









23年12月巴黎的Sorbonne大学论文“UnIVAL: Unified Model for Image, Video, Audio and Language Tasks”。
大语言模型 (LLM) 使得对通才智体的雄心勃勃的追求不再是一个幻想。 构建此类通用模型的一个关键障碍是任务和模态的多样性和异质性。 一种有希望的解决方案是统一,允许在一个统一的框架内支持无数的任务和模态。 虽然在海量数据集上训练的大模型(例如 Flamingo(Alayrac,2022))可以支持两种以上的模态,但当前的中小型统一模型仍然仅限于 2 种模态,通常是图像文本或 视频文本。 问题是:是否有可能有效地构建一个可以支持所有模态的统一模型? 为此提出UnIVAL,∼ 0.25B 参数 UnIVAL 模型不依赖于花哨的数据集大小或具有数十亿参数的模型,超越了两种模态,并将文本、图像、视频和音频统一到单个模型中。 基于任务平衡和多模态课程学习,该模型针对许多任务进行了有效的预训练。 从图像和视频文本模态中学习的特征表示,使得模型在音频文本任务上进行微调时能够实现有竞争力的性能,尽管没有对音频进行预训练。 得益于统一模型,提出一项对不同多模态任务训练的模型进行权重插值来进行多模态模型合并的研究,展示了其对于分布外泛化的好处。 最后,展示任务之间的协同作用来激励统一。
模型权重和代码可在以下网址获取:
https://github.com/mshukor/UnIVAL。
预训练多模态模型的主流方法围绕在大型、嘈杂的图像描述数据集上进行训练(Schuhmann et al., 2021; Jia et al., 2021; Radford et al., 2021),其中模型的任务是生成或通过因果生成或去掩码来对齐图像字幕。 然而,这种方法遇到了一个重大挑战:它依赖于广泛的数据集来补偿固有的噪声和相对简单的字幕生成任务。 相比之下,在相对较小但高质量的数据集上进行多任务学习(Caruana,1997)提供了一种替代解决方案来学习与大规模对应模型竞争的高效模型(Alayrac,2022;Chen,2022b;Reed,2022)。
目前的中小规模(少于几亿个参数)视觉语言模型(Li et al., 2019; Shukor et al., 2022; Dou et al., 2021; Li et al., 2022b)仍然有特定于任务的模块/头和多个的训练目标,由于不同的输入/输出格式其只能支持极少量的下游任务。 最近,序列到序列 OFA (Wang et al., 2022c) 和 Unified-IO (Lu et al., 2022a) 朝着更统一的系统迈出了显着的一步,可以支持广泛的图像和图像文本任务,具有更合理的规模大小(例如可以适合用户级 GPU)。 这些模型根据许多高质量的公共基准进行了预训练。 在视频-文本任务上,LAVENDER(Li et al., 2022c)采取了类似的方向,将预训练任务统一为掩码语言建模(MLM)。 序列到序列的统一模型特别适合开放式文本生成任务,并且可以轻松合并最新的LLMs。 为了指导模型解决特定任务,在输入序列的开头添加了类似于指令的文本提示(Raffel et al., 2020)。 它们能够统一不同模态的任务,从而通过将所有输入和输出表示为tokens序列,利用统一的输入/输出格式和词汇,轻松支持新任务。 这些tokens可以表示各种模态,例如文本、图像块、边框、音频、视频或任何其他模态,而不需要特定于任务的模块/头。 这些策略易于扩展和管理,因为它们涉及单一训练目标和单一模型。
然而,现有的工作仍然仅限于不超过 2 种模态(图像-文本或视频-文本)的下游任务。 跨大量任务和模态提供统一将带来附加的优势。 首先,利用他们的协作优势,从他们之间的知识迁移中受益。 其次,一旦预训练完成,模型就可以在许多不同的数据集上进行微调:由于预训练数据的范围更广、更多样化,在对新任务和模态进行微调后,跨更多任务的统一将能够实现更好、更高效的泛化。
问题是:是否有可能有效地构建一个可以支持所有模态的统一模型?
对这个问题的积极回答将为构建可以解决任何任务的通才模型铺平道路。 为了回答这个问题,提出UnIVAL,这是向通用模态-不可知模型迈出的一步。 UnIVAL(如图所示)超越了两种模态,将文本、图像、视频和音频统一到一个模型中:序列到序列模型统一了架构、任务、输入/输出格式和训练目标(对下一个token的预测);UnIVAL 针对图像和视频文本任务进行了预训练,并且可以进行微调以处理预训练期间未使用的新模态(音频-文本)和任务(文本-到-图像生成)。

为了将多个专家模型与不同的专业相结合,用一个简单而实用的策略:权重空间中的线性插值。 按照(Ilharco 2023)(Daheim 2023)(Ortiz-Jimenez 2023)方法,对权重进行平均可以结合它们的能力,而无需任何计算开销。 特别是,权重平均 (WA) 在模型汤方法中被证明非常有用(Wortsman,2022;Rame,2022),可以改进分布外泛化,作为成本更高的预测平均近似值(Laksh - Minarayanan,2017)。 最近的工作将 WA 扩展到用不同损失微调权重 (Rame et al., 2022; 2023b; Croce et al., 2023) 或在不同数据集上 (Matena & Raffel, 2022; Choshen et al., 2022; Don-Yehiya,2023;Rame,2023a)。 此外,一些技术尝试利用在给定目标任务不同辅助任务上学到的特征。 Fusing(Choshen et al., 2022)对多个辅助权重进行平均,作为目标任务上独特的微调初始化。 相比之下,ratatouille 方法(Rame et al., 2023a) 对目标任务进行多次微调后延迟平均:每个辅助模型在目标任务上独立进行微调,然后对所有微调权重进行平均。 这些方法考虑了给定模态(通常是图像)的分类任务:对在不同多模态任务上训练的模型权重作插值方面研究很少。 最相似和同时进行的工作是最近的 (Sung 2023) ,该方法应用复杂的特定架构合并策略。 不同的是,UnIVAL在多模态下游任务的微调过程中探索 WA,合并了在不同模态上预训练的模型。
当前的多模态模型是在有限任务(例如图像条件文本生成)的大量噪声数据集上进行预训练的。 专注于在不依赖大量数据的情况下实现合理性能的挑战。 该方法涉及对许多优质数据集进行多任务预训练。 希望质量能够减轻对海量数据集的需求,从而减少计算需求,同时增强整体模型能力。 由于公共、人工注释或自动生成的数据集的可用性不断增加,采用这种方法变得越来越容易。 UnIVAL 沿以下 4 个轴统一:模型、输入/输出格式、预训练任务和训练目标。
模型的核心是一个旨在处理抽象表示的 LM。 它通过轻量级特定模态的投影进行增强,可以将不同模态映射到共享且更抽象的表示空间,然后可由 LM 进行处理。 在所有任务的预训练和微调过程中使用相同的模型,没有任何特定任务头。如图是UnIVAL模型架构图:编码器-解码器Transformer, 附加基于轻量CNN的模态编码器。
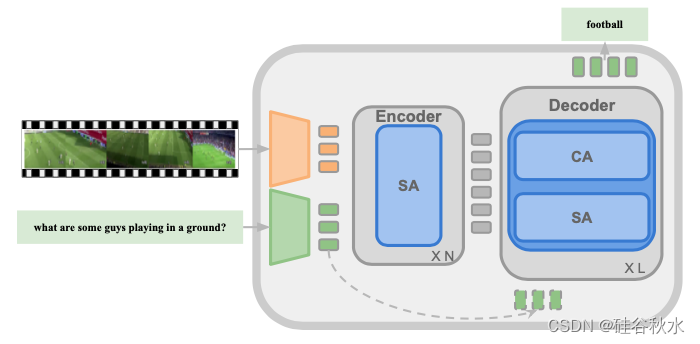
所有任务的输入/输出都由一系列tokens组成,其中用包含文本、位置和离散图像tokens的统一词汇表。
为了在许多任务上训练单一模型,这些任务的统一表示是必要的。 由于模型的核心是 LM,将所有任务转换为序列到序列的格式,其中每个任务都由文本提示指定(例如,视频字幕的“视频描述了什么?”)。
遵循其他方法(Wang,2022c;Alayrac,2022)并优化模型以进行下一个token预测。 具体来说,用交叉熵损失。除了跨任务和模态的统一之外,有效预训练技术也很重要,比如多模态课程学习、多模态任务平衡以及跨任务和模态的知识迁移。
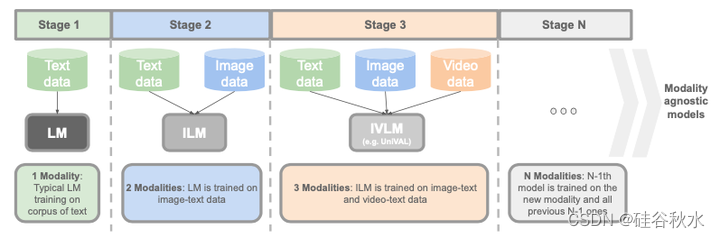
如图是多模态课程学习。 在不同阶段对 UnIVAL 进行预训练。 (1)第一次预训练是典型的在文本语料上进行语言模型的训练。 (2)然后,在图像和文本数据上训练模型以获得图像-语言模型(ILM)。 (3)在第三阶段,在视频-文本数据上对模型进行额外训练,以获得视频-图像-语言模型(VILM)。 为了获得模态不可知模型,应该对模型进行多种模态的训练。 按照此设置,UnIVAL 可用于解决图像/视频/音频文本任务。
任务和模态的协同采用在权重空间中的插值。 遵循权重插值方法(Izmailov ,2018;Wortsman,2022;Rame,2022)来合并在不同多模态任务上的微调模型,无需推理开销。 该框架具有统一的架构和共享的预训练(Neyshabur et al., 2020),自然地强制执行线性模式连接(Frankle et al., 2020),从而实现 在微调权重上对的平均性(不需要(Ainsworth2022) 那样的权重排列)。
考虑 4 个图像-文本任务; 图像字幕 (IC)、VQA、视觉落地 (VGround) 和视觉障碍 (VE)。然后,给定两个模型,权重 W1 和 W2 在这 4 个图像-文本任务中的2 个不同任务上进行微调 ,分析插值权重的新模型性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









