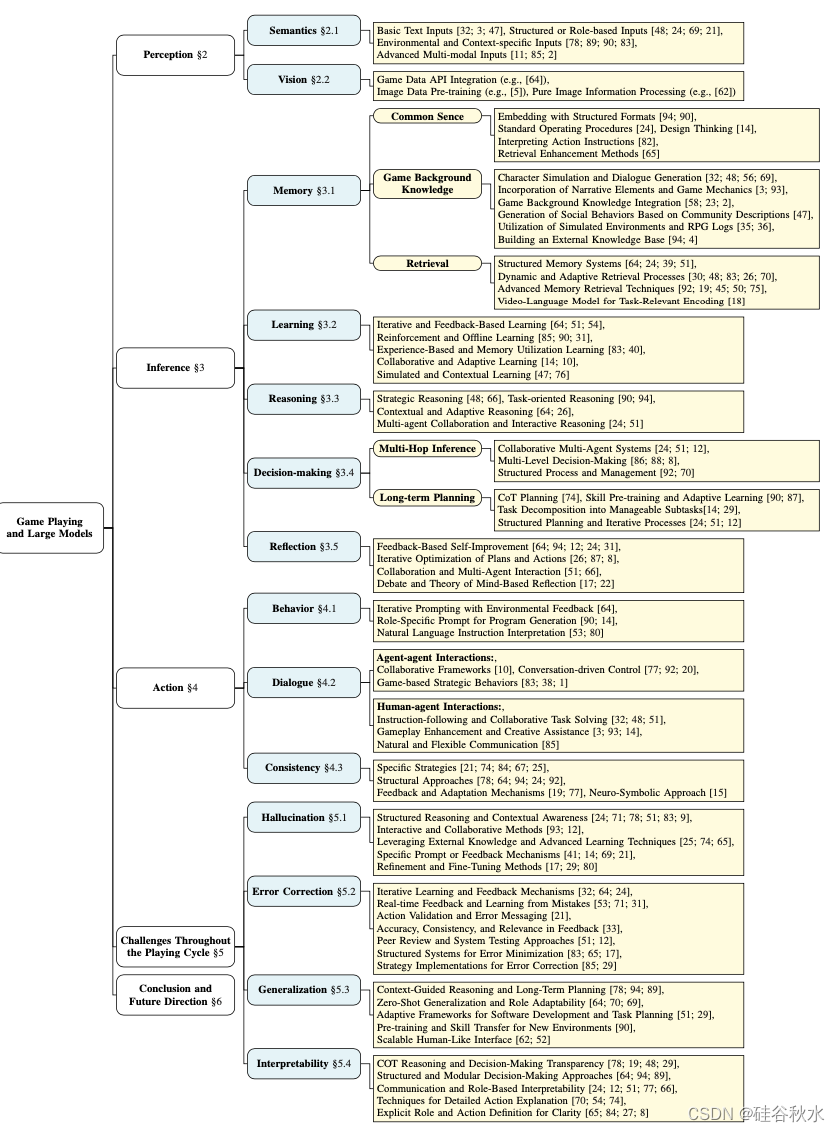
如图是本文对游戏和大模型的研究分类:
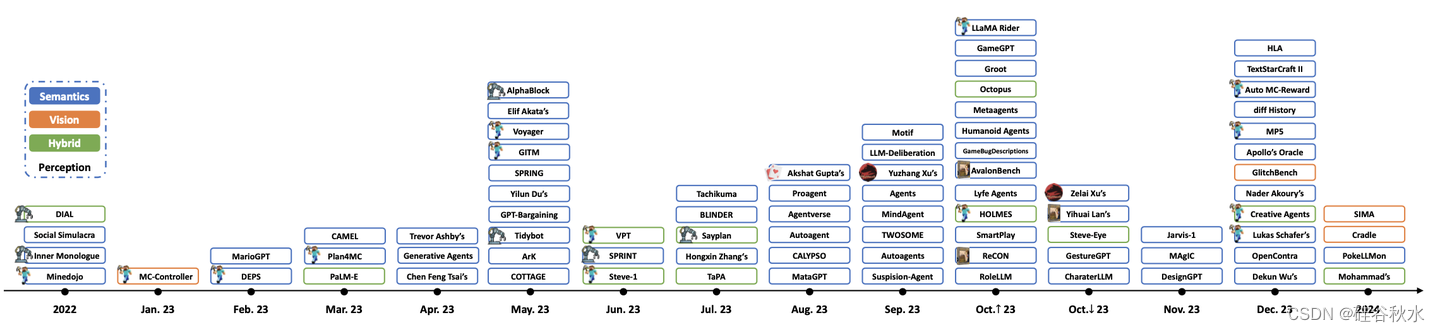
如图是游戏和大模型这个领域的代表性工作一览:
最后是一些挑战问题:
多模态感知:尽管有了进步,但像VOYAGER这样的LMA仍然缺乏视觉感知,因为直到最近才有模型可用,这表明存在显著的改进领域[64]。此外,游戏中的音效对于感知上下文、理解任务和接收反馈至关重要,这是成功完成游戏目标的关键因素。尽管它们很重要,但很少有文献探讨如何利用听觉信息来提高游戏智体的性能。增强多模态能力,包括视觉和听觉感知,可以带来更复杂的任务处理和沉浸式游戏体验。
游戏体验中的真实性:游戏场景中向真实性的演变也值得进一步探索。研究表明,与LLM生成的对话和想法相比,人类书写内容更受青睐,这表明需要在游戏的叙事和状态中更好地为LLM一代奠定基础[48;3;93;68]。如RoleLLM中所探索的,叙事生成和角色模拟的增强可以导致更真实和沉浸式的交互[69]。此外,LMA的行为本身通常是人为的,使其更具流动性/真实性会带来新的可能性。
外部工具的使用:LMA无法掌握利用外部工具来增强游戏性,这是实现AGI的另一个重大差距。当前的LM很难有效地选择和使用工具,导致对实时信息的访问有限。能够动态访问和解释在线游戏指南,并将外部游戏特定的知识推广到新游戏,这将是一个显著的进步,这将需要增强的模型功能来与外部API和文档交互。Toolformer[55]和Gorilla[49]等专注于重新表示API调用原语和微调模型来更好地理解和使用文档,从而解决了其中一些挑战。然而,精通使用外部工具的LM游戏智体的完整实现仍然是开放的问题。
实时游戏:考虑到LMs固有的推理过程和计算需求,掌握实时、高节奏的游戏是一项艰巨的挑战。游戏环境的苛刻性质要求遵守严格的实时性能和推理速度标准。虽然LM提供了相当大的优势,但在需要即时、时间-关键决策的环境中,它们不能替代RL[28;72;7]。展望LMA与人类参与者在实时游戏会话中的集成,这些智体必须实现与所需帧率一致的延迟,以确保实时交互。因此,追求在动态和快速发展的游戏环境中大大提高LMA的效率和反应时间对于即将取得的进展至关重要。
总之,虽然LMA在游戏领域取得了显著进步,但它们的全部潜力尚未实现。未来的工作应侧重于改善多模态感知,在游戏体验中实现更大的真实性,有效地集成外部工具,并在实时游戏环境中表现出色;特别是未开发的前沿领域中(例如,LMA作为自动游戏测试仪)。这些进步不仅将增强LMA的能力,带来更具吸引力和真实感的游戏体验,还将对真实世界的场景产生重大影响。此外,LM还可以应用于各种其他数字游戏相关场景,例如,关卡和故事生成,或游戏平衡和机制调整。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









