










23年8月来自复旦大学、上海AI实验室和江西财经大学的论文“Experts Weights Averaging: A New General Training Scheme for Vision Transformers“。
结构重新参数化是卷积神经网络的一种通用训练方案,在不增加推理成本的情况下提高性能。随着视觉Transformer(ViTs)在各种视觉任务中逐渐超越CNN,人们可能会质疑:是否存在专门针对ViTs的训练方案,可以在不增加推理成本的情况下实现性能改进?最近,混合专家(MoE)越来越受到关注,因为它可以通过稀疏激活的专家以固定成本有效地扩大Transformer的容量。考虑到MoE也可以被视为一个多分支结构,可以利用MoE来实现类似于结构重新参数化的ViT训练方案吗?
本文肯定地提出一种ViTs通用训练策略。具体来说,将ViT的训练和推理阶段解耦。在训练过程中,用专门设计的、更高效的MoE替换ViT的一些前馈网络(FFN),这些MoE通过随机均匀分割将tokens分配给专家,并在每次迭代结束时对这些MoE执行专家权重平均(EWA)。训练后,通过专家平均,将每个MoE转换为FFN,将模型转换回原始ViT进行推理。文中给出一个理论分析来说明如何工作。跨各种2D和3D视觉任务、ViT架构和数据集的综合实验验证了所提出的训练方案其有效性和可推广性。此外,训练方案也可以用于提高微调ViT时的性能。最后,但同样重要的是,所提出的EWA技术可以提高原始MoE在各种2D视觉小数据集和3D视觉任务中的有效性。
如图是训练和推理的比较:(a) MoE 块, (b) 结构重新参数化块, 和 © EWA 训练块。其中每个FFN定义一个MOE专家。
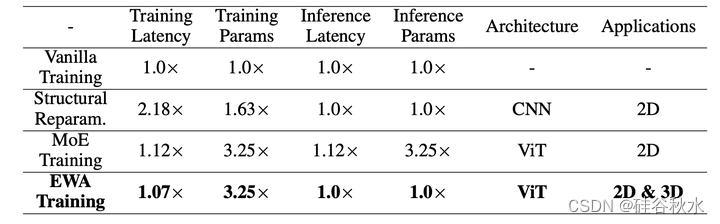
下表是训练、结构重新参数化、MoE训练和EWA训练的效果比较。
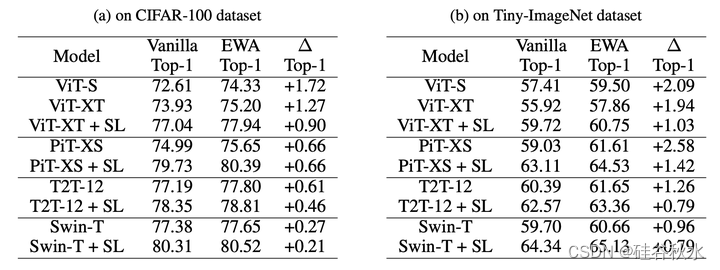
下表是各种架构和数据集上训练和EWA训练的性能比较。















 145
145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









