










24年1月复旦大学论文“ToolEyes: Fine-Grained Evaluation for Tool Learning Capabilities of Large Language Models in Real-world Scenarios”。
现有的工具学习评估主要侧重于验证语言大模型 (LLM) 所选工具与预期结果的一致性。 然而,这些方法依赖于一组有限的场景,在这些场景中答案可以预先确定,偏离真正的需求。 此外,仅仅强调结果忽视了LLM有效利用工具所必需的复杂能力。 为了解决这个问题,提出了 ToolEyes,一个专为评估LLM在真实场景中的工具学习能力而定制的细粒度系统。 该系统仔细检查了七个现实场景,分析了LLM在工具学习中至关重要的五个维度:格式对齐、意图理解、行为规划、工具选择和答复组织。 此外,ToolEyes 还包含一个拥有大约 600 个工具的工具库,充当LLM和现实世界之间的中介。 涉及三个类别的十名LLMs的评估,揭示了对特定场景的偏好和工具学习中有限的认知能力。 有趣的是,扩大模型规模甚至加剧了工具学习的障碍。 这些发现提供了旨在推进工具学习领域的指导性见解。 代码和数据可如下获取:
https://github.com/Junjie-Ye/ToolEyes
如图所示,LLM在收到用户请求后,会仔细审查用户的需求,提示提供足够的信息,选择合适的工具,并以指定的格式输入所需的参数。 随后,该工具与环境交互,向LLM提供反馈。 然后,LLM根据最初的请求进行逻辑推理,然后迭代,直到得到结论性的答案。
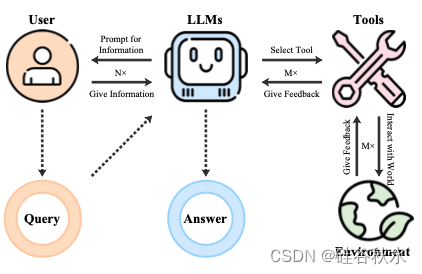
如图所示,ToolEyes根据实际应用需求,制定了七个不同的现实场景来全面审视整个工具学习过程。 每个场景都包含一系列相关工具,LLM可以利用这些工具与现实世界互动并满足用户的实际需求。 通过从五个维度评估LLM的能力,该系统可以熟练地监督整个工具学习过程。
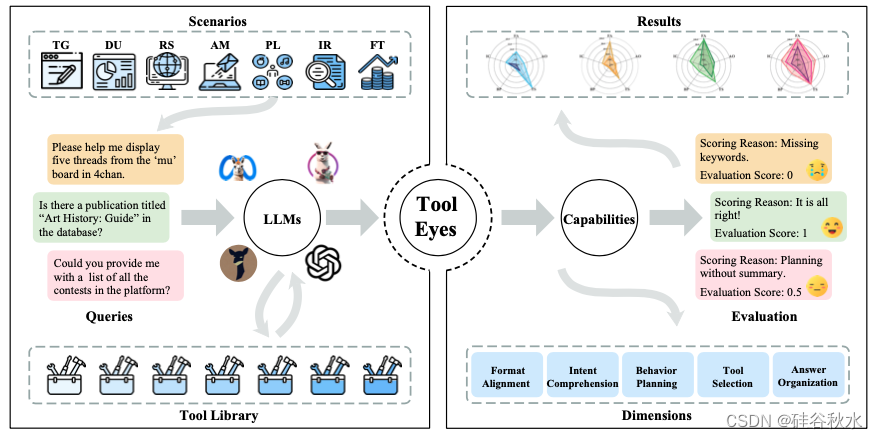
如下7个现实场景:
- 文本生成 (TG)。TG 是一种极具代表性的通用场景,它要求LLM生成满足用户需求的文本,同时遵守查询的类型、格式、字数和其他规范。文本生成的典型用户请求包括建议、笑话、翻译等等。
- 数据理解 (DU)。DU封装了一个专门的需求场景,其中LLM的任务是理解用户输入的数据,并根据用户需求定制的特定维度对其进行分析,包括情感分析、关系预测、有效性验证等。
- 实时搜索(RS)。RS在现实世界中得到广泛应用,要求LLM使用各种搜索工具来收集与用户需求相关的信息。随后,LLM负责编译收集到的数据并将其以自然语言文本的形式呈现给用户。
- 应用程序操作(AM)。AM是一个特殊的场景,要求LLM根据用户请求选择相关工具。它通过执行代码、操作文件和管理通信来直接影响外部环境的状态,从而超越了语言模型功能的典型限制。
- 个人生活 (PL) 。PL 涵盖与个人生活需求相关的场景,促使LLM利用给定的工具收集有关娱乐、食物、工作和其他相关主题的信息。
随后,LLM综合所获得的信息,为用户提供有效的建议。 - 信息检索(IR)。IR 是检索任务的一个子集,要求LLM从广泛的现有数据库中检索相关信息。 这与 RS 不同,RS 优先考虑即时信息。
由于每个数据库支持的检索方法各不相同,LLM被迫根据特定要求访问不同的数据库。 - 金融交易(FT)。FT包括需要专门的金融和经济知识的场景,促使LLM使用工具来获取相关的金融信息。随后,LLM分析这些信息以解决用户的问题或提供相关建议,其中可能涉及有关股票走势或汇率波动的讨论。
为了建立LLM与环境互动的界面,回顾工具设计的现有工作(Schick et al., 2023; Zhuang et al., 2023; Qing et al., 2023b),收集相关各个类别的真实工具。 系统地纠正了工具名称,并遵循 GPT-4 格式来制作工具文档,为每个收集的工具创建文档。 按照这种组织方式,每个场景都配备了一组相关的工具,其中不同的工具可以提供相似的功能。 整合后,建立了一个综合的工具库,包含41个类别、95个子类别、568个工具,能够满足多样化的社会需求。 LLM可以使用指定的格式调用这些工具并从中检索实际信息。
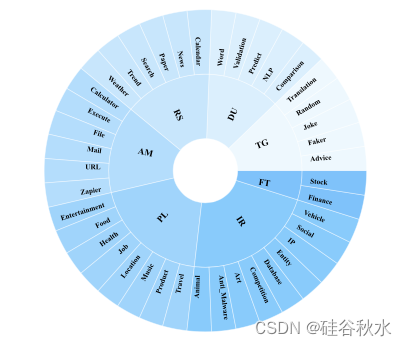
根据构建的场景,与每个场景相关的不同专业团队合作,征求他们的意见,通过审查工具文档来确定实际需求。为了确保全面覆盖需求,一次专注于一个工具子类别,旨在涵盖该子类别中尽可能多工具的需求。 随后,经过彻底的人工验证,总共收集了 382 个用户查询。 每个场景的具体工具类别在下图列出。
工具学习必须的五个能力维度如下:
格式对齐是工具学习至关重要的一项基本能力,要求LLM遵守指令中的输出格式要求,确保正确解析其输出。 这包括 1) 合并相应的关键字(例如思想、行动、行动输入)以促进输出分离,2) 避免生成冗余句子以实现工具和参数的提取。
意图理解取决于工具学习的固有特征,侧重于把握用户需求并进行后续分析。 评估LLM是否能够不断更新所获取的信息,并调整解决方案以适应整个过程中不断变化的用户输入或不断变化的需求,这一点至关重要。 为了评估,分析:1)他们的思维过程与用户需求的相关性和 2)他们在交互过程中对新提供信息的适应性,来确定LLM的意图理解能力。
行为规划在促进LLM的工具学习和评估思维能力方面发挥着至关重要的作用。 与 (Wei 2022b)提出的见解一致。 对LLM如何选择工具和处理信息的全面理解不仅仅是工具和参数的选择。 对于LLM来说,简明地总结所获得的相关信息并对后续步骤进行战略性规划至关重要。在评估LLM的思维过程时,分别审查他们思维的有效性和逻辑完整性。 关于有效性,评估 1)总结当前状态的合理性,2)计划下一系列行动的及时性,以及 3)计划的多样性。 对于逻辑一致性,评估 1)语法健全性、2)逻辑一致性和 3)纠正思维的能力。
工具选择是工具学习的一个关键方面,评估LLM选择合适工具和输入准确参数的能力。 认识到模型通过工具解决问题的方法并不总是单一的,如查询两个城市 A 和 B 的天气情况,先查询 A 和先查询 B 在功能上是等效的,因此已经不再使用以前的预设答案和匹配结果的方法。 相反,在工具选择过程中强调的是真实性和有效性。 对于第i轮有效输出,评估包括两个关键方面:1)仔细审查LLM的工具选择和参数输入是否符合工具文档中概述的要求。 这涉及确认所选工具是否已记录、填充的参数是否与该工具相对应以及是否包含所有必要的参数。 2)在指令中提示LLM明确阐明他们在工具选择背后的思维过程,并将他们选择的工具与他们陈述的思维过程进行比较。
答复组织标志着工具学习的最后阶段,要求LLM合并整个过程中收集的信息,并对用户的查询提供直接响应。 该评估从两个维度展开:1)评估LLM及时做出回应的能力。 2) 审查LLM提供答复的质量,评估基于响应与用户查询的相关性以及所传达信息的准确性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









