










24年3月日本Sakana AI公司的论文“Evolutionary Optimization of Model Merging Recipes”。
本文提出进化算法的一种应用,自动创建强大的基础模型。 虽然模型合并因其成本效益而成为LLMs开发的一种有前景的方法,但它目前依赖于人类直觉和域知识,限制了其潜力。 在这里,提出了一种进化方法,通过自动发现不同开源模型的有效组合,利用它们的集体智慧,而不需要大量的额外训练数据或计算来克服这一限制。 该方法在参数空间和数据流空间中运行,允许优化不仅仅是单个模型的权重。 这种方法甚至促进了跨域合并,生成一个具有数学推理能力的日本LLMs模型。 令人惊讶的是,日本数学LLMs在各种已建立的日本LLMs基准上取得了最先进的表现,甚至超越了参数明显更多的模型,尽管没有针对此类任务进行明确的训练。 此外,通过该方法生成的具有文化意识的日本 VLM 证明了其在描述日本文化特定内容方面的有效性,优于以前的日本 VLM。
模型合并 [15, 28] 是大语言模型 (LLM) 社区的最新发展,呈现出一种新的范式转变。 通过战略性地将多个LLMs整合到一个架构中,因其关键优势而吸引了研究人员的注意:它不需要额外的训练,使其成为开发新模型一种极具成本效益的方法。 这种特性激发了人们对模型合并的兴趣,并出现实验的激增。 Open LLM 排行榜 [20] 现在以合并模型为主,展示了其民主化基础模型开发的潜力。
但是模型合并被许多人认为是一种黑术或炼金术,依靠模型制作者对模型选择和合并方法的直觉和本能来创建和完善对特定任务表现良好的新模型。 此外,模型制作者通常需要具备一些针对各种不同基准任务的域知识。 鉴于社区中开放模型和基准的多样性,人类的直觉只能走这么远,那么发现新模型组合的更系统方法会使得模型合并走得更远。
进化算法能够发现更有效的模型合并解决方案,从而为自动创建更强大模型提供一条途径。 作为朝着这个方向迈出的一步,这项工作展示进化可以用来发现新且不直观的方法来合并各种模型,产生具有新组合能力的模型。 在这项工作中,提出了一种利用进化算法来促进基础模型合并的方法。 其方法的特点是能够导航参数空间(权重)和数据流空间(推理路径),并提出一个集成两个维度的框架。
模型合并技术与传统的迁移学习形成鲜明对比,传统的迁移学习是针对新任务在预训练模型进一步微调。 虽然迁移学习具有提高性能和更快收敛等优点,但生成的模型通常仅限于单个任务。 另一方面,模型合并致力于通过结合多个预训练模型的知识来创建通用且全面的模型,有可能产生能够同时处理各种任务的模型。最受欢迎的Stable Diffusion模型既不是原始的基础模型,也不是微调版,而是爱好者创建的合并模型。
基于权重插值的方法的一个关键问题是它们忽略了参数干扰,导致性能下降。 最近的一项工作[49]确定了两个关键的干扰源:模型间的冗余参数值和冲突的参数符号,并提出了一种解决这些问题的方法,以实现改进的合并性能。 所提出的 TIES-Merging 方法通过合并三个步骤来解决现有合并方法中的信息丢失问题:重置最小参数更改、解决符号冲突以及仅合并对齐的参数。
最近的另一项工作 [50] 提出 DARE 方法更进一步,将微调模型和原始基础模型之间的微小差异归零,同时放大差异。 在实践中,DARE [50]经常与任务算术[21]或TIES-Merging [49]一起使用。
Mergekit 引入一种名为 Franken merging 的附加方法,它不是基于权重合并,而是供用户尝试堆叠多个模型的不同层以顺序创建新模型。 这种方法的优点是,不会将用户绑定到具有固定合并架构的特定模型系列(例如基于 Mistral 模型),但有可能通过合并完全不同的模型来创建新架构。 值得注意的是,Franken merging 技术仍然是社区的一个挑战,并且需要更多的试验和错误来发现该技术的新方法。 迄今为止,几乎每个人都使用类似的 Frankenmerging 合并方法,并且几乎没有进行过尝试和错误来改进它。
该领域的探索仍然严重不足,我们相信这就是进化可以提供帮助的地方。
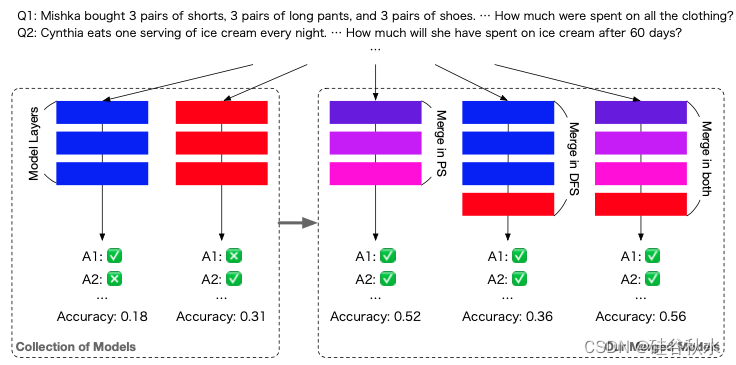
那么创建一个统一的框架,从选定的基础模型中自动生成合并模型,确保该合并模型的性能超过其中任何个体的性能。 方法的核心是进化算法的应用,用它来完善模型合并中涉及的复杂性。 为了系统地应对这一挑战,首先将合并过程剖析成两个不同的、正交的配置空间,分析它们各自的影响。 基于此分析,随后引入一个无缝集成这些空间的聚合框架。 如下是该方法的示意图:(1) 进化参数空间(PS)中每一层混合参数的权重; (2) 数据流空间(DFS)中不断进化的层排列; (3) 综合策略,结合 PS 和 DFS 两种合并方法。 注意PS的合并并不是简单的图层参数的复制和拼接,还混合了权重。 这种合并类似于颜色混合(例如,红色和蓝色变成紫色)。 请注意,已将问题翻译成英文供读者阅读; 这些模型对日语文本进行操作。
当该方法扩展到多模态模型,发展成为一种具有特定文化内容意识的日本 VLM。 最近,通过应用预训练LLMs强大的指令跟踪能力,VLM 取得了显着的进步。 VLM的架构通常由三个部分组成:(1)视觉编码器,用于提取图像特征; (2) 生成文本的LLMs(用于描述图像); (3) 将图像特征映射到 LLM 嵌入空间的投影网络 [5,9,29,30,32]。 至关重要的是,LLM 组件使用强大的预训练 LLM 进行初始化,以实现其文本生成功能。 在训练期间,投影网络和可选的LLMs在各种视觉语言数据集上进行训练,而视觉编码器是固定的。
VLM内的LLM组件可以被视为一个独立的LLM,具有理解视觉软提示的额外能力。 从这个角度来看,修复视觉编码器和投影网络并仅关注 LLM 组件,可以直接生成具有扩展功能的新 LLM。
在这个实验中,参数空间中将日语 LLM 和 VLM 中的 LLM 组件合并。 选择 shisa-gamma-7b-v1 [3] 作为日本 LLM,选择 LLaVA-1.6-Mistral-7B [31] 作为 VLM。 两个模型都是 Mistral-7B-v0.1 [22] 基本模型的微调版。
目前,将进化优化的模型合并应用于图像扩散模型方面已经取得了有希望的结果,通过以进化发现的新方法,合并现有的构建块,能够创建高性能的跨域图像生成模型。
该方法目前要求用户选择一组源模型作为进化搜索的成分。 也可以利用进化方法从大量现有模型中搜索候选的源模型。 除了模型选择之外,还在探索利用进化来产生大量不同的基础模型,每个模型都有自己的位置和行为。 这有可能使由一群模型组成的集体智慧出现,这些模型能够通过交互不断产生新的互补世界内部模型来自我改进。
相关的工作是一个名为 Automerge [27] 的实验,它与这项工作几乎同时发布。 这个有趣的实验通过从 Open LLM Leaderboard [20] 的前 20 个模型中选择两个随机模型,并随机应用 SLERP [47] 或 DARE-TIES [49, 50] 来创建新模型。 随着时间的推移,其中一些模型将在定义该排行榜的基准任务上表现出色,甚至更好,成为排行榜的一部分。 预测这种方法将导致合并模型的组合过度适合排行榜上定义的基准任务。 这个项目背后的想法不是创建更好的模型,而是更多地获取更多指标来帮助得出更有原则的模型合并方法。
该工作采用正交方法来优化原始排行榜 [20] 指定域之外的任务,而不是受其限制。 正如所展示的,令人惊讶的是,放弃对特定基准的优化有时会导致对原本不打算优化的其他基准任务更大地泛化,而这种新泛化可能是解锁下一个AI重大进步的关键。
从具有各种功能的大量现有的、多样化的模型中演化出具有新功能的新模型能力具有重要意义。 随着训练基础模型的成本和资源需求不断上升,通过利用丰富的开源生态系统中丰富多样的基础模型,大型机构或政府可能会考虑采用更便宜的进化方法来快速开发概念验证原型模型。 投入大量资金或利用国家资源从头开始开发完全定制的模型(如果有必要的话)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









