










24年3月中科院自动化所和创业公司极佳的论文“DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation”。
世界模型在自动驾驶方面表现出了优势,尤其是在多视图驾驶视频的生成方面。然而,在生成自定义驾驶视频方面仍然存在重大挑战。本文提出DriveDreamer-2,它建立在DriveDreamer的框架上,并结合了一个大语言模型(LLM)来生成用户定义的驾驶视频。具体来说,LLM接口最初被合并以将用户的查询转换为智体轨迹。随后,根据轨迹生成符合交通规则的高清地图。最终,提出统一多视图模型,增强生成的驾驶视频在时间和空间的连贯性。
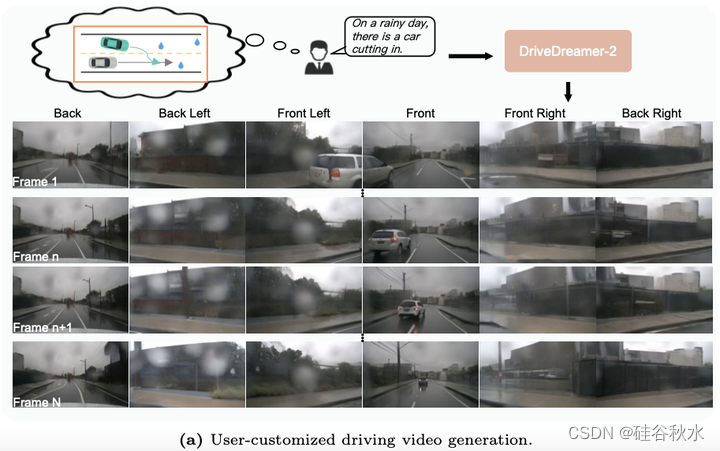
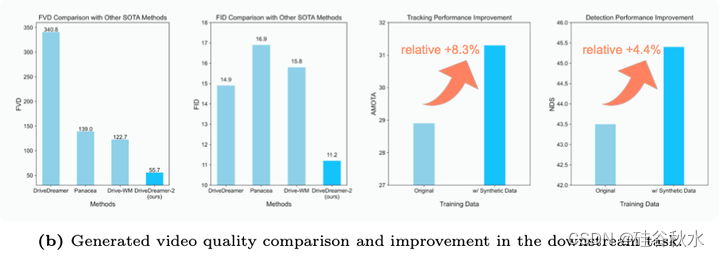
如图DriveDreamer-2展示了生成多视图驾驶视频的功能。DriveDreamer-2根据用户描述制作驾驶视频,这提高了合成数据的多样性。此外,DriveDreamer-2的生成质量超过了其他方法,并有效地增强了下游任务。
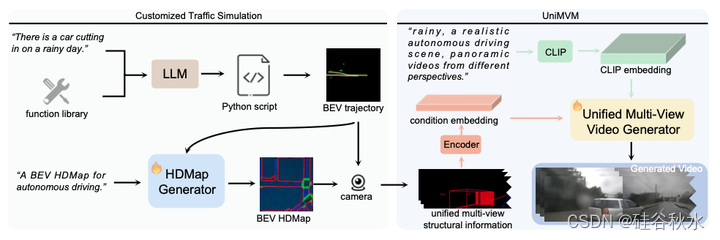
如图展示了DriveDreamer-2的总体框架。首先提出一种定制的交通仿真来生成前台智体轨迹和后台高清地图。具体而言,DriveDreamer-2利用微调的LLM将用户提示转换为智体轨迹,然后引入高清地图生成器,以生成的轨迹作为条件来模拟道路结构。DriveDreamer-2利用定制的交通模拟流水线,能够为后续视频生成提供各种结构化条件。在DriveDreamer架构的基础上,提出了UniMVM框架,统一视图内和视图间的空间一致性,从而增强生成的驾驶视频在整体时间和空间的一致性。
以前的交通模拟方法需要复杂的参数规范,包括智体的速度、位置、加速度和任务目标等细节。为了简化这一复杂的过程,使用结构化的轨迹生成函数库对LLM进行微调,从而将用户友好的语言输入有效地转换为全面的交通模拟场景。如图所示,构建的函数库包括18个函数,包括智体函数(转向、等速、加速度和制动)、行人函数(行走方向和速度)以及其他实用函数,如保存轨迹。基于这些函数,文本-到-Python-脚本对,是手动策划的,用于微调LLM(GPT-3.5)。脚本包括一系列基本场景,如变道、超车、跟随其他车辆和执行掉头。此外,还涵盖了更不常见的场景,如行人突然横穿马路和车辆驶入车道。以用户输入的车辆切入为例,相应的脚本包括以下步骤:首先生成切入轨迹agent.cut_in(),然后生成相应的自车轨迹agent.forward();最后利用实用程序的保存功能,以数组形式直接输出自车和其他智体的轨迹。在推理阶段,将提示输入扩展到预定义的模板,微调后的LLM可以直接输出轨迹阵列。

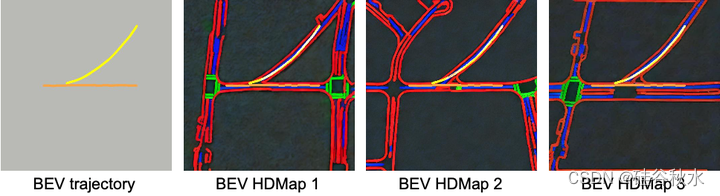
如图所示,HDMap生成器可以基于相同的轨迹条件生成不同的HDMap。值得注意的是,生成的HDMaps不仅遵守交通约束(位于车道分隔带两侧的车道边界和十字路口的人行横道),而且与轨迹无缝集成。橙色和黄色分别表示自车和其他车辆的运动轨迹。红色表示道路边界,蓝色表示车道分隔线,绿色表示人行横道。
如图所示,将UniMVM的范式与DriveDreamer和Drive-WM的范式进行了比较。UniMVM将多个视图统一为一个完整的补丁,用于视频生成,而不引入交叉视图参数。此外,可以通过调整掩码来完成各种驾驶视频生成任务。特别地,当掩码被设置为屏蔽未来的T−1帧时,UniMVM可以基于第一帧的输入来启用未来视频预测。将掩码配置为屏蔽{FL、FR、BR、B、BL}视图,使UniMVM能够利用前视图视频输入来实现多视图视频输出。此外,当掩码被设置为屏蔽所有视频帧时,UniMVM可以生成多视图视频,并且定量和定性实验都验证UniMVM能够以增强的效率和多样性生成时间和空间相干的视频。
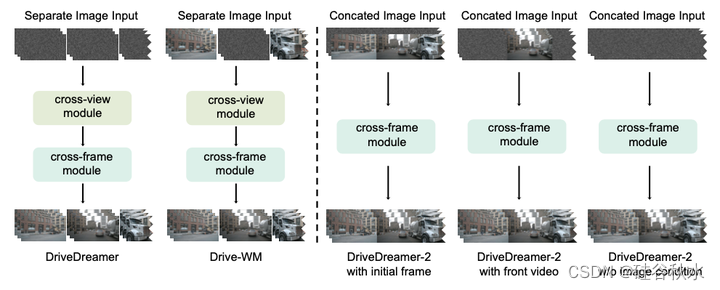
与DriveDreamer不同,DriveDreamer-2中的3D边框条件不再依赖于位置嵌入和类别嵌入。相反,这些框被直接投影到图像平面上,起到控制条件的作用。这种方法消除了引入额外的控制参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









