









24年5月来自新泽西州立大学Rutgers的论文“AIOS Compiler: LLM as Interpreter for Natural Language Programming and Flow Programming of AI Agents”。
自诞生以来,编程语言就一直朝着可读性更高、编程门槛更低的方向发展。顺应这一趋势,自然语言可以成为一种很有前途的编程语言,它提供了极大的灵活性和可用性,有助于实现编程的民主化。然而,自然语言固有的模糊性、歧义性和冗长性对开发能够准确理解编程逻辑并执行自然语言编写指令的解释器提出了重大挑战。幸运的是,大语言模型 (LLM) 的最新进展已证明其在解释复杂自然语言方面具有卓越的能力。
受此启发,一种代码表示和执行系统 (CoRE),它使用 LLM 作为解释器来解释和执行自然语言程序 (NLPg)。所提出的系统将自然语言编程、伪代码编程和流编程统一在相同的表示下以构建语言智体,而 LLM 则作为解释器来解释和执行智体程序。首先定义编程语法,以逻辑方式构造自然语言指令。在执行过程中,整合外部内存以最大限度地减少冗余。此外,为设计的解释器配备调用外部工具的能力,以弥补 LLM 在专业领域或访问实时信息时的局限性。
开源地址:
https://github.com/agiresearch/CoRE
https://github.com/agiresearch/OpenAGI
GitHub - agiresearch/AIOS
所提出的一种代码表示和执行 (CoRE) 系统,以 LLM 作为解释器来解释和执行自然语言中的指令,从而实现自然语言的代理编程。
CoRE 可用于自然语言编程、伪代码编程和流编程,因为三种形式的智体程序统一到CoRE 语言中,如图示例所示。在编程领域,基本任务涉及设计和开发逻辑结构化的指令来解决特定问题。自然语言编程提供了一种方法,其中指令以日常语言制定,使代码直观易懂。当以逻辑方式构造所有自然语言指令时,它本质上反映伪代码编程的本质。伪代码在设计上通过剥离语法复杂性并专注于算法逻辑来简化编码过程,便于理解。因此,当指令以自然语言表达时,结构化指令可以被识别为伪代码。此外,伪代码与流编程有着直接的关系,因为它本质上表示算法的逻辑,可以无缝地视为工作流。反过来,工作流以图方式表示程序的逐步执行,强调决策可视化过程和整个程序的控制流。
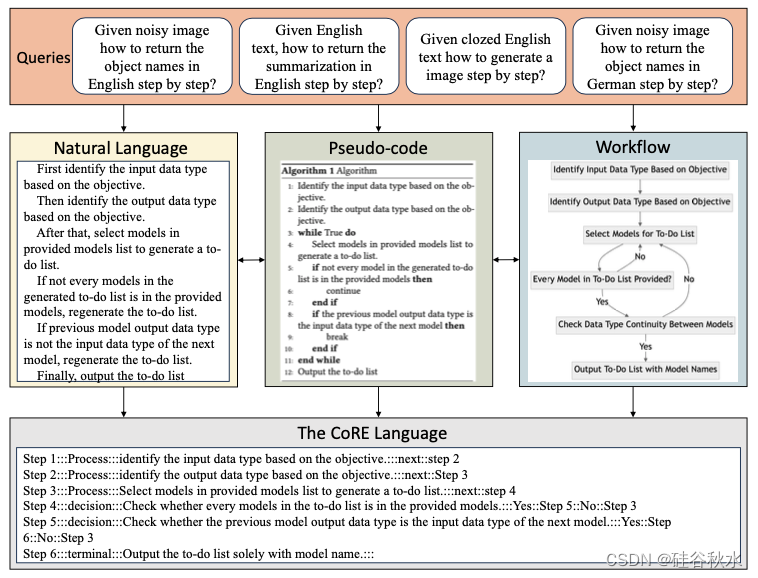
在设计LLM 为解释器的自然语言编程系统时,面临几个重大挑战。首先,如何使用自然语言指令表示程序的逻辑。为了解决这个问题,设计一套编程语法来逻辑地构造自然语言指令,并将自然语言编程、伪代码编程和流编程统一在同一个表示中。其次,鉴于程序由逐步指令组成,确保每个步骤都按照其相应的指令执行至关重要。为了确保每一步都精确执行自然语言指令,设计两个额外的组件:一个用于从内存中检索信息,另一个用于调用外部工具。考虑到 LLM 对输入tokens数量(上下文窗口大小)的限制,将所有运行时信息包含在输入提示中是不切实际的。为了解决这个问题,将大量中间结果存储在临时内存中,并在后续步骤中根据需要检索相关信息 [47, 33, 26, 3]。此外,虽然 LLM 擅长处理文本信息,但它们往往不擅长处理需要域特定知识或最新信息的任务 [14]。为了缓解这些限制,让 LLM 利用外部工具来解决问题 [13, 41, 29, 1]。最后,在执行自然语言程序时,错误地确定下一步可能会导致不同的最终结果。通过要求 LLM 解释器评估当前结果以确定最合适的后续步骤来解决这个问题。CoRE 的整体执行流程如图所示。

CoRE语言语法
为了组织自然语言指令,为每个步骤定义基本结构表示,它由四个部分组成。
• 步骤名称:程序中的每个步骤都由步骤名称唯一标识。此标识符类似于传统编程语言中的函数标识符,它有助于在程序结构内导航和引用,确保可以明确地寻址和访问程序中的每个操作。
• 步骤类型:步骤类型对每个步骤中执行的操作的性质进行分类,类似于传统编程中的控制结构。定义三种主要步骤类型:
– 过程:类似于传统编程中的程序语句,此步骤类型执行特定操作并转换到下一个指定步骤。
– 决策:对应于条件语句(例如“if-else”),此步骤涉及根据评估条件分支程序流,从而导致多条潜路径。
– 终端:类似于“结束”或“返回”语句,此步骤标志着程序的结束,表明不再执行其他步骤。
• 步骤指令:步骤指令阐明了要在步骤中执行的任务。此组件不可或缺,因为它提供执行的指令和内容,与传统编程语言中的语句块相似。通过用自然语言演示操作,NLPg 降低了编程门槛,使非专业程序员更容易理解。
• 步骤连接:步骤连接定义从一个步骤到另一个步骤的进展,建立程序执行流。在进程步中,指定单个后续步骤。在决策步中,根据条件划定多条路径。根据定义,终端步不会导致任何未来的步,表示程序执行结束。
对于程序中的每步,上述四个组件都用“:::”分隔(如图的 CoRE 语言所示)。也可以使用其他特殊tokens来分隔不同的组件。
在编程语言中,编程中有三种基本的控制结构 [8, 40]:序列、选择和迭代。这三个基本结构可以在 CoRE 语言中轻松设计。
• 序列:编程中的序列是按线性顺序执行语句,每个语句都指向下一个语句。在 CoRE 框架中,此结构通过设置“步骤连接”指向后续步骤。每个步骤都在过程类步骤下运行,直到该序列结束。
• 选择:编程语言中的选择有助于条件分支,允许程序根据特定条件执行不同的步骤序列。这是使用决策类步骤实现的,其中“步骤连接”部分明确概述多条潜路径。每个分支都由“步骤连接”部分中规定的条件定义,根据条件将程序流程引导到各个步骤。
• 迭代:迭代涉及重复一组操作,直到满足某个条件,类似于传统编程中的循环。在 CoRE 框架中,利用决策类的步骤来评估循环条件是否已得到满足。在一个循环周期结束时,“步骤连接”配置为指向上一个决策步,从而实现循环的继续。
LLM作为解释器
如图所示是CoRE LLM解释器系统的纵览。更具体地说,系统分四个程序执行单个步骤。首先,解释器确定执行当前步所需的有用信息。然后,解释器将整合所有相关信息以构造提示。根据生成的提示,解释器将生成响应,并可能利用工具来执行当前步骤。最后,在执行完当前步骤后,解释器将根据步骤类和执行结果确定下一步。
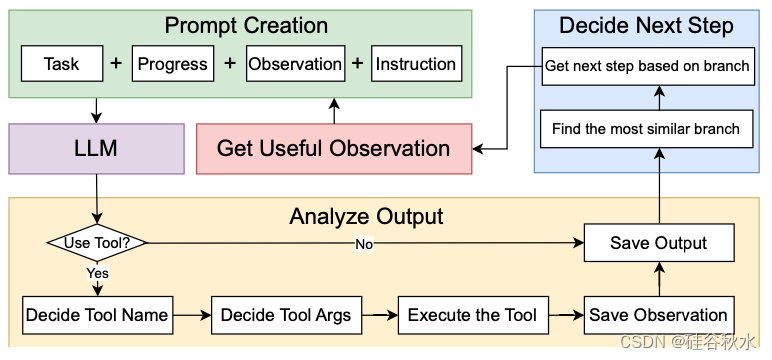
此初始程序至关重要,因为它为当前步的整个执行过程奠定了基础。如图显示了一个例子。系统的内存充当与程序相关所有先前观察的存储库,其中观察代表工具执行的结果,例如搜索结果。在此阶段,解释器扫描内存以识别与当前指令相关的记录。这种选择性检索可确保解释器的决策基于准确且与上下文相关的数据,这对于程序的成功执行至关重要。

构建提示本质上是将信息综合成一个全面而连贯的查询,以便 LLM 能够理解并有效响应。这涉及将多种信息组合成一个单一的结构化提示,指导 LLM 生成最合适且与上下文相关的响应。在 CoRE 系统中,解释器构建一个包含四个元素的详细提示:
任务描述:定义整个程序的查询,作为指导系统操作的主要输入。
当前进度:总结先前的步骤,包括已完成或已决定的内容,帮助保持叙述流畅。
观察:此部分可能不包含在每一步中。当解释器从内存中检索相关信息时,会被合并进来。
当前指令:以自然语言指定要采取的操作,指导解释器如何进行当前步。
虽然 LLM 可以生成直接响应,但复杂的任务可能需要超出其即时范围的能力。在必要时结合专用工具可以扩展 LLM 的功能,使系统能够有效地处理更广泛的任务。如图显示了执行过程的演示示例。在 CoRE 系统中,解释器将根据 LLM 的初始响应和手头任务的要求来决定是否使用专用工具,这确保了系统保持高度的功能性和多功能性,积极解决问题,而不仅仅是处理当前步骤的语言提示。具体而言,如果需要使用工具,系统将选择合适的工具,为其配置必要的参数,执行它,并将输出集成到正在进行的流程中。

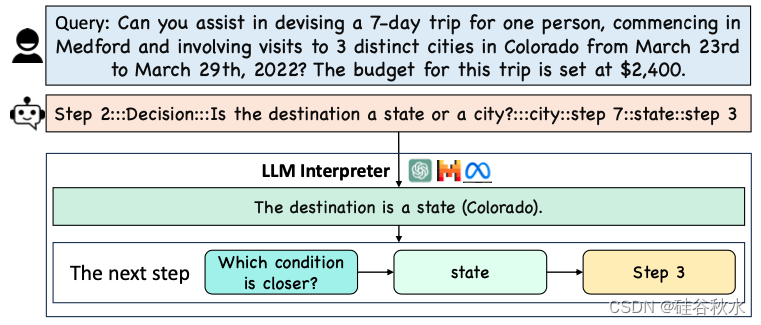
确定程序中合适的下一步至关重要,尤其是在多分支场景中,不同的结果可能导致不同的后续操作。如图显示一个例子。在 CoRE 语言解释器中,决策步表示具有相应条件的多个分支。解释器使用 LLM 来决定提示是否满足自然语言描述的分支条件以及下一步要采取什么步骤。这种自适应方法允许系统有效地浏览决策点,确保逻辑地朝着程序的目标前进。
以下为实验细节:
主干LLM
在闭源和开源 LLM 上进行实验:
• GPT-4 [36](闭源)是 OpenAI 的生成式预训练transformer。这项工作使用 GPT-4-1106 预览版。
• Mixtral-8x7B [20](开源)是一个预训练的生成式稀疏混合专家,具有 467 亿个参数。
LLM 的规划模式
采用以下基于 LLM 的智体规划模式:
• 零样本学习 (Zero) 将查询直接输入到 LLM。
• 思维链 (CoT) [48] 诱导 LLM 生成一个连贯的语言序列,作为连接输入查询和输出答案的意义的中间步骤。
• 小样本学习 (Few) 在提示中呈现一组高质量的演示,每个演示都包含目标任务的输入和期望输出。
• CoRE 是自然语言编程方法,以 LLM 为解释器。
对基准数据集 OpenAGI [13] 进行实验。OpenAGI 基准任务根据其输出类型和真实标签类型进行分类(任务 1、2 和 3)。然后,根据不同的任务类型,采用不同的指标来衡量性能:CLIP 分数 [18] 用于评估文本和图像之间的相似性,用于文本-到-图像任务;BERT 分数 [54] 用于评估使用 BERT 的文本生成,适用于数据标签和预期输出都是文本的情况;ViT 分数 [49] 衡量图像标签和图像输出之间的相似性。
实施细节
框架和所有基线均由开源库 PyTorch 实现。遵循 OpenAGI 平台 [13] 的实现设置,进行零样本和小样本学习。用 DSPy 框架 [23, 24] 将 CoT 策略应用于 OpenAGI 平台。还在 OpenAGI 平台上尝试思维程序(Program-of-Thought)[5] 和 ReAct [53] 策略。然而,ReAct 策略需要文本观察,这不适合OpenAGI 任务,因为一些观察是图像格式,而 Program-of-Thought 无法生成可执行代码。因此,没有将它们作为基线。
实验分析
OpenAGI 基准上的实验结果如表所示。每一行代表一种任务类型,每一列代表一个 LLM 解释器的规划模式,每四列是同一个 LLM 解释器的结果。从结果中可以看到,CoRE 规划模式在 Mixtral 和 GPT-4 作为解释器下的平均性能优于任何基线。

使用 Mixtral 作为解释器时,CoRE 在每一类任务下的表现都优于 零样本 和 CoT,在 任务 2 和平均分数上优于 少样本学习,在 任务 3 上较差,在 任务 1 上略差。使用 GPT-4 作为解释器时,CoT、少样本在 任务 1 和 任务 3 上表现相近,而在 任务 2 和平均分数上,CoRE 仍然是最好的。可能值得注意的是,将 CoRE 与 少样本 学习进行比较是不公平的,因为没有在提示中直接提供输出格式和输出示例。然而,即使不使用这样的示例,CoRE 规划策略平均而言仍然优于少样本策略。即使对于同一个 CoRE 程序,使用不同的 LLM 作为解释器时系统的表现可能会有所不同,这意味着自然语言编程的性能取决于 LLM 解释器的自然语言理解能力。















 1337
1337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









