






深度学习自然语言处理 分享
整理:pp
 摘要:最近,Mixture of Experts专家混合(MoE)Transformers 因其在模型容量和计算效率方面的优势而受到越来越多的关注。然而,研究表明,MoE Transformers在许多下游任务中的表现不如vanilla Transformers,这大大降低了 MoE 模型的实用价值。为了解释这个问题,我们提出模型的预训练性能和转移能力是其下游任务性能的共同决定因素。与 vanilla 模型相比,MoE 模型的迁移能力较差,导致其在下游任务中表现不佳。为了解决这个问题,我们引入了 "transfer capability distillation "的概念,认为虽然vanilla模型的性能较弱,但它们是迁移能力的有效教师。由 vanilla 模型指导的 MoE 模型可以同时获得较强的预训练性能和迁移能力,最终提高它们在下游任务中的性能。我们设计了一种特定的蒸馏方法,并在 BERT 架构上进行了实验。实验结果表明,MoE 模型的下游性能有了显著提高,许多进一步的证据也有力地支持了转移能力蒸馏的概念。最后,我们试图从模型特征的角度解释转移能力蒸馏并提供一些见解。
摘要:最近,Mixture of Experts专家混合(MoE)Transformers 因其在模型容量和计算效率方面的优势而受到越来越多的关注。然而,研究表明,MoE Transformers在许多下游任务中的表现不如vanilla Transformers,这大大降低了 MoE 模型的实用价值。为了解释这个问题,我们提出模型的预训练性能和转移能力是其下游任务性能的共同决定因素。与 vanilla 模型相比,MoE 模型的迁移能力较差,导致其在下游任务中表现不佳。为了解决这个问题,我们引入了 "transfer capability distillation "的概念,认为虽然vanilla模型的性能较弱,但它们是迁移能力的有效教师。由 vanilla 模型指导的 MoE 模型可以同时获得较强的预训练性能和迁移能力,最终提高它们在下游任务中的性能。我们设计了一种特定的蒸馏方法,并在 BERT 架构上进行了实验。实验结果表明,MoE 模型的下游性能有了显著提高,许多进一步的证据也有力地支持了转移能力蒸馏的概念。最后,我们试图从模型特征的角度解释转移能力蒸馏并提供一些见解。
https://arxiv.org/abs/2403.01994
Q1: 这篇论文试图解决什么问题?
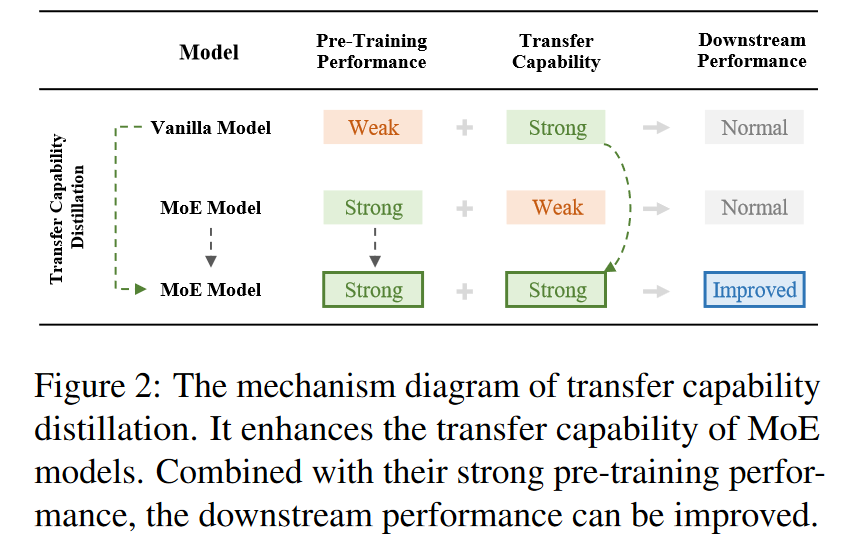
A:这篇论文试图解决的问题是Mixture of Experts (MoE) Transformers在下游任务中相较于传统的Transformers(即vanilla Transformers)性能不足的问题。尽管MoE Transformers在预训练语言建模任务中表现出色,但在许多下游任务中,尤其是在涉及大量专家时,它们的有效性显著降低。论文指出,MoE模型的这一问题主要是由于它们具有较弱的转移能力(transfer capability),即模型将预训练阶段学到的知识迁移到新任务的能力。
为了解决这一问题,论文提出了转移能力蒸馏(Transfer Capability Distillation, TCD)的概念。该方法利用具有较强转移能力的vanilla模型作为教师,指导MoE模型学习,以提高其在下游任务中的性能。通过这种方法,MoE模型不仅能够保持其在预训练阶段的强大性能,还能够获得更强的转移能力,从而在下游任务中取得更好的表现。论文通过在BERT架构上设计特定的蒸馏方法并进行实验,验证了TCD方法的有效性,并从模型特征的角度提供了对转移能力蒸馏的解释。
Q2: 有哪些相关研究?
A:这篇论文提到了以下几项与MoE Transformers和转移能力蒸馏相关的研究:
MoE模型:
Jacobs et al. (1991) 提出了自适应混合专家(Adaptive Mixtures of Local Experts)的概念。
Shazeer et al. (2017) 首次展示了MoE架构可以适应深度神经网络,并将其添加到LSTM中。
Lepikhin et al. (2021) 使用MoE架构的Transformer模型提高了机器翻译性能。
Fedus et al. (2022) 提出了Switch Transformers,展示了MoE Transformers在预训练语言模型中的应用。
Artetxe et al. (2022) 对MoE Transformer进行了广泛的实验,证明了其在效率上相较于密集语言模型的显著优势。
转移能力蒸馏(TCD):
Hinton et al. (2015) 提出了知识蒸馏的概念,将大模型学到的知识转移到小模型中。
Sun et al. (2019) 通过输出蒸馏和隐藏表示蒸馏将BERT压缩成更浅的模型。
Sanh et al. (2020) 成功地通过蒸馏在预训练和微调阶段将BERT的层数减半。
Jiao et al. (2020) 设计了一种涵盖预训练和微调阶段的BERT蒸馏方法,使用多位置约束。
Sun et al. (2020) 提出了一种保留转移能力的蒸馏方法,提供了更大的灵活性。
其他相关研究:
Devlin et al. (2019) 提出了BERT模型,这是预训练语言模型的开创性工作。
Brown et al. (2020) 和 OpenAI (2023) 展示了预训练语言模型的强大泛化能力和通过扩展模型规模提升性能的能力。
Kaplan et al. (2020) 和 Hoffmann et al. (2022) 分析了大型语言模型训练的计算效率。
这些研究为MoE Transformers的设计、优化以及转移能力蒸馏方法提供了理论基础和技术背景。论文通过结合这些研究成果,提出了一种新的提升MoE模型在下游任务中性能的方法。
Q3: 论文如何解决这个问题?
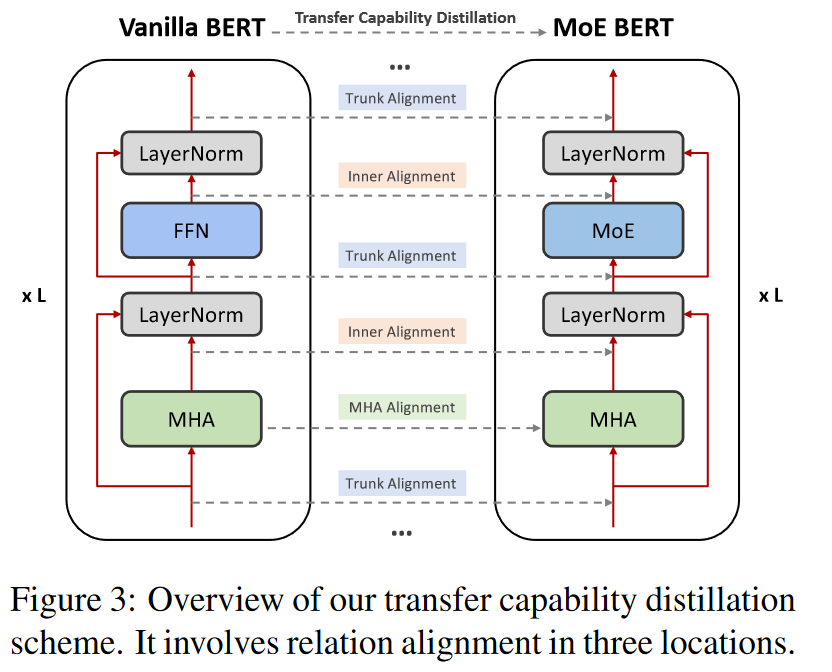
A:论文通过提出转移能力蒸馏(Transfer Capability Distillation, TCD)的概念来解决MoE Transformers在下游任务中性能不足的问题。具体方法如下:
教师模型的选择:选择一个预训练的vanilla BERT模型作为教师模型。尽管这个模型在预训练和下游任务中的性能较弱,但它具有强大的转移能力。
学生模型的预训练:在预训练MoE BERT模型(学生模型)时,不仅优化原始的预训练损失(如掩码语言建模损失),还优化一个新的转移能力蒸馏损失。这涉及到在学生模型的预训练过程中,引入与教师模型相关的额外损失项。
关系对齐:在学生模型和教师模型之间对齐中间层的表示关系。这包括模型主干(Model Trunk)、残差内部(Residual Inner)和多头注意力(Multi-Head Attention)等位置的关系对齐。通过计算这些位置的余弦相似度,并使学生模型的表示与教师模型的表示对齐,从而提高学生模型的转移能力。
损失函数的设计:设计了三种类型的蒸馏损失(LT, LI, LA),分别对应于模型主干、残差内部和多头注意力的对齐。这些损失函数通过最小化学生模型和教师模型在这些位置的表示之间的差异来实现。
实验验证:在BERT架构上进行实验,通过在GLUE基准测试上的微调来验证TCD方法的有效性。实验结果表明,经过TCD处理的MoE模型在下游任务中的性能显著提高,甚至超过了其教师模型。
模型特征的分析:从模型特征的角度提供对转移能力蒸馏的解释,认为转移能力的提高可能与预训练阶段学习到的特征质量有关。通过蒸馏,学生模型能够利用更高质量的特征来完成预训练任务,从而间接提高了其转移能力。
通过这种方法,论文不仅解决了MoE模型在下游任务中的性能问题,还为未来在这一领域的研究提供了新的视角和方法。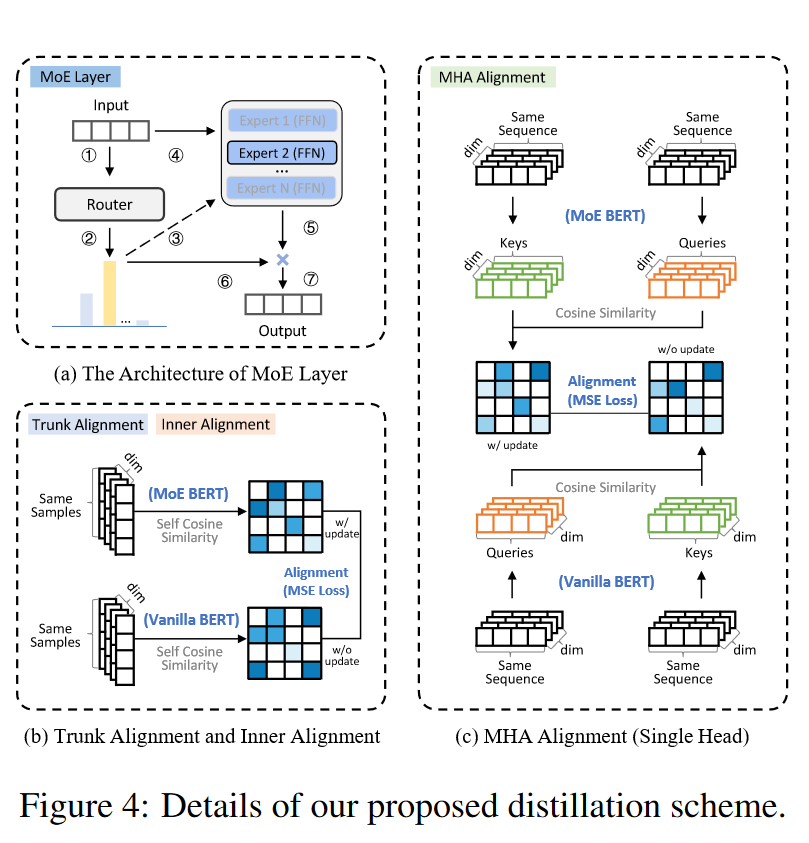
Q4: 论文做了哪些实验?

A:论文中进行了一系列实验来验证转移能力蒸馏(TCD)方法的有效性。以下是主要的实验内容:
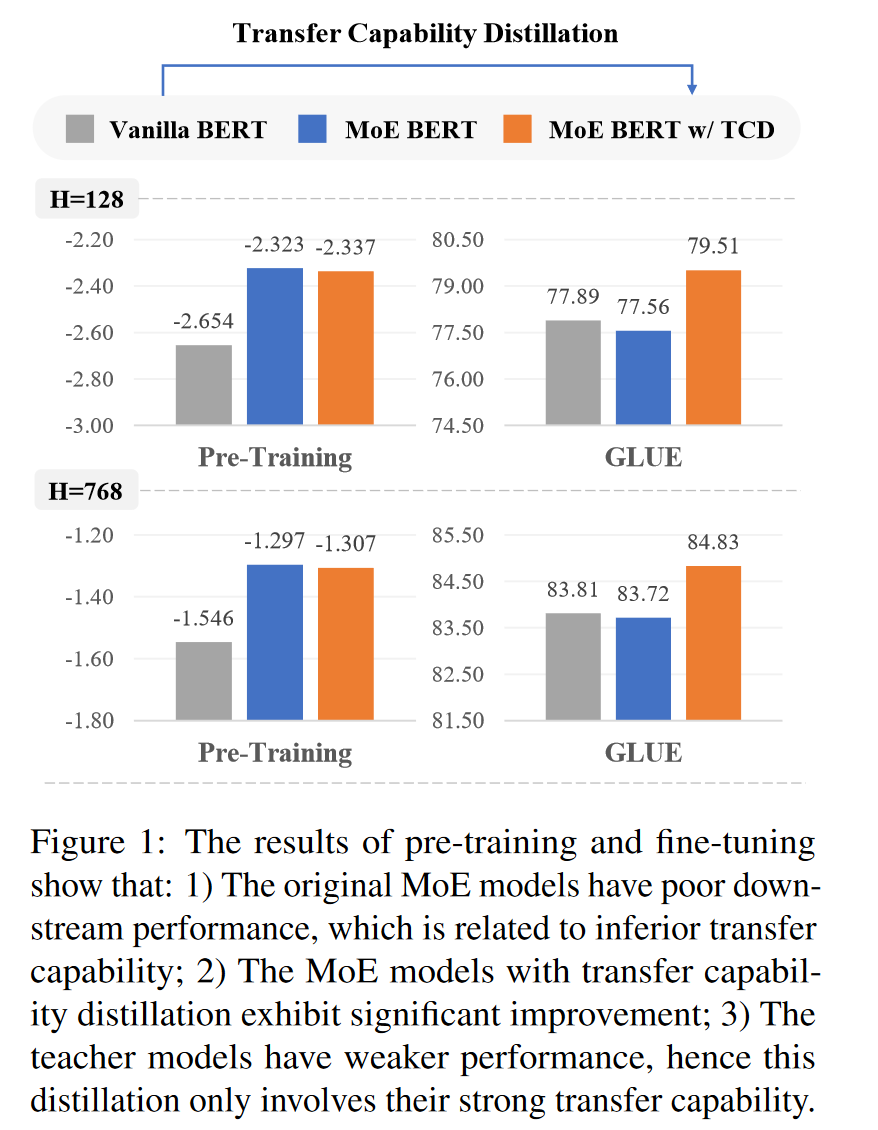
预训练性能对齐实验:通过确保一般预训练的MoE BERT和经过TCD的MoE BERT在掩码语言建模任务的验证集上具有等效性能,然后比较它们在下游任务上的性能。这允许更直观地评估新模型转移能力的改进。
预训练轮数对齐实验:为了验证TCD方法在更公平的预训练步骤设置下的实际价值,作者增加了基线MoE BERT的预训练轮数,以匹配教师模型和学生模型的总预训练轮数。比较了在这种情况下,新模型和基线模型在下游任务上的性能。
消融分析:为了探索模型主干(Model Trunk, T)、残差内部(Residual Inner, I)和多头注意力(Multi-Head Attention, A)这三个位置的关系对齐的必要性,作者进行了消融实验。通过在不同配置下比较模型在下游任务上的性能,来确定这些位置对转移能力的影响。
趋势分析:为了更直观地展示MoE BERT在下游任务(如MRPC任务)上的性能趋势,作者分析了不同预训练轮数下模型的性能。这有助于展示TCD方法如何有效地提高MoE BERT的转移能力。
下游任务性能测试:在GLUE基准测试上对模型进行了微调,以评估TCD方法在多个下游自然语言理解任务上的性能。这包括了CoLA、MRPC、SST-2、STS-B、RTE、MNLI、QNLI和QQP等任务。
模型特征分析:为了解释TCD方法的有效性,作者还进行了模型特征的分析。这包括在预训练阶段对模型进行掩码语言建模能力的测试,以及在预训练性能对齐后,使用额外的OOD(Out-of-Distribution)语料库来测试模型的泛化能力。
这些实验结果支持了TCD方法能够显著提高MoE模型在下游任务中的性能,并证实了vanilla Transformer模型作为转移能力教师的有效性。
Q5: 有什么可以进一步探索的点?
A:尽管论文提出了转移能力蒸馏(TCD)的概念并验证了其有效性,但仍有一些方面可以进一步探索:
教师模型的预训练水平:论文中提到,教师模型的预训练水平可能会影响转移能力蒸馏的效果。未来的研究可以探索不同预训练水平的教师模型对蒸馏效果的具体影响。
更大规模的模型:论文中使用了两种规模的模型进行实验,但在更大规模的模型上验证TCD方法的效果尚未进行。未来的工作可以考虑在更大的模型上应用TCD,并研究其性能。
不同任务和数据集:论文主要在GLUE基准测试上进行了实验。未来的研究可以在更多样化的任务和数据集上测试TCD方法,以验证其泛化能力。
蒸馏机制的深入理解:论文提出了转移能力可能与预训练阶段学习到的特征质量有关。未来的研究可以更深入地探索转移能力和特征质量之间的关系,以及如何更有效地通过蒸馏来改善特征质量。
多任务学习和迁移学习:研究TCD方法在多任务学习和迁移学习场景中的应用,以及如何结合不同的蒸馏策略来提高模型在多个任务上的性能。
计算效率和资源优化:考虑到大规模模型的预训练和蒸馏过程需要大量的计算资源,研究如何优化TCD方法以提高计算效率和降低资源消耗。
模型解释性:提高模型的可解释性,以便更好地理解TCD过程中模型是如何学习转移能力的,以及教师模型和学生模型之间的知识是如何传递的。
跨领域应用:探索TCD方法在不同领域(如计算机视觉、语音识别等)的应用,以及如何调整方法以适应不同领域的特定需求。
通过这些进一步的探索,研究者可以更全面地理解转移能力蒸馏的原理,提高其在实际应用中的有效性和效率。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
问题定义:论文指出MoE Transformers在预训练语言建模任务中表现出色,但在许多下游任务中性能不足,特别是当涉及大量专家时。这一问题归因于MoE模型相较于vanilla Transformers具有较弱的转移能力。
转移能力蒸馏(TCD):为了解决MoE模型的转移能力问题,论文提出了转移能力蒸馏的概念。这种方法利用具有较强转移能力的vanilla模型作为教师,通过蒸馏过程来提升MoE模型的转移能力。
实验设计:论文设计了一系列实验来验证TCD方法的有效性。实验包括预训练性能对齐、预训练轮数对齐、消融分析以及在GLUE基准测试上的下游任务性能测试。
实验结果:实验结果表明,经过TCD处理的MoE模型在下游任务中的性能显著提高,甚至超过了其教师模型。这支持了TCD方法的有效性,并证实了vanilla Transformers作为转移能力教师的潜力。
模型特征分析:论文从模型特征的角度提供了对TCD方法的解释,认为转移能力的提高可能与预训练阶段学习到的特征质量有关。通过蒸馏,学生模型能够利用更高质量的特征来完成预训练任务,从而间接提高了其转移能力。
未来研究方向:论文提出了一些未来研究的方向,包括探索教师模型预训练水平对TCD效果的影响、在更大规模模型上应用TCD方法、以及深入理解转移能力和特征质量之间的关系等。
局限性:尽管TCD方法在实验中取得了积极结果,但论文也指出了一些局限性,如教师模型预训练水平的选择、模型规模的扩展以及对TCD机制更深入理解的需求。
总的来说,这篇论文提出了一种新的方法来提升MoE Transformers在下游任务中的性能,并通过实验验证了其有效性,同时也为未来的研究提供了新的方向和思路。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦















 4000
4000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









