










23年10月来自香港理工的论文“Making Multimodal Generation Easier: When Diffusion Models Meet LLMs“。
EasyGen,旨在利用扩散模型和大语言模型 (LLM) 功能来增强多模式理解和生成。 现有的多模态模型主要依赖于 CLIP 或 ImageBind 等编码器,并且需要大量的训练数据来弥合模态之间的差距,而 EasyGen 与主要依赖于 CLIP 或 ImageBind 等编码器的现有多模态模型不同,EasyGen 建立在名为 BiDiffuser 的双向条件扩散模型之上,该模型可促进模态之间更有效的交互。 EasyGen 通过简单的投影层集成 BiDiffuser 和 LLM 来处理图像-到-文本的生成。 与大多数仅限于生成文本响应的现有多模态模型不同,EasyGen 还可以利用 LLM 创建文本描述促进文本-到-图像的生成,BiDiffuser 可以解释文本描述生成适当的视觉响应。
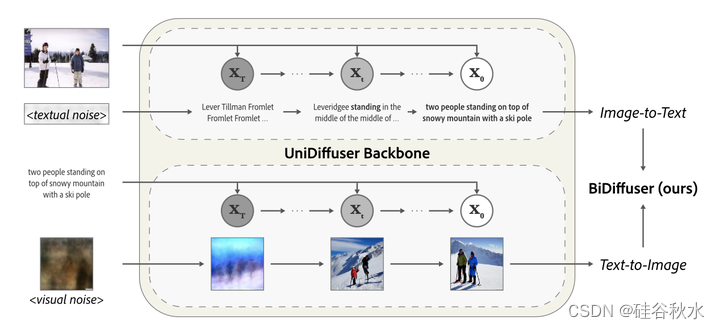
具有多种技能的扩散模型,例如 Versatile Diffusion (Xu 2023) 和 UniDiffuser (Bao 2023b),在准确捕获多模态分布方面表现出了卓越的能力。 尤其是 UniDiffuser,在适应多模态交互方面显示出巨大的潜力。 它将图像和文本视为用于扩散计算的连续token流,使其非常适合LLM的文本表示,其通常结构化为序列模式。 然而,由于 UniDiffuser 的目标是将所有条件分布(包括以噪声输入为条件的条件分布)拟合到一个模型中,因此它在特定任务(例如基于无噪声输入的条件生成)上效果较差。 为了解决这个限制,对 UniDiffuser 进行微调,特别关注目标如图像-到-文本和文本-到-图像的两个任务。 微调的模型(称为 BiDiffuser)构成了 EasyGen 用于文本和图像生成的核心组件。
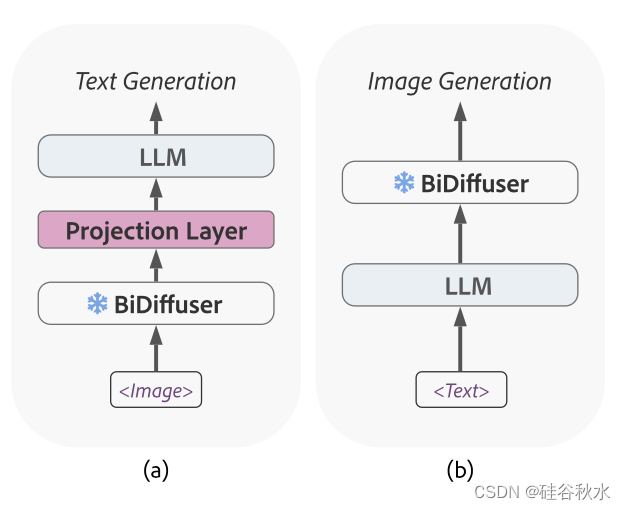
BiDiffuser (Bidirectional Conditional Diffusion Model )能够将图像数据转换为文本格式,在语义理解和推理中这个处理简化了其嵌入空间与 LLM 嵌入空间同步的过程。 如图所示,用一个简单的投影层桥接 BiDiffuser 和 LLM,可以用少量数据有效地训练该投影层,执行图像字幕和视觉问答等图像-到-文本任务。 或者,LLM 可用于生成源自文本上下文(如对话)的详细描述和提示,这可以帮助 BiDiffuser 生成准确的视觉响应,如图所示。
如图所示,训练目标需要根据输入图像预测文本,反之亦然,其中模型的输入条件是无噪声的。 本文采用无分类器引导。BiDiffuser的训练过程以图像-到-文本和文本-到-图像两个任务的联合目标微调UniDiffuser (Bao2023b) 。
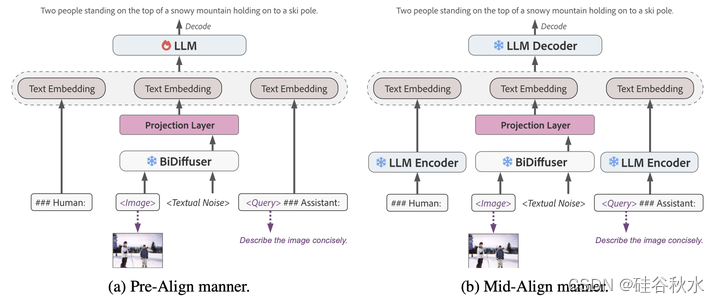
通过一个简单的投影层连接 BiDiffuser 和 LLM,该投影层将扩散模型输出的文本嵌入映射到 LLM 的嵌入空间。 如图所示,对齐可以在 LLM 之前进行(称为预对齐方式),也可以在其编码器和解码器组件之间进行(称为中对齐方式)。
预对齐(pre-align)方式如图a所示,投影层放置在LLM之前,将BiDiffuser的输出(图像表示)映射到LLM的文本嵌入空间。 然后,输入图像的文本嵌入与文本指令的嵌入连接起来,并馈送到 LLM 进行解码。 为了使 BiDiffuser 的文本空间与 LLM 的文本空间同步,基于输入图像,通过计算自回归损失用图像为基础的文本生成(ITG,image-grounded text generation)目标驱动模型生成文本。
中对齐(mid-align)方式如图b所示,投影层放置在LLM的编码器和解码器之间,旨在将BiDiffuser的输出映射到LLM编码器编码文本的嵌入空间。 特别是,一旦被投影层映射得到BiDiffuser的输出,就应该与LLM 编码器编码的图像字幕对齐。 因此,为了准确地学习图像和文本表示之间的对齐,除了ITG损失之外还采用了图像-文本距离最小化(ITDM,image-text distance minimization)损失。
这样,模型参数仅包含投影层的参数。 将 BiDiffuser 与 LLM 结合后,EasyGen 获得了零样本图像-到-文本生成的能力,其中包括图像字幕和 VQA 等任务。
在将 BiDiffuser 与 LLM 对齐之前,对 LLM 进行指令调优,使其具备理解多模态任务的能力。
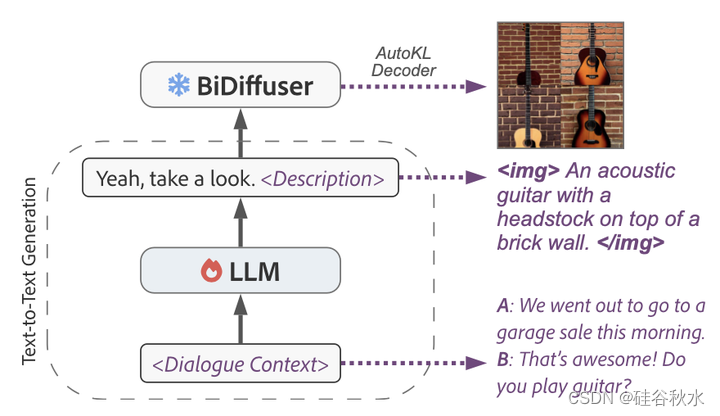
为了解决 PhotoChat (Zang 2021) 等多模态响应生成任务,采用Divter (Sun 2021) 中使用的方法(请注意,Divter 无法编码和处理视觉图像)。 首先对 LLM 进行微调,根据对话上下文生成详细的图像说明。 然后采用BiDiffuser 创建带有生成字幕的相应图像。
如图所示是EasyGen实现文本-到-图像生成。 (下图)LLM 生成图像的响应和描述。 (上图)BiDiffuser 将描述作为输入并生成图像。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









