









24年1月中山大学和腾讯AI实验室的论文“Knowledge Fusion of Large Language Models”。
虽然从头开始训练大语言模型 (LLM) 可以生成具有独特功能和优势的模型,但成本很高,并且可能会导致功能冗余。 或者,一种经济有效且令人信服的方法是将现有的预训练LLMs合并到更有效的模型中。 然而,由于这些LLMs的架构不同,直接混合权重是不切实际的。 本文介绍LLMs知识融合的概念,旨在结合现有LLMs的能力并将其转移到单个LLM中。 通过利用源LLM的生成分布,将它们的集体知识和独特优势具体化,从而有可能将目标(target)模型的能力提升,超越任何单个源LLM的能力。 用具有不同架构的三种流行LLMs(Llama-2、MPT 和 OpenLLaMA)在各种基准和任务中验证了该方法。 LLMs的融合可以提高目标模型在推理、常识和代码生成等一系列能力上的性能。 代码、模型权重和数据如下公开 https://github.com/fanqiwan/FuseLLM
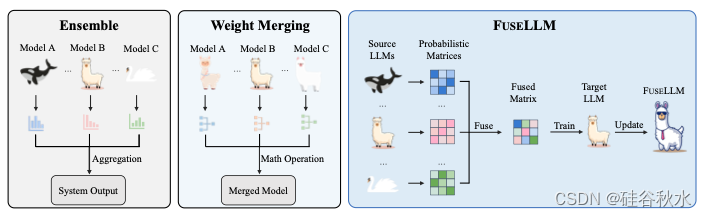
如图是传统模型融合技术(集成方法和权重合并方法)和LLM知识融合方法(FUSELLM)比较。 不同的动物图标代表不同的LLM,不同的物种表示LLM拥有不同的架构。 FUSELLM 将多个LLM的知识外化,并将其能力转移到目标LLM。
令 t 表示从语料库 C 采样的长度为 N 的文本序列,t<i =(t1, t2, …, ti−1) 表示第 i 个token之前的序列。用于训练由 θ 参数化的语言模型的因果语言建模 (CLM) 目标被定义为最小化负对数似然:
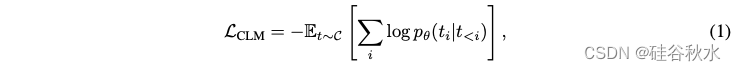
上述目标将序列似然分解为token级别的交叉熵损失,将每个token的预测分布与其one-hot表示进行比较。 为了提供更普遍的角度观察,将这种token级视图重新构建为顺序分布的格式。 具体来说,对于文本序列 t,聚合 token 级别的预测并创建一个概率分布矩阵 Pθt,其中第 i 行表示模型预测的第 i 个 token 在大小V词汇上的分布。 然后,CLM 目标可以解释为减少 Pθt 与one-hot标签矩阵 Ot之间的差异,其中每一行都是相应黄金token的one-hot表示。 形式上,CLM 目标转换为以下表示形式:
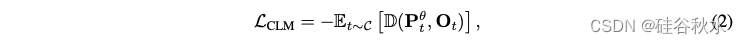
从语言模型的角度来看,概率分布矩阵可以反映其在理解文本时的某些固有知识。 因此,来自不同LLM的同一文本的不同概率分布矩阵,可用于表示这些模型中嵌入的不同知识。 认识到这一点,提出的 FUSELLM 方法通过概率建模来解决 LLM 融合问题,旨在通过合并源 LLM 的概率分布来创建统一的 LLM。 为了实现这一目标,当从一组要融合的 LLM 开始时,FUSELLM 在反映预训练数据集的原始文本语料库上对目标 LLM 进行轻量级持续训练。 FUSELLM 不是仅仅依赖于因果语言建模( CLM )目标,而是非常重视最小化一个目标 LLM 的概率分布与其源 LLM 的概率分布之间的差异。
对于语料库 C 中的每个文本,应用提供的 K 个源 LLM 并获得一组概率分布矩阵,表示为 {Pθj },j=1,K,其中 θj 表示 LLM 的参数。 利用这些矩阵,将各个模型的知识外化到统一的空间中,本质上是在文本上创建统一的概率表示。 源 LLM 之间词汇差异可能导致矩阵 {Pθj} 无法对齐。 为了解决这个问题,采用了token对齐策略促进跨模型的更连贯概率解释。
对齐概率矩阵后,继续将它们融合成一个紧凑的表示。 为此目的可以应用各种融合策略。用Pt来表示融合表示矩阵如下:
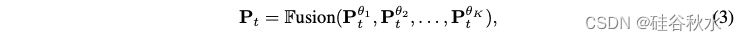
为了将源 LLM 的功能转移到目标 LLM,强制目标 LLM 的预测和融合表示矩阵 Pt 之间的对齐。 用 Qt 来表示文本 t 的目标 LLM 输出分布矩阵,然后定义融合目标如下:
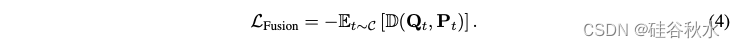
持续训练的总体目标由因果语言建模目标 LCLM 和融合目标 LFusion 的加权组合组成,如下所示:
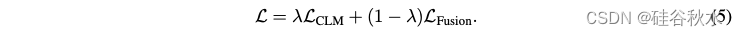
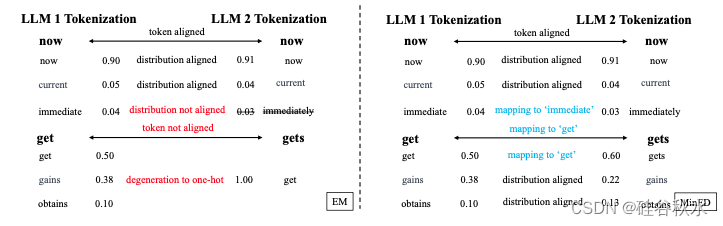
确保多个LLM之间的token对齐对于有效的知识融合至关重要,因为它保证了概率分布矩阵的正确映射。 Fu(2023) 采用动态编程来递归地最小化编辑一个token序列以匹配另一个token序列的总成本。 如果两个token之间存在一对一映射,则相应的分布是完美映射的。 否则,映射的分布会退化为one-hot向量。 由于不同tokenizer为同一序列生成的token通常表现出有限的差异,因此为提高token对齐的成功率,替换Fu(2023)的精确匹配(EM)约束来为最小编辑距离(MinED)策略,该策略根据 MinED 映射来自不同tokenizer的tokens。 这种token对齐的放松有助于在分布矩阵中保留大量信息,同时引入较小的错误。
为了结合源LLM的集体知识,同时保留其独特的优势,必须评估不同LLM的质量并为其各自的分布矩阵分配不同的重要性级别。 为此,在处理文本 t 时,用分布矩阵和黄金标签之间的交叉熵损失作为 LLM 预测质量的指标(Marion,2023)。 源LLM的交叉熵分数越低,意味着对文本的理解越准确,其预测应该具有更大的意义。 基于这个标准,引入两个融合函数:(1)MinCE:该函数输出具有最小交叉熵得分的分布矩阵; (2) AvgCE:该函数根据交叉熵分数生成分布矩阵的加权平均值。
FUSELLM方法的完整流程如下算法所示。

如下是一个不同token对齐方法的例子:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









