









24年4月来自上海交大、UIUC和CMU的论文“Emerging Platforms Meet Emerging LLMs: A Year-Long Journey of Top-Down Development”。
在不同的计算平台上部署机器学习 (ML) 对于加速和扩大其应用至关重要。然而,由于模型的快速发展,尤其是最近的大语言模型 (LLM) 以及新计算平台的出现,它带来了重大的软件工程挑战。当前的 ML 框架主要针对 CPU 和 CUDA 平台设计,在支持 Metal、Vulkan 和 WebGPU 等新平台方面存在很大差距。
虽然传统的自下而上(bottom-up)的开发流程无法及时弥补差距,TAPML的引入,一种自上而下(top-down)的方法和工具,可简化 ML 系统在不同平台上的部署,并针对开发人员的工作效率进行优化。与涉及大量手动测试和调试的传统自下而上方法不同,TAPML 通过测试设计实现单元测试自动化,并采用基于迁徙(mitigation)的策略,逐步将模型计算从成熟的源平台卸载到新目标平台。利用现实输入和远程连接逐步卸载目标,TAPML 加速验证并最大限度地减少调试范围,从而显著优化开发工作。
TAPML 的开发和应用经过一年的实际努力,成功部署重要的新模型和平台。通过在 5 个新平台上 17 种不同架构中部署 82 个新模型,展示了 TAPML ,在提高开发人员生产力的同时,确保模型可靠性和效率的有效性。此外,由于将高级机器学习数学映射到低级机器可执行文件存在巨大差距,因此巨大努力是在来开发机器学习优化器 [4]–[6],高效运行机器学习模型。这些框架在给定训练模型后,提供高效的本机内核(例如 CUDA/C 函数)来计算模型的算子/子图,部署在推理优化的平台上。这些内核函数可以用本机编程语言(例如 CUDA)手工完成,也可以由编译器从中间表示(IR) [7]–[10] 生成。然而,现有的机器学习框架主要针对 CPU 和 CUDA 平台实施和优化,为其他新平台留下了空白。
随着大语言模型 (LLM) 的最新进展和兴趣,各种架构的强大新模型不断出现。与此同时,最近提出一系列新计算平台,解锁在没有 NVIDIA GPU 的环境中运行 ML 模型的可能性,例如 Apple Silicon 的 Metal [11]、Web 浏览器的 WebGPU [12] 等。在本机和服务器上启用更广泛的新平台来实现可持续性至关重要。新的本机 ML 为用户隐私提供了根本保障,并解决了服务器平台的成本和网络要求。同时,为 GPU 客户提供扩展的服务器级计算选项可在性能、成本效益、灵活性等方面提供更大的多样性。
设计一个机器学习框架很难,而设计一个机器学习框架在新平台上支持新机器学习模型则是一个更具挑战性的软件工程问题。直接但不可避免的挑战是从目标平台学习新的编程原语(primitive)。此外,软件开发人员可能要花费 35-50% 的时间来测试和调试软件 [13]。测试和调试面临两个主要挑战。首先,需要足够且多样化的测试用例来测试各个算子的实现,但开发人员通常必须手动编写这些测试,整个过程繁琐而费力。其次,新平台的工具支持和生态系统极其有限(例如,没有调试器),导致痛苦的调试和分析体验。
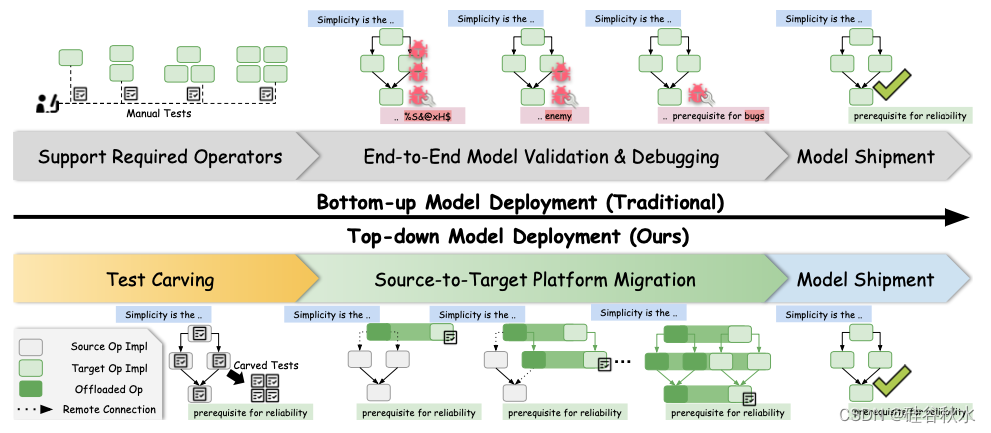
自下而上的ML部署。现有的机器学习框架通常采用自下而上的开发方式,但不幸的是,这种方式在支持新机器学习系统时已不再满足生产力要求。自下而上地支持新模型有两个步骤:(i) 开发人员实现以前不支持的算子;(ii) 将已实现的算子组合成一个整体模型,进行端到端测试和调试。具体来说,在第一步中,开发人员分析要支持的算子,实现它们,并手动编写测试进行验证。由于手动编写的测试通常使用合成输入,其分布可能与从实际输入继承的分布有很大不同,因此算子验证是不够的。端到端模型测试在展示精度错误方面仍然有效;但是,模型测试检测的错误很难调试,因为症状只是结果一致性方面的成功或失败信号,缺少推断错误诱发组件的细节。因此,对大模型空间进行故障排除会带来具有挑战性的调试体验,并会显著减慢开发过程。
自上而下的 ML 部署。TAPML是一种自上而下的方法和工具,用于支持新ML 系统,并针对开发人员的工作效率进行了优化。在高层次上,TAPML 将部署视为迁徙任务,逐步将模型实现从成熟的源平台(例如 CUDA)卸载到新目标平台(例如 WebGPU)。具体来说,TAPML 采取以下步骤为新平台部署 ML 模型。首先,TAPML 通过测试设计[14] 自动化单元测试的挑选,它会自动跟踪源平台执行的中间计算,作为目标平台实现的测试用例。值得注意的是,在检测期间引导模型的输入是真实的输入(例如,LLM 有意义的句子),这样精度回归就可以关注真实世界的数据分布。接下来,执行逐步目标卸载。首先在源平台上完全实现一个计算图,该计算图可以正确通过所有系统测试。然后,逐渐将计算图中的每个算子从源平台卸载到目标平台,直到目标平台完全运行计算图。对于每个算子,首先用单元测试执行算子验证,然后用目标平台实现替换源平台实现。这样的流程还提供了一种错误隔离机制,其中模型故障必须由新实现在目标平台上的算子引入。因此,开发人员可以快速将错误定位在小范围内,并使用即时的逐算子和逐模型验证反馈进行高效调试。同时,为了服务混合图并执行差异测试 [15],TAPML 构建了一个统一跨平台数据通信和函数调用的通用运行。运行时允许在设备上调用远程函数,并在 Python 中无缝地在源平台和目标平台之间传输其输入和输出,就像运行本地程序一样。最后,当计算图在目标平台上完全实现并通过模型验证时,工作流程结束。
如图是两种ML部署方法的对比:
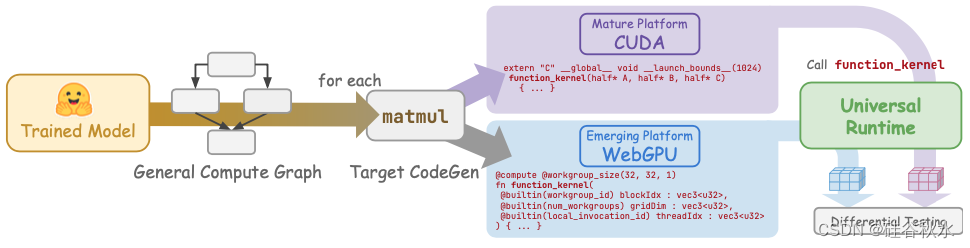
在特定平台上部署模型的目标是使用目标平台的本机程序描述模型的计算。具体而言,如图说明了 TAPML 中的典型部署工作流程。部署流程的输入是训练框架(例如 PyTorch)生成的训练模型。随后,训练的模型由框架转换为内部中间表示 (IR),该表示通常描述模型的语义。通过一系列通用优化,IR 流向目标代码生成阶段,该阶段将计算转换为目标平台的本机程序。例如,现有框架通常将代码生成流水线专门化为 NVIDIA 生态系统中成熟的平台 CUDA,这些计算最终由 CUDA C 函数表示,如图中的紫色框所示。
下表是TapML中成熟和涌现的计算平台,其相应的硬件选择范围从GPU密集型工作站到节能的移动设备:
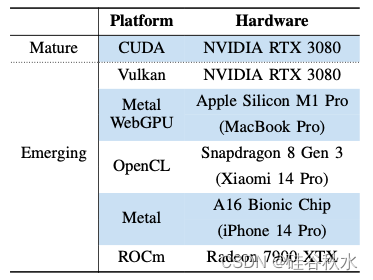
- CUDA [25]:NVIDIA GPU 的并行计算平台和应用程序编程接口模型。
- ROCm [26]:AMD 为 GPU 加速计算开发的开源平台,类似于 NVIDIA 的 CUDA,但适用于 AMD GPU。它为各个领域的高性能并行计算应用程序提供了一套全面的工具和库。
- Metal [11]:Apple 的低级 API,用于优化 iOS 和 MacOS 等 Apple 生态系统上的图形学和计算,提供高性能和高效率。
- WebGPU [12]:一种 Web 标准,在 Web 浏览器上提供跨平台、低级图形学和计算 API 和功能。
- Vulkan [27]:一种跨平台图形学和计算 API,可在各种设备上高效、低开销地访问现代 GPU。
6)OpenCL [28]:一种开放的、免费的标准,用于个人电脑、服务器、移动设备和嵌入式平台中各种处理器跨平台的并行编程。
基于 Apache TVM [6] 来试验 TAPML,这是一个开源 ML 编译器堆栈,对 CPU 和 NVIDIA GPU 平台具有强大的支持。具体来说,在 TVM 之上构建了一个通用 ML 推理引擎,作为 MLC-LLM 项目(https://github.com/mlc-ai/mlc-llm)的一部分,该引擎针对新模型和平台。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









