









24年2月GeorgiaTech的论文“Poke ́LLMon: A Human-Parity Agent for Poke‘mon Battles with Large Language Models”。
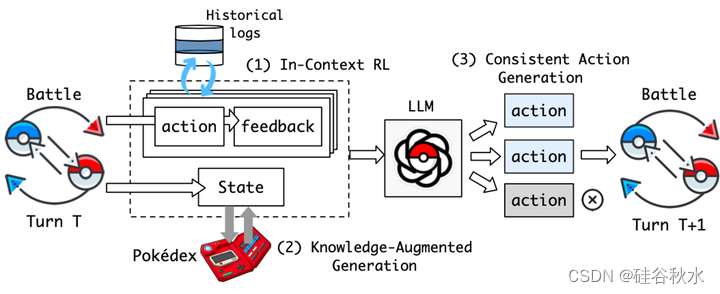
Poke‘LLMon是一个在战术战斗游戏中实现人类对等性能的LLM智体,如Pokémon战斗中所示。Poke‘LLMon包含三个关键策略:(i)在上下文中进行强化学习,即时利用来自战斗的基于文本反馈,迭代地完善策略;(ii)知识增强型生成(KAG),获取外部知识抵消幻觉并使智体能够及时正确地采取行动;(iii)当智体面对强大的对手并想躲避战斗时,采取一致的行动缓解恐慌切换现象。在线对抗人类展示了Poke‘LLMon类人战斗策略和适时决策,在Ladder比赛中获得49%胜率,在邀请战斗中获得56%胜率。实现:https://github.com/git-disl/PokeLLMon。
生成人工智能和LLM在NLP任务上取得了前所未有的成功。即将取得的进展之一将是探索LLM如何在从文本到行动的扩展生成空间的物理世界中自主行动,这代表了追求通用人工智能的关键范式。游戏是开发LLM嵌入智体的合适测试平台,以类人行为的方式与虚拟环境交互。例如,Generative Agents进行了一项社会实验,LLM在类似“The Sims”的沙盒中扮演各种角色,在沙盒中,Agent表现出与人类相似的行为和社交互动。在Minecraft中,决策智体旨在探索世界,并开发解决任务和制作工具的新技能。
与现有游戏相比,战术战斗游戏更适合作为LLM游戏能力的基准,因为胜率可以直接测量,并且总是可以找到像AI或人类玩家这样的一致对手。 Pokémon战斗是在著名的Pokémon游戏中评估训练者战斗能力的一种机制,作为LLM首次尝试玩战术战斗游戏,它提供了几个独特的优势:
(1) 状态和动作空间是离散的,可以无损地翻译成文本。如图是Pokémon战斗的一个示例:在每一回合,玩家都被要求生成一个动作来执行,给定双方Pokémon的当前状态。动作空间由四个动作和五个可能切换的Pokémon组成;
(2) 回合制消除了密集游戏的需求,减轻LLM推理时间成本的压力,使性能仅取决于LLM的推理能力;
(3) 尽管机制看似简单,但Pokémon之战具有战略性和复杂性:一名经验丰富的玩家会考虑各种因素,包括场内外所有Pokémon的种类/类型/能力/统计数据/物品/移动。
在一场随机的战斗中,每个Pokémon都是从不同特征的大候选池(1000多个)中随机选择的,玩家既要求Pokémon的知识,也要求具备推理能力。
LLM智体在游戏中的应用:
通信游戏:交际游戏围绕玩家之间的交流、演绎和欺骗。LLM在棋盘游戏中表现出战略行为,如狼人杀、 Avalane、第二次世界大战(World War II)和外交(Diplomat)。
开放式游戏:开放式游戏允许玩家自由探索游戏世界并与他人互动。Generative Agent展示了LLM智体模仿类人模式的行为和社会互动。MineCraft中Voyager采用课程机制探索世界,并生成和执行解决代码。DEPS提出了一种“描述、解释、规划和选择”的方法来完成70多项任务。基于规划的框架,如AutoGPT和MetaGPT也可以用于勘探任务。
战术战斗游戏:LLM被用来与内置的AI对抗《星际争霸II》,后者具有基于文本的界面和摘要链方法。相比之下,POKÉLLMON有几个优点:(1)将POKÉmon战斗状态翻译成文本是无损的;(2)考虑到LLM的推理时间成本,基于回合的格式消除了实时压力;(3)与守纪的人类选手对抗将难度提升到了一个新的高度。
关于Pokémon战斗的一些细节。
战斗规则:在一对一的随机战斗中,两名战斗者对决,每名战斗者有六个随机选择的Pokémon。最初,每个战斗者都会向战场上发送一个Pokémon,并保留其他Pokémon以备将来切换。目标是让对手的所有Pokémon都晕倒(通过将其生命值降至零),同时确保至少有一个自己的Pokémon保持稳定。
战斗基于回合:在每个回合开始时,两名玩家都选择一个动作来执行。动作分为两类:(1)采取行动,或(2)切换到另一个Pokémon。战斗引擎执行动作并更新下一步的战斗状态。如果一个Pokémon在转弯后晕倒,而战斗者有其他Pokémon没有晕倒,战斗引擎会强制切换,这不计入玩家下一步的行动。在强制切换后,玩家仍然可以选择一次移动或进行另一次切换。
战斗引擎:该环境与名为Poḱemon决战的战斗引擎服务器交互,该服务器为人类玩家提供基于web的GUI,以及用于以定义格式交互消息的web API。
战斗环境:基于( https://github.com/hsahovic/poke-env)实现一个战斗环境,支持LLM自主玩Pokémon战斗。如图展示整个框架如何工作。在一个回合开始时,环境从服务器获得一条动作-请求消息,包括上一回合的执行结果。环境首先解析消息并更新本地状态变量,然后将状态变量转换为文本。LLM将这些作为输入,并为下一步生成动作。然后发送到战斗服务器,并与对手玩家选择的动作一起执行。
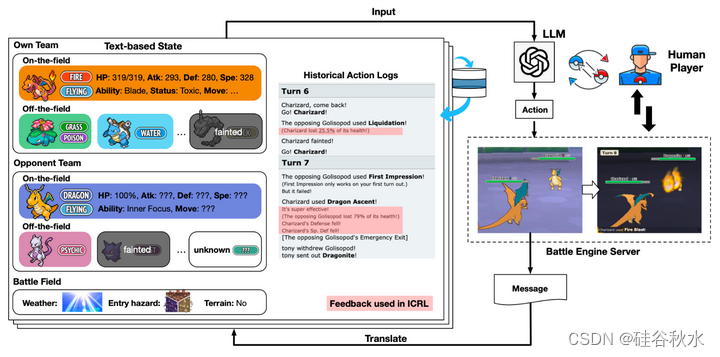
环境的文本描述主要由四个部分组成:(1)自己的团队信息,包括Pokémon在场内外的属性;(2) 对方队信息,包括对方Pokémon在场内/外的属性(有些未知);(3) 战场信息,如天气、进入的危险和地形;(4) 历史的回合日志信息,包括双方Pokémon之前的动作,存储在日志队列中。
LLM将转换后的状态作为输入,并输出下一步的动作。该动作被发送到服务器,并与人类玩家选择的动作一起执行。
如图所示POKÉLLMON的总体框架。在每一个回合中,POKÉLLMON都会用以前的动作和相应的基于文本的反馈来迭代地完善策略,并利用外部知识(如类型优势/劣势关系和移动/能力效果)来增强当前的信息状态。给定上述信息作为输入,它独立地生成多个动作,并选择最一致的动作作为执行的最终输出。 POKÉLLMON配备了三种策略:(1)IC-RL,它利用战斗的即时反馈来迭代优化生成;(2) KAG获取外部知识以对抗幻觉并及时正确地采取行动;(3) 一致行动生成,以防止紧急切换问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









