









23年10月来自MIT、上海交大、清华、华盛顿大学和CMU等高校的论文“GenSim: Generating Robotic Simulation Tasks Via Large Language Models“。
收集大量现实世界的交互数据来训练一般的机器人策略,通常成本高昂,因此刺激了模拟数据的使用。 然而,现有的数据生成方法通常关注场景级多样性(例如,目标实例和姿势)而不是任务级多样性,原因是提出和验证新任务需要人力开销。 这使得模拟数据训练的策略难以展示重要的任务级泛化能力。
本文通过大型语言模型(LLM)的落地和编码能力,自动生成丰富的模拟环境和专家演示。 该方法称为 GENSIM,有两种模式:1)目标导向生成,其中向 LLM 提供目标任务,LLM 提出任务课程来解决目标任务;2)探索性生成,其中 LLM 从先前的任务中引导并迭代地提出有助于解决更复杂任务的新任务。
作者用 GPT4 将现有基准扩展十倍,达到 100 多个任务,并在这些任务上进行监督微调并评估多个 LLM,包括针对机器人模拟任务的微调GPT 和代码生成的Code Llama。 此外,观察到,LLM生成的模拟程序,在用于多任务策略训练时,可以显着增强任务级泛化能力。 进一步发现,通过最小的模拟-到-现实的适应工作,在GPT4生成的模拟任务上预训练的多任务策略,能够迁移到现实世界中未见的长期任务,而且性能比基线高出 25%。
如图所示:GenSim 这样一个LLM框架,用于扩大机器人策略训练的模拟任务多样性。 作者研究生成机器人模拟任务代码的目标导向模式(顶部提示)和探索模式(底部提示)。 生成的任务代码缓存在任务库中,可用于策略训练,实现更好的任务级泛化和模拟-到-真实的适应能力。
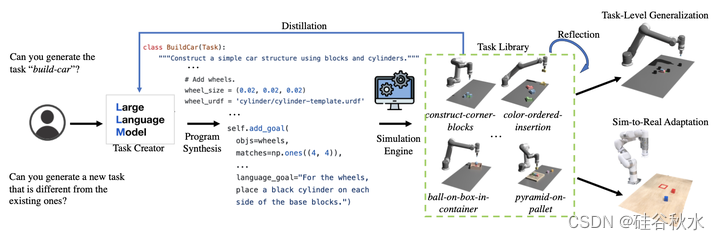
任务创建器的目标是提出新任务描述和相应的代码实现,可以进一步细分为场景生成和演示生成。 特别是,用 Ravens 基准(Zeng 2021;Shridhar 2022),其侧重于运动原语,例如推动和拾放,可以通过每个时间步的两个末端执行器的姿势进行参数化 。 如图所示,模拟环境代码中的重置功能,有效地初始化资产及其属性和姿势、以及每步参数化动作的空间和语言目标。 在探索性任务生成的设置中,流水线会被提示去生成与现有任务不同的新任务。 在目标导向的设置中,流水线旨在填充一个指定任务名称的任务描述和实现。 探索性方法需要创造力和推理能力来提出新任务,而目标导向方法则侧重于将模拟编码作为特定任务。
如图所示:自动模拟任务生成流水线(左上)生成一个任务代码,用于生成模仿学习的场景、模拟和专家演示。 除了LLM程序综合任务中常见的、基于执行的反馈之外,LLM批评家(critics)和任务库还提供任务质量反馈。 最后,策略训练和人工检查提供最终的检查。
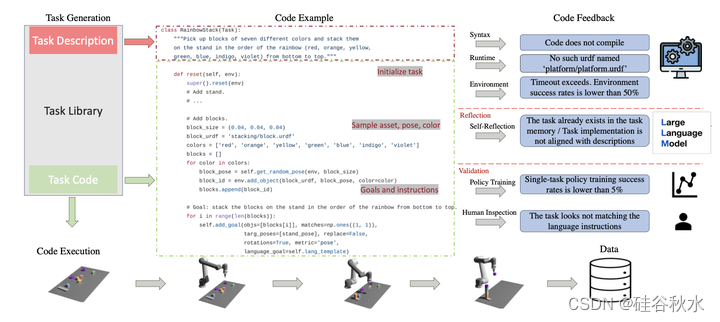
在这两种设置中,语言链首先生成任务描述,然后生成相关的实现。 任务描述包括任务名称、资产和任务摘要。 在流水线中采用少样本提示来生成代码。 系统会提示LLM从任务库中的现有任务选择参考任务和代码。 这个过程至关重要的是,LLM准确地知道如何实现一个任务类(例如首先采样资产URDF和构建场景,然后添加空间目标和语言目标)。 与其他LLM编码任务相比,机器人模拟中有多种反馈形式,包括执行流水线、模拟器、策略训练和人工。
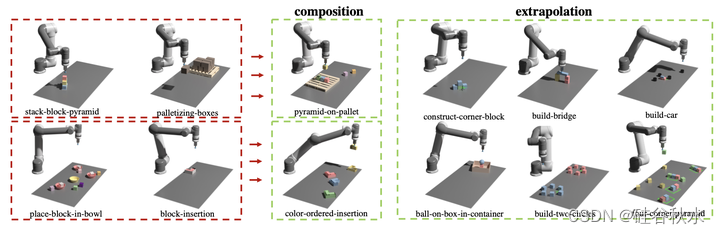
在 GenSim 框架中,用任务库的外部存储器缓存任务创建器生成的任务,提出更好的新任务并训练多任务策略。 任务库是根据人工设计的基准测试任务初始化的。 它为任务创建器提供在描述生成阶段作为条件的旧任务描述列表以及在代码生成阶段的旧代码列表。 然后,任务创建器会被提示从任务库中选择参考任务作为编写新任务的示例。 在任务实现完成并成功通过生成演示的所有测试后,会提示LLM从新任务和任务库进行反映,形成是否应将新生成的任务添加到库的综合决策。 如图所示,GenSim 在模拟任务的代码生成中演示了有趣的任务级组合和外推行为,这些行为通过演示被提炼为策略学习。
生成任务后,生成演示数据并训练操作策略。 用类似的双流传输网络(transporter network)架构(Shridhar 2022)通过可观性(affordance)预测参数化策略。 以语言为条件的行为克隆过程,其代码生成可以被视为从LLM到低级控制和机器人策略可观性的蒸馏过程。
如图所示,将程序视为任务和相关演示数据的有效表示,就可以定义任务中的嵌入空间,其距离度量对来自感知的各种因素(例如目标姿势和形状)更加稳健,并且比语言指令更有信息量。任务代码嵌入可用于在任务库中创建嵌入空间,可视化为 T-SNE图(Van der Maaten & Hinton,2008),可用于聚类任务和策略训练。 例如,紫色代表涉及绳索的任务,蓝色代表涉及建筑结构的任务。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









