









24年4月斯坦福大学论文“Octopus v2: On-device language model for super agent”。
语言模型已在各种软件应用程序中显示出有效性,特别是在与自动工作流程相关的任务中。 这些模型拥有调用函数的关键能力,这对于创建AI智体至关重要。 尽管云环境中的大语言模型具有高性能,但它们通常与隐私和成本问题相关。 当前用于函数调用的设备端模型面临延迟和准确性问题。 本文研究提出了一种方法,使具有 2B个参数的设备上模型能够在准确性和延迟方面超越 GPT-4 的性能,并将上下文长度减少 95%。 与具有基于 RAG 的函数调用机制的 Llama-7B 相比,本文方法将延迟提高了 35 倍。 此方法将延迟降低到适合在生产环境中的各种边缘设备部署的水平,从而符合实际应用程序的性能要求。
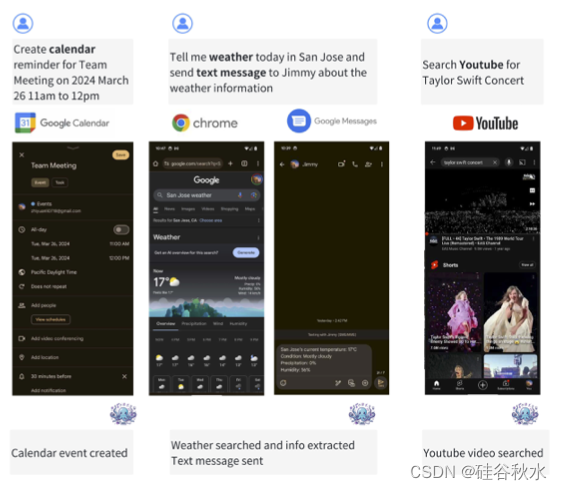
如图是Octopus在智能手机上的工作流:
由于内存限制和推理速度较低,在 PC 或智能手机等边缘设备上部署更大的模型具有挑战性。 尽管如此,将较小规模的大语言模型 (LLM) 部署到边缘设备的努力正在进行中。 已经引入了可管理大小的开源模型,例如 Gemma-2B、Gemma-7B、StableCode-3B(Pinnaparaju 2023)和 Llama-7B(Touvron 2023)。 为了提高这些模型在设备上的推理速度,已经开发了 Llama cpp(llama.cpp 2023)等研究计划。 MLC LLM 框架(MLC 2023)允许在手机和其他边缘设备上运行 7B 语言模型,展示了跨各种硬件(包括 AMD、NVIDIA、Apple 和 Intel GPU)的兼容性。
人们已经观察到较小规模模型的函数调用能力取得了快速进步。 NexusRaven (Srinivasan 2023)、Toolformer (Schick 2024)、ToolAlpaca (Tang 2023)、Gorrilla (Patil 2023)、ToolLlama (Qin 2023) 和Taskmatrix(Liang 2023)等项目 ,已经证明7B和13B模型可以调用外部API,其功效与GPT-4相当。 开创性的 Octopus v1 项目甚至使 2B 模型的性能与 GPT-4 相当。 这项工作采用基于 RAG 的方法进行函数调用,其中模型根据用户的查询从大池中检索相关函数,然后使用这些函数作为上下文生成响应。
要成功调用函数,必须从所有可用选项中准确选择适当的函数并生成正确的函数参数。 这需要两个阶段的过程:函数选择阶段和参数生成阶段。 第一步涉及了解函数的描述及其参数,用户查询的信息为可执行函数创建参数。 直接策略可能会将分类模型与因果语言模型结合起来。 将 N 个可用函数想象为一个选择池,将选择挑战转化为 softmax 分类问题。
一种直接的分类方法是基于检索的文档选择,通过语义相似性识别与用户查询最匹配的功能。 或者可以使用分类模型将查询映射到特定的函数名称。 或者,自回归模型(例如 GPT 模型)可以在潜函数的上下文中根据用户的查询来预测正确的函数名称。 这两种方法本质上都将任务分为两部分,可能需要两个模型 π1 和 π2。
在多任务学习/元学习(Caruana 1997)原理的驱动下,为了实现更快的推理速度和系统便利性,追求统一的 GPT 模型策略,设置 π1 = π2 = π。
当利用语言模型来制定函数名称时,必须生成多个tokens来形成一个函数名称,这可能会导致不准确。 为了减少此类错误,将函数指定为独特的功能tokens。 例如,在 N 个可用函数池中,分配从 <nexa_0> 到 <nexa_N-1> 范围的token名称来符号化这些函数。 这将函数名称的预测任务转化为 N 个功能tokens之间的单token分类,提高了函数名称预测的准确性,同时减少了所需tokens的数量。 为了实现这一点,将从 <nexa_0> 到 <nexa_N-1> 的新特殊tokens引入到tokenizer中,并修改预训练模型的架构,语言头扩展额外的 N 个单元。 因此,对于函数名称预测,语言模型通过 argmax 概率选择来确定 N 个功能tokens中的正确函数。
为了选择一个正确的功能token,语言模型必须掌握与该token相关的含义。 将功能描述合并到训练数据集中,使模型能够了解这些专用tokens的重要性。
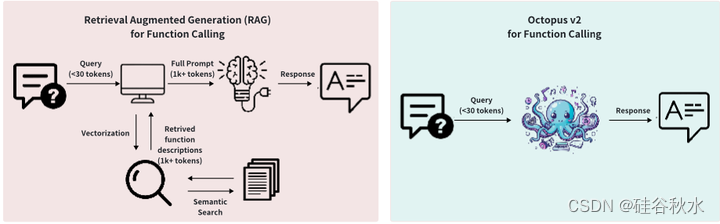
该方法还有一个额外的关键优势。 在对模型进行微调以了解功能tokens的重要性后,可以使用添加的特殊tokens,<nexa_end>作为早期停止标准进行推理。 该策略消除了从功能描述中分析tokens的必要性,消除了相关功能的检索及其描述的处理。 因此,这大大减少了准确识别函数名称所需的tokens数量。 传统的基于检索的方法与所提出的模型之间的差异如图所示。
作为示例,从 Android API 开始。 选择标准包括可用性、使用频率和技术实施的复杂性。 最终收集了 20 个 Android API,并将它们分为三个不同的类别,确保只要开发人员拥有必要的系统权限,每个功能都可以通过 Android 应用程序开发在设备上实际执行。 此外,还编译了车辆中可用的 API。
数据集的创建涉及三个关键阶段:(1)生成相关查询及其关联的函数调用参数; (2) 适当的函数体陪伴下提出不相关的询问; (3) 通过 Google Gemini 实现二进制验证支持。
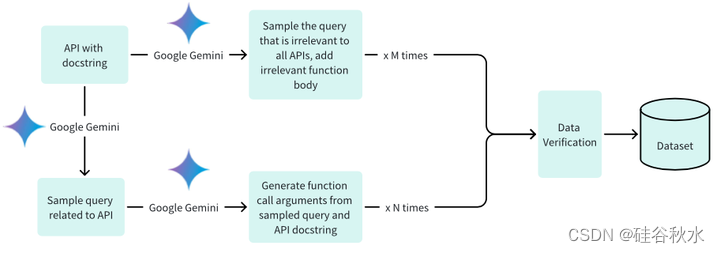
如图所示是生成数据集的过程,这涉及两个关键阶段:(1)创建特定于某些 API 的可解决查询并为其生成适当的函数调用,以及(2)创建不可解决的查询,并由不相关的函数体陪伴。 结合二进制验证机制进行严格验证可确保收集优化的训练数据集,从而显着改进模型功能。
尽管 OpenAI 的 GPT-4 和 Google 的 Gemini 等大语言模型具有先进的功能,但错误率仍然很高,特别是在函数调用参数的生成方面。 这些错误可能表现为缺少参数、不正确的参数类型或对预期查询的误解。 为了缓解这些缺点,引入了验证机制。 该系统允许 Google Gemini 评估其生成的函数调用的完整性和准确性,如果发现输出缺失,它会启动重新生成过程。
采用 Google Gemma-2B 模型作为框架中的预训练模型。 该方法融合了两种不同的训练方法:完整模型训练和 LoRA 模型训练。 对于完整的模型训练,用 AdamW 优化器,其学习率设置为 5e-5,预热步骤为 10,以及线性学习率调度器。 LoRA 训练应用相同的优化器和学习率配置。 将 LoRA 等级指定为 16,并将 LoRA 应用于以下模块:q_proj、k_proj、v_proj、o_proj、up_proj、down_proj。 LoRA alpha 参数设置为 32。对于两种训练方法(全模型和 LoRA),将 epoch 数设置为 3。















 1021
1021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









