










NVIDIA FasterTransformer (FT) 是一个用于实现基于Transformer的神经网络推理的加速引擎。它是Transformer高度优化版本的实现,其中包含编码器和解码器部分。使用此模块,可以运行编码器-解码器架构模型(如T5)、仅编码器架构模型(如BERT)和仅解码器架构模型(如GPT)的推理。
https://github.com/NVIDIA/FasterTransformer
FT框架是用C++/CUDA编写的,依赖于高度优化的 cuBLAS、cuBLASLt 和 cuSPARSELt 库,可以在 GPU 上进行快速的 Transformer 推理。
与 NVIDIA TensorRT 等其他编译器相比,FT 的最大特点是,支持分布式地进行 Transformer 大模型推理。
为了解决模型大小带来的延迟和内存瓶颈,FasterTransformer 为内核提供了高效率、优化的内存使用以及多个框架上的模型并行性。
根据当前 GPU 对权重进行离线预处理,以优化张量核消耗的权重对齐。 目前,直接使用 FP32/BF16/FP16 权重并在推理之前对其进行量化。 如果想要存储量化权重,则必须针对要用于推理的 GPU 对其进行预处理。
使用 torch API 时,int8 模式只能通过并行 GPT 操作使用。 并行 GPT Op 也可以在单个 GPU 上使用。
如图展示了 FasterTransformer GPT 的工作流程。 与 BERT 和编码器-解码器结构不同,GPT 接收一些输入 id 作为上下文,并生成相应的输出 id 作为响应。 在此工作流程中,主要瓶颈是 GptDecoderLayer(Transformer块),因为当增加层数时,时间会线性增加。 在 GPT-3 中,GptDecoderLayer 大约占用总时间的 95%。
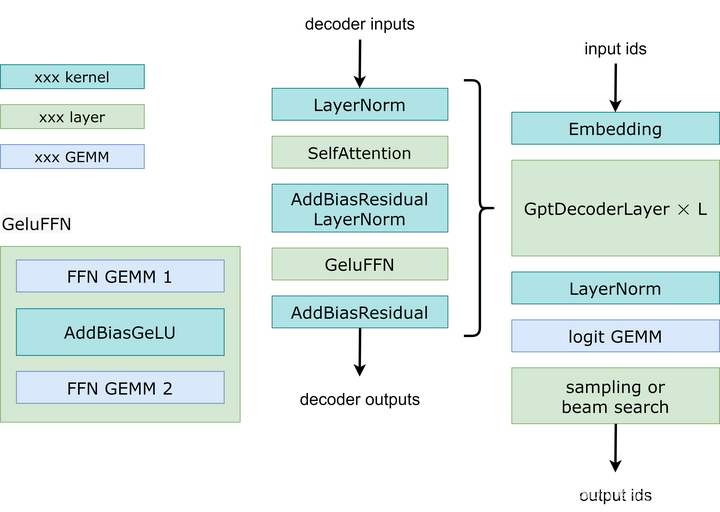
FasterTransformer 将整个工作流程分为两部分。 第一部分是“计算上下文(输入 id)的 k/v 缓存“,第二部分是“自回归生成输出 id”。 这两部分的操作类似,但是SelfAttention中张量的形状不同。 因此,用两种不同的实现来处理两种不同的情况,如下图所示。在 DecoderSelfAttention 中,查询的序列长度始终为 1,因此用自定义的融合掩码多头注意内核来处理。 另一方面,ContextSelfAttention 中查询的序列长度是最大输入长度,因采用 cuBLAS 来利用张量核心。

内核优化:很多内核都是基于解码器和解码模块的内核,这些内核已经高度优化。 为了防止重新计算以前的Key和Value,在每一步分配一个缓冲区来存储它们。 虽然需要一些额外的内存使用,但可以节省重新计算的成本、每一步分配缓冲区的成本以及连接的成本。
内存优化:与 BERT 等传统模型不同,GPT-3 有 1750 亿个参数,即使以半精度存储模型也需要 350 GB。 因此,必须减少其他部分的内存使用。 在FasterTransformer中,重用不同解码器层的内存缓冲区。 由于 GPT-3 的层数为 96,因此只需要 1/96 的内存。
模型并行性:在GPT模型中,FasterTransormer同时提供张量并行性和流水线并行性。 对于张量并行性,FasterTransformer 遵循了Nvidia Megatron-LM(一组基于Transformer的大语言模型)的想法。 对于自注意块和前馈网络块,按行分割第一个矩阵乘法的权重,按列分割第二个矩阵乘法的权重。 通过优化,可以将每个Transformer块的归约(reduction)操作减少到 2 次。 工作流程如下图所示。为了实现流水线并行性,FasterTransformer 将整批请求拆分为多个微批次,并隐藏通信气泡。 FasterTransformer会针对不同情况自动调整微批量大小。 用户可以通过修改gpt_config.ini文件来调整模型并行度。 建议在节点内使用张量并行,在节点间使用流水线并行,因为张量并行需要更多的 NCCL 通信。
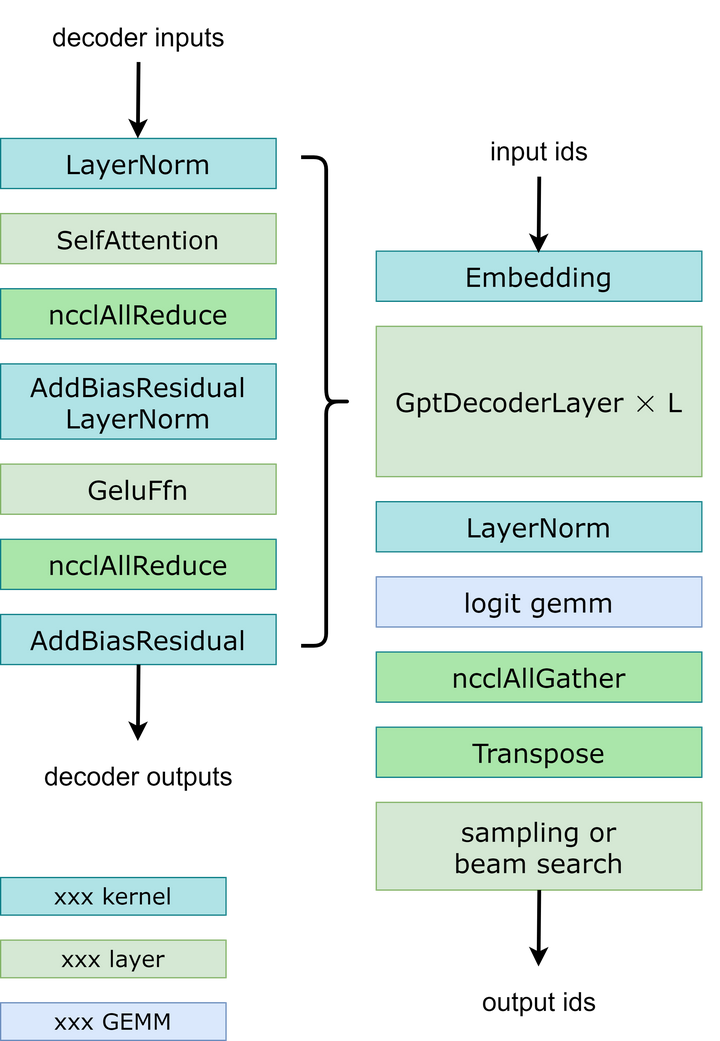
多框架:除了c的源代码外,FasterTransformer还提供TensorFlow op、PyTorch op和Triton后端。 目前,TensorFlow op 仅支持单 GPU,而 PyTorch op 和 Triton backend支持多 GPU 和多节点。 为了避免为了模型并行而进行模型分割的额外工作,FasterTransformer还提供了一个工具来将Nvidia Megatron的模型(即基于Transformer的一组大语言模型)分割并转换为二进制文件,然后FasterTransformer可以直接以二进制方式加载这些模型。
目前,FT 支持了 Megatron-LM的GPT-3、GPT-J、BERT、ViT、Swin Transformer、Longformer、T5 和 XLNet 等模型。
注:Megatron-LM是一组大型Transformer模型,由 NVIDIA 应用深度学习研究团队开发。 该存储库用于正在进行的大规模训练Transformer 语言模型的研究。 其用混合精度开发了基于 Transformer 模型(例如 GPT、BERT 和 T5等)的高效、模型并行(张量、序列和流水线)和多节点预训练实现。
https://github.com/NVIDIA/Megatron-LMgithub.com/NVIDIA/Megatron-LM















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









