









24年5月来自微软的论文“An LLM-Tool Compiler for Fused Parallel Function Calling”。
大语言模型 (LLM) 中最先进的序贯推理已将 Copilot 的功能从对话任务扩展到复杂的函数调用,管理数千个 API 调用。然而,组合提示倾向于将任务分为多个步骤,每个步骤都需要到 GPT API的往返,这会导致系统延迟和成本增加。尽管并行函数调用方面的最新进展提高每个 API 调用的工具执行速度,但它们可能需要更详细的上下文指令和提示级的任务细分,其带来更高的工程和生产成本。受乘法加法 (MAD) 运算的硬件设计原理的启发,从编译器的角度将多个算术运算融合为一个任务,即 LLM-工具编译器(LLM-Tool Compiler),它在运行时有选择地将类似类的工具操作融合在单个函数下,将它们作为统一的任务呈现给 LLM。这种选择性融合,本质上增强并行和效率。
Copilot 性能的一项新进展是通过组合和序贯提示进行稳健推理,其中思维链 [36]、ReAct [41] 和思维树 [40] 等技术大大提高了函数调用基准。然而,它们倾向于将任务分解为单个步骤 [25],每个步骤都需要单独的 GPT OpenAI API 调用,这引入了严重的瓶颈,从而增加了tokens成本和系统延迟。并行函数调用的最新发展旨在在单个 API 响应中选择和执行多个工具[31]。值得注意的是,OpenAI 在其最近发布的 GPT Turbo 中引入了该功能,就体现了这一进步。尽管性能有所提高,但这些方法仍然经常需要细致入微的提示来有效地指导智体如何对功能进行分组。例如,提供上下文中以往多工具执行示例的少样本技术,通常需要复杂的、基于 RAG [21] 或基于意图 [10] 的动态提示方案。其中这些工具执行鼓励高效的函数选择。
一个关键点是,在实际的 LLM 工作负载中,数据通常表现出显着的时间相似性,类似工具的序列通常会连续执行。以一个支持 LLM 的地理空间分析平台为例,用户可能会简洁地询问“显示 10 月份新泽西州纽瓦克周围的卫星图像”。此查询自然涉及首先按位置过滤数据,然后按日期过滤数据。如果 LLM 可以将这些连续任务解释为单个功能 - 尽管系统仍在内部使用各自的代码处理它们 - 智体本质上会选择一个集成工具。这种方法本质上减少了多个单工具 API 调用的频率,从而简化了流程并提高了效率。
如图所示 LLM-工具编译器(LLM-Tool Compiler)融合并行函数调用。对于每个用户查询,编译器会动态识别要并发执行的工具和/或将类似函数融合到单个操作中。将它们作为统一任务呈现给 GPT,从本质上增强并行化和整体效率。结果表明,当与各种提示方案集成在一起时,LLM-工具编译器可将并行调用量提高多达五倍。
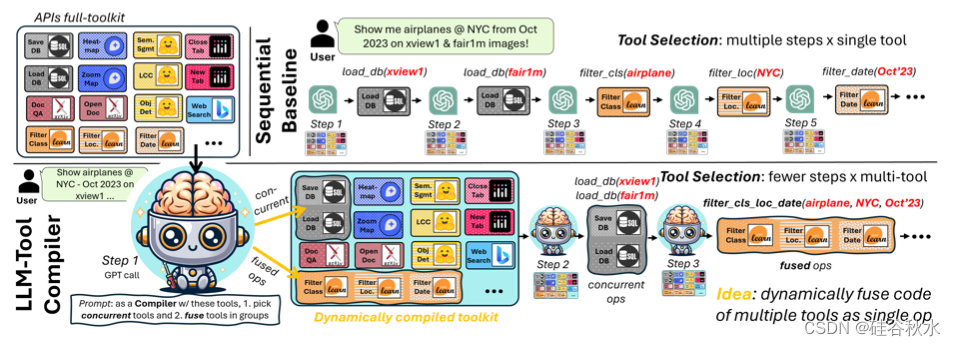
如图所示的任务,用户询问“在 xview1 和 FAIR1M 图像上显示 2023 年 10 月纽约市的飞机”。在这个全顺序基线中,此查询通过智体每一步调用和执行一个工具(即每个 GPT API 调用)来完成(顶部),其中显然可以同时执行多个工具。事实上,在这个特定的例子中,OpenAI 的最新版本通过同时执行加载操作实现并行化。
然而,还有很大的改进潜力,特别是对于后续的数据操作:事实上,GPT 基线目前只有四分之一的数据过滤操作并行执行。
假设数据操作的有限并行化,可能部分归因于 30 种不同数据工具之间的高度多样性。尽管每个函数定义都可供智体使用,但这些工具之间细微相互依赖关系可能并不明显。一种潜在的方法可能是采用过于详细的提示指令和精心设计的特定工具方向。然而,这种方法对于现实世界中大型 Copilot 系统 [17] 来说是不切实际的,因为更新生产代码来反映新的工具方面和相关性会很麻烦。事实上,即使更详细的提示指令在一个步骤中考虑更多的数据操作也不能确保智体执行多工具操作 [32]。
关键问题是,对于每个新的用户提示,如何动态确定要并行哪些任务并协调它们执行,而不会显着改变预先存在的函数调用过程。为了实现这一点,引入一个专用 GPT 驱动模块,以与智体无关的方式尽可能地解耦“编译”步骤。在执行任何工具之前,给定当前查询和完整的 API 工具集,此模块会识别可以一起调用类似工具的分组。这种设计将提示工作和工具编译限制在该模块中作为单独的函数调用,而不会替换或过度修改现有智体基线。如图(底部)所示,LLM-Tool Compiler 通过两个主要组件实现此目的:(i)融合器,识别相关工具并将它们聚合到单个函数中,动态更新对 LLM 智体可见的工具集;(ii)执行器,在后续函数调用过程中,监视智体的工具选择。如果选择了融合操作,则执行器负责分解和执行它们各自的代码块和相关项。
实验设置如下。
在 GeoLLM-Engine 基准 [34] 上评估 LLM-工具编译器,突出了该方法在复杂的长范围多工具遥感 (RS) 应用和卫星图像上的有效性。该基准及其相关引擎充当了一个现实世界的测试平台,配备了一套全面的开源 API、动态地图/Web UI,因为它支持各种为数据分析和地理空间任务量身定制的 Python 包,包括 RAG 和向量存储、用于交互式地图的 Mapbox API 和用于地理空间数据可视化和操作的 GeoPandas [33]。
该平台旨在处理数百种 API 工具中的 LLM,利用来自著名 RS LLM 基准的庞大地理空间数据存储库,包括超过 500 万张卫星图像和数十万个精心组织成 SQL 表的任务,以实现高效的查询和操作。此设置为实现和评估 LLM-工具编译器提供了理想的环境。
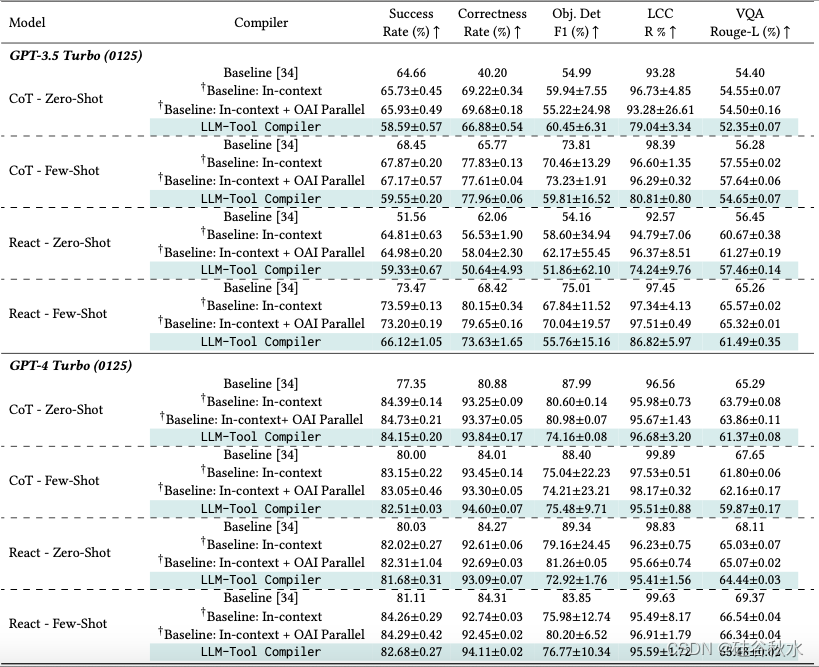
如下表是GPT-3.5 Turbo 和 GPT-4 Turbo 的系统和智体性能以及各种提示技术。
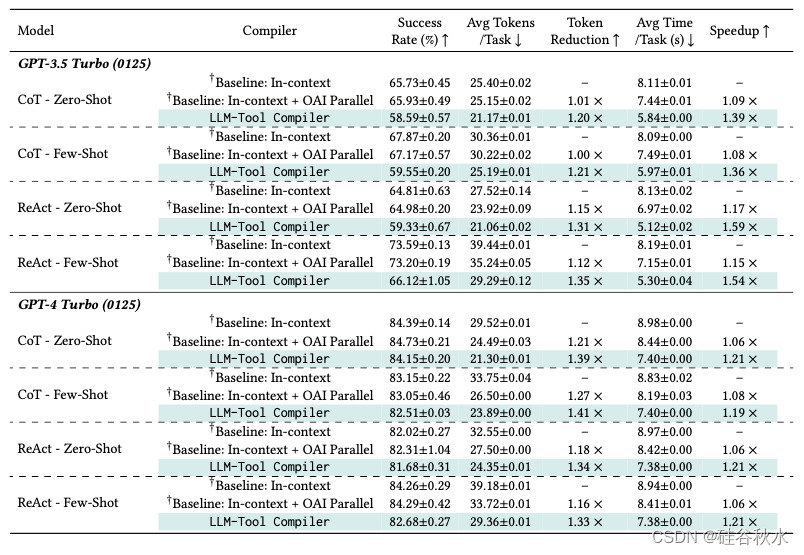
下表所示是智体性能指标与各种模型和提示技术基线相比。首先,改进 [34] 中先前报告的基线。使用原始提示,经常观察到错误的函数调用,但还是正确的底层逻辑。结合上下文提示,以尽可能提高智体性能,表示为 †Baseline。基线对应于没有提示的原始结果 [34]。















 1557
1557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









