









23年9月来自清华大学的论文“Surrealdriver: Designing generative driver agent simulation framework in urban contexts based on large language model“。
仿真在自动驾驶和智能交通系统的研发中发挥着至关重要的作用。然而,当前的仿真平台在智体行为的真实性和多样性方面表现出局限性,这阻碍了仿真结果向现实世界的传递。本文提出一个基于大语言模型(LLM)的生成式驾驶智体仿真框架,该框架能够感知复杂的交通场景并提供真实的驾驶操作。值得注意的是,在采访了24名驾驶员之后,并将他们对驾驶行为的详细描述作为思维链提示,作者开发了一个“教练智体”模块,该模块可以评估和帮助驾驶智体积累驾驶经验和发展类人驾驶风格。通过实际仿真实验和用户实验,验证了该框架在生成可靠驾驶程智体方面的可行性,并分析了各个模块的作用。结果表明,全框架的碰撞率降低了81.04%,仿人性提高了50%。
如图所示:Surrealdriver是一个LLM支持的驾驶员智体模拟框架,可以生成类似人类的驾驶行为:理解情况、推理和采取行动。它还学习专业驾驶员的驾驶建议,积累自己的驾驶经验(指南),并不断提高驾驶技能。

下图是Surrealdriver的框架图:Carla仿真器是开源的自动驾驶仿真平台,其建立了基于基本驾驶流水线的记忆和安全机制;DriverAgent是驾驶智体,其作为Surrealdriver框架的核心组件;CoachAgent是教练智体,其评估和帮助驾驶智体积累驾驶经验和发展类人驾驶风格。
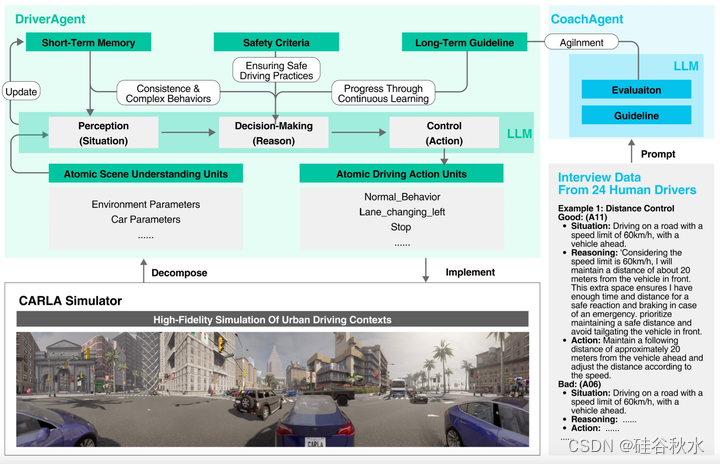
如图是DriverAgent的细节:其驾驶流水线包括感知、决策和控制。在感知部分,DriverAgent从CARLA模拟器接收有关车辆自身状态和周围环境的信息。将这些信息分解为原子模块,并将其作为输入参数提供给DriverAgent,使其能够集成这些数据。这些信息以参数的形式提供给DriverAgent。在智体的系统提示中提供了这些参数含义的具体描述,使其能够理解它们的意义。在接收到这些参数后,DriverAgent根据常识和提供的提示对其进行分析和集成,了解车辆的现状。

一旦感知阶段完成了对情况的理解,DriverAgent将根据这种情况为接下来的步骤做出决定。决策标准包括向其提供的初始要求,以确保安全和高效驾驶。
在决策过程完成后,开始控制阶段。在这个阶段,DriverAgent将生成一个JSON格式的命令,发送到CARLA程序。它将根据当前场景从预定义的一组操作中选择适当的操作。它可以选择的可用操作包括:stop、normal_behavior、maintain_speed、lane_changing_left、lane_changing_right、speed_up、speed_down。这些动作是原子驾驶操作,DriverAgent可以将这些动作组合起来,生成连贯而复杂的机动。
如图所示,DriverAgent将同时输出上述驾驶,包括情景、推理和动作。为了确保驾驶的连续性和复杂性,将存储当前智体在过去几次迭代中的驾驶行为,并不断更新:用最新的替换最旧的,保持一定数量的存储行为。然后,这些行为将再次提供给DriverAgent,成为其感知的一部分。

为了更好地将超现实驾驶员与人类驾驶员相结合,收集了其他真实驾驶员的驾驶行为文本数据作为少量提示。这些数据是评估初始动作质量的标准,也是提高驾驶性能的指南。使用少量提示显著减少了输入、内存和存储消耗,同时增强了驾驶员对良好和不良驾驶行为的理解。
作者邀请了24名驾驶员(10名专家驾驶员和14名新手驾驶员)参加关于驾驶行为的深入采访。为了深入研究具体的驾驶行为,最初让每个驾驶员执行一项城市道路驾驶任务,涵盖13种驾驶条件,总长度为5.7千米。随后,进行了深入的任务后访谈。所有的观点都被记录下来,每次采访大约持续1.5到2个小时。研究人员团队进行了数据清理和开放编码,从这些采访中选择了潜在的提示材料。然后将这些材料转换为coachagent的提示模板。
在清理了访谈数据后,可以看到专业司机和新手司机之间的行为差异。例如,发现专业驾驶员有控制以下距离的具体方法和标准,他们会根据实时条件进行调整:
“如果速度限制是,比如说40,那么可能会保持大约10米的距离,这超过了两辆车的长度。以每小时60英里的速度,如果道路不太拥挤,会再延长,也许在20米左右。在60英里/小时的速度下,可能会保持大约20米的距离,因为需要留出足够的反应时间和制动距离。不会用后挡板挡住前面的车;这种情况从未发生过。驾驶时,需要保持高度专注和警惕;必须做好准备,以防前车突然刹车。如果离得太近,不会及时做出反应。“
为了提高SurrealDriver’s的表现,可以采用专业驾驶员的做法,使智体能够根据路况评估跟车距离。在CoachAgent的提示中,介绍了“评估标准和指南”,并提供了三个专家和新手司机在不同场景下进行不同操作的实例。将专业驾驶者的驾驶行为作为“好榜样”,将新手驾驶者的行为作为“坏榜样”。如图是CoachAgent教练智体和人类对齐的解释图。
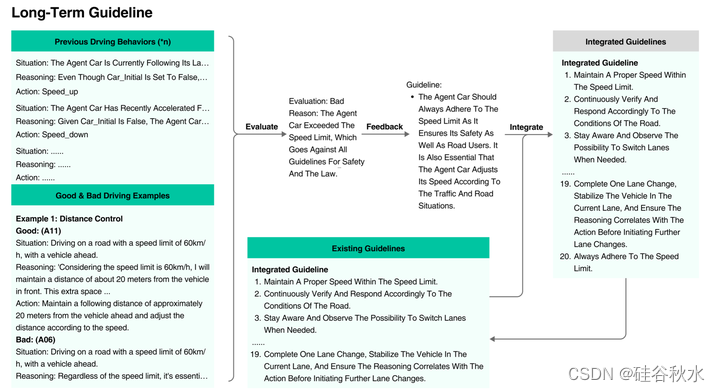
如图所示,在设计CoachAgent教练智体示例时,采用了一种三维方法:情境、推理和动作。情境提供了驾驶员操作过程中的具体路况,对于每个对比案例,都设置了相同的路况,参考了真实驾驶员在面试中面临的路况。推理是根据驾驶员访谈的内容设计的,去掉了不相关的信息,使例子简洁高效地展示了人类的思维,引导智体学习人类的思维模式。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









