










24年3月UCSD论文“Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving”。
视觉-语言模型(VLM)和多模态语言模型(MMLMs)在自动驾驶研究中变得突出,因为这些模型可以使用交通场景图像和其他数据模态为端到端自动驾驶安全任务提供可解释的文本推理和响应。然而,当前这些系统的方法使用昂贵的大语言模型(LLM)主干和图像编码器,使得这种系统不适合存在严格内存约束和需要快速推理时间的实时自动驾驶系统。为了解决上述问题,本文开发EM-VLM4AD,一种高效、轻量的多帧视觉-语言模型,用于执行自动驾驶的视觉问答。与以前的方法相比,EM-VLM4AD需要的内存和浮点操作至少要少10倍,同时还实现了比DriveLM数据集上现有基线更高的BLEU-4、METEOR、CIDEr和ROGUE分数。EM-VLM4AD还展示了从提示相关的交通视图中提取相关信息的能力,并可以回答各种自动驾驶子任务的问题。
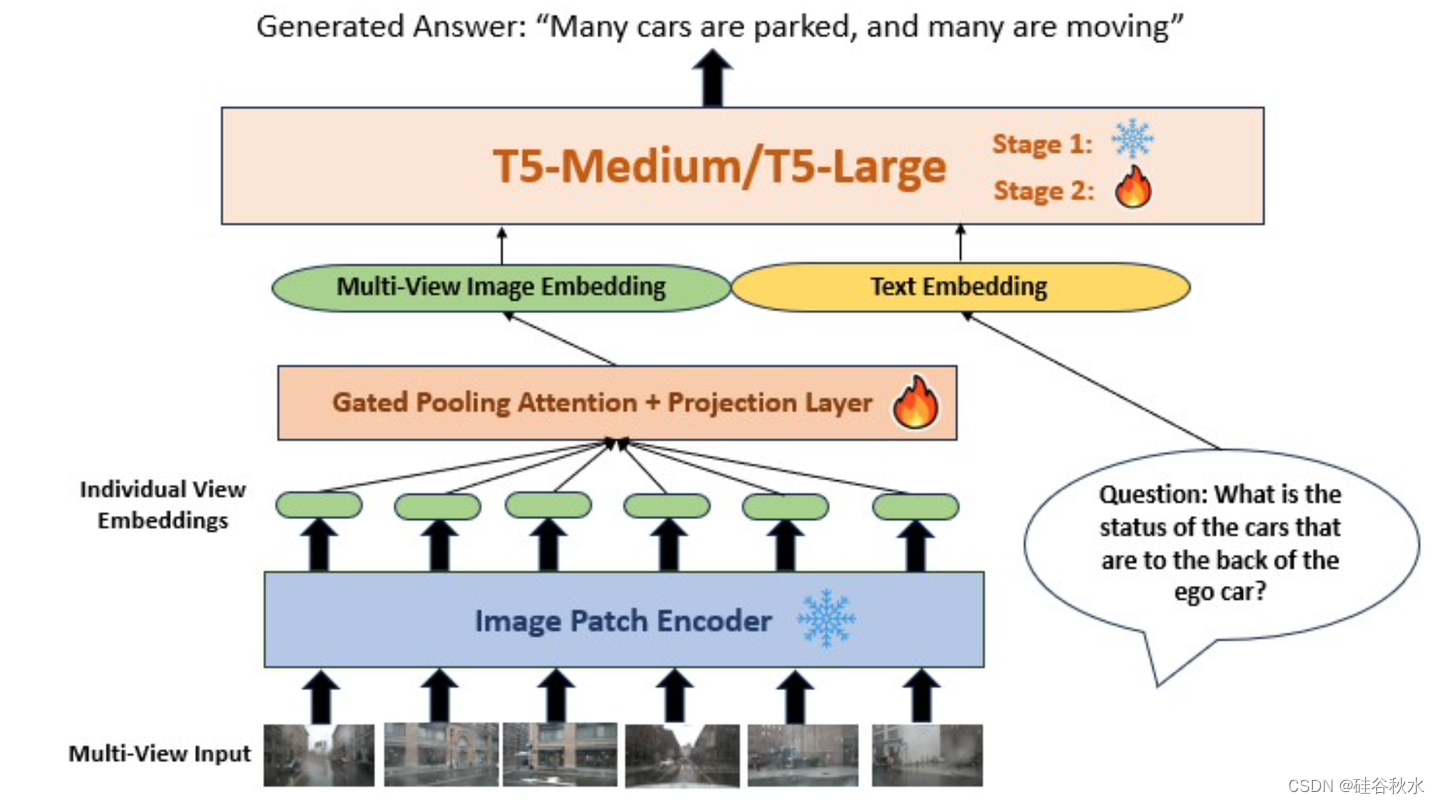
为了解决自动驾驶的多视图(前、左前、右前、后、左后、右后)QA任务,需要将单个图像嵌入聚合到一个嵌入中。然后,可以将该统一的嵌入与文本嵌入连接起来,作为LM的输入。在典型的VLM中,图像嵌入过程使用CLIP或目标检测网络等模型,导致提取过程缓慢。为了解决这个问题,采用ViT[10]提出的补丁投影嵌入(patch projection embedding)方案。给定RGB图像I,通过线性投影和位置嵌入将图像展平并切片为补丁。这创建了潜图像表示Vi,其中SI是图像嵌入的序列长度,HI是图像嵌入中的隐维度。用在ImageNet[8]上预处理的ViT-B/32预处理权重来生成这些图像嵌入。
采用门控池化注意【37】的非线性,这有助于在图像中池化视觉信息。使用该组合图像嵌入V,接着投影该嵌入匹配文本嵌入的嵌入维度,以便将文本和图像嵌入连接在一起,其中ST是文本嵌入的序列长度。然后将该级联的多模态嵌入输入到LM中,生成答案文本。
为了减轻视觉-语言模型的计算和推理成本,旨在使用参数少于10亿更轻量级LM。为了实现这一点,用T5 LM模型的两个不同预训练版本:T5 Base,包含大约2.23亿个参数,以及T5 Large的8-bit量化版本(≈750M参数)。用这些预训练LM执行微调,以使LM适应级联的多视图图像和文本嵌入。在实验中,微调T5 Base的整个模型效果最好,但对于量化的T5 Large,用LoRA-微调-觉察的量化[22],这有助于通过初始化LoRA权重来最小化量化误差。
如图所示:模型响应多视图图像输入和问题提示。T5 LM在训练的第1阶段被冻结,因此图像嵌入网络学习与T5嵌入进行对齐。图像补丁编码器在训练的所有阶段都被冻结,门控池化注意和投影层在这两个阶段都被训练。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









