










24年3月来自martian公司(https://withmartian.com/)、UC Berkeley和UCSD的论文“ROUTERBENCH: A Benchmark for Multi-LLM Routing System”。
随大语言模型 (LLM) 的应用范围不断扩大,对有效服务解决方案的需求也变得越来越关键。尽管 LLM 用途广泛,但没有一种模型能够最佳地解决所有任务和应用,尤其是在平衡性能和成本时。这一限制导致了 LLM 路由系统的开发,该系统结合了各种模型的优势,以克服单个 LLM 的限制。然而,缺乏用于评估 LLM 路评估框架,旨在系统地评估 LLM 路由系统的有效性,以及一个包含来自代表性 LLM 的 405k 多推理结果的综合数据集,以支持路由策略的开发。进一步提出 LLM 路由的理论框架,并通过 ROUTERBENCH 对各种路由方法进行了比较分析,强调了它们在评估框架中的潜力和局限性。这项工作不仅规范化并推动了 LLM 路由系统的开发,还为它们的评估设定了标准,为更易于访问且经济可行的 LLM 部署铺平了道路。
代码和数据在 https://github.com/withmartian/routerbench 。
大语言模型 (LLM) 在解决学术和工业场景中的各种任务方面表现出了卓越的能力 (Bubeck,2023)。这促使研究人员和从业者几乎每天都引入针对通用和专用用例设计的新 LLM。然而,LLM 的激增给 LLM 应用程序构建者带来了挑战,他们需要确定最适合其应用程序的模型。虽然一些专有模型(例如 GPT-4)以其卓越的性能而著称,但由于 API 价格高昂,它们通常会产生高昂的经济成本。
许多先前的研究都侧重于在保持低成本的同时提高单个 LLM 的能力。提示 (Wei et al., 2022)、量化 (Lin et al., 2023; Kim et al., 2023) 和系统优化 (Kwon et al., 2023) 等技术可能会降低单个模型的服务成本,但随着新模型的不断涌现,这些方法可能长期考虑不可行或不可扩展。此外,对于试图通过“路由”处理每个输入的用户来说,不同价格和性能等级 LLM 选择的多样性可能会令人望而生畏。
另一种解决方案旨在通过“路由”为每个输入选择最佳 LLM。(Chen,2023;Shnitzer,2023;Sakota,2023)。与单 LLM 优化相比,路由具有多种优势。首先,它是一个轻量级的过程,将每个 LLM 视为一个输入输出黑匣子,避免了深入研究复杂基础架构细节的需要,从而使其具有灵活性和广泛适用性。其次,路由系统受益于 LLM 的多样性,而单一 LLM 方法可能难以跟上不断扩大的 LLM 格局。最后,虽然单一 LLM 策略通常面临性能和其他因素(例如每个token成本)之间的折衷,但路由系统能够巧妙地平衡一系列用户需求。
路由相关研究的兴起提高了成本效率、增强了性能并扩大了可访问性(Chen,2023;Lee,2023;Lu,2023)。尽管取得了这些进展,但仍然缺乏用于评估路由技术的综合基准。
微调用于改进特定任务的模型,这需要额外的训练和特定领域的数据(Rafailov,2023)。诸如思维链 (CoT)(Wei,2022;Zhou,2023;Wang,2022)和思维树 (ToT)(Yao,2023)之类的提示机制,可以在无需额外微调的情况下提高 LLM 性能。混合专家 (MoE) (Eigen,2014;Shazeer,2017;Fedus,2022;Du,2022;Shen,2023;Si,2023) 是另一项探索模型内路由以有效提高性能的工作,其中包含专门的“专家”并将输入路由到最佳专家。然而,这些单一 LLM 增强功能通常是针对模型和场景的,并且无法从 LLM 数量的激增中受益。
除了单一的 LLM 方法之外,LLM 合成还利用多个 LLM 的集合,将其输出集成为增强的最终结果 (Jiang,2023b)。另一种方法表明,较小模型的战略组合可以匹敌甚至超越较大的模型 (Lu,2024)。然而,这些方法至少需要两个步骤:文本生成和合成,这会增加成本和延迟,从而给在生产中应用这种方法带来挑战。
与 LLM 合成不同,路由可以为特定输入选择合适的模型,而无需对每个候选模型进行推理。路由可分为两类:非预测路由和预测路由。非预测路由策略从 LLM 中检索输出并直接选择一个,而无需模型辅助合成步骤。FrugalGPT(Chen,2023)介绍了此类策略的首次应用,它使用了一个生成判断器来评估来自各个 LLM 对给定查询的响应质量,并按顺序调用 LLM,直到答案达到预定义的质量阈值。几项研究(Madaan,2023;Yue,2023;Lee,2023)也探索了将小规模语言模型与 LLM 集成的系统。另一种方法涉及分层推理框架,将更复杂的查询重新路由到高级模型以获得更好的结果(Wang,2023)。预测路由选择最佳 LLM,而无需评估输出。一条研究路线已经利用监督学习算法实现了路由器(Shnitzer,2023),而其他一些研究则使用基于奖励模型的技术(Hari & Thomson,2023;Lu,2023)。此外,元模型在输入上进行训练,并使用特定于模型的tokens来预测性能得分,代表了另一种确定最合适的 LLM 的方法(Sakota,2023)。简而言之,预测路由器可以在不牺牲延迟的情况下带来显着的成本和性能改进,许多早期的工作都致力于这一领域。目前市面上有很多路由器,但一直缺乏系统的评估基准。
评估路由系统性能的主要挑战在于平衡两个相互冲突的目标:最大化效率和最小化成本。ROUTERBENCH 是一个专门为评估路由器机制的推理成本和性能而设计的综合基准。
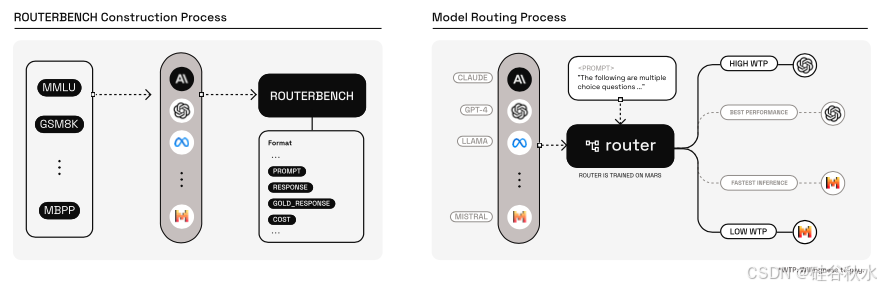
ROUTERBENCH如图所示:左图是ROUTERBENCH 构建过程,将八个数据集与十一个不同的模型集成在一起,以开发 ROUTERBENCH;右图是模型路由过程,展示了根据特定请求通过路由器将提示路由到各个 LLM 的方法,展示了资源的动态分配。
考虑一组模型 L = {LLM1,…,LLMm} 和由示例 xi ∈ {x1, …, x|D|} 组成的数据集 D。对于每个模型 LLMj ,为每个示例 xi 生成输出 oji = LLMj (xi ) 来评估其性能。每个输出 oji 都有两个相关量:生成该输出的成本 c(oji ) 和输出本身的质量或性能 q(oji )。通过此过程,为数据集 D 中的每个模型 LLMm 建立预期成本 cm 和预期质量 qm。
路由器 R 定义为一个函数,接收提示 x 和一组参数 θ,然后从集合 L 中选择最合适的模型 LLMi 来完成提示。
当使用多个路由器时,可以通过线性插值来构造任意的仿射点组合。具体来说,对于成本-质量 (c − q) 平面中的一组点 S,这些仿射组合可以针对位于 S 形成凸包内的任何点 (c, q)。将 Sch ⊆ S 标识为描绘此凸包顶点的点子集。
此外,可以从 Sch 配置一个非递减凸包,确保对于任何两个点 (c1, q1) 和 (c2, q2),其中 c2 ≥ c1,则 q2 ≥ q1。直观地讲,如果 c2 − c1 的额外成本没有带来任何性能提升,那么建议简单地将 (c1, q1) 外推到 c2 的域,这样 (c2, q2) 就可以等于 (c2 , q1 )。
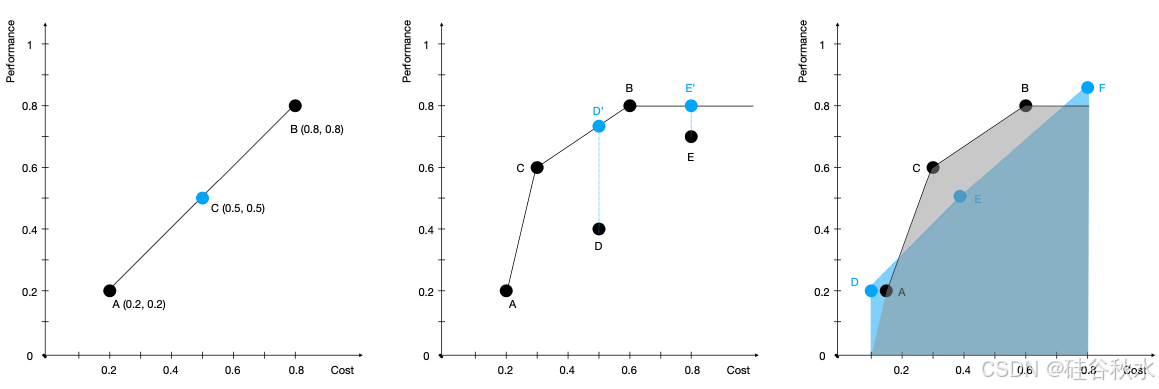
如图所示是路由操作例子:左图是线性插值,实现任何具体路由器之间成本性能权衡的过程;点 A 和 B 是具有不同输入参数的路由器;为了实现 A 和 B 的平均值,构建了路由器 C,它以 50% 的概率分别路由到 A 或 B,并且它在期望中执行 A 和 B 的平均值;中间图考虑点 A 到 E,可以构建由点 A、B 和 C 组成的非减凸包;D 和 E 可以用 A、B 和 C 的严格仿射组合替换;右图是ABC 和 DEF 两个路由系统(已经凸化,ABC 外推到 (0.1,0) 以进行公平比较);为了进行比较,分别将 A 和 B 插值到 cmin = 0.1 和 cmax = 0.8,然后计算由 cmax − cmin 归一化曲线下的面积以得出平均改善质量 AIQ。
对于给定的路由系统 R1(由在数据集 D 的 c − q 平面中绘制的 LLM 和路由器组成),可以概念化一个新的路由系统 R1~。这涉及构建路由器 Rθ1 , …, Rθk ,产生点 (c1 , q1 ), …, (ck , qk )。从这些点建立一个非递减凸包 Sndch ,对于范围 [cmin, cmax] 内的任何成本 c,在两个最近的成本点之间进行插值,可获得最佳性能。此过程有效地创建了一个涵盖整个域 [cmin, cmax] 的新路由系统。
鉴于已建立的框架,将零路由器 (Rzero) 定义为,基于其集结的非递减凸包,从 {LLM1 , … , LLMm } 中选择 LLM 的路由器。对于指定的成本 c,Rzero 提供 LLM 的概率组合,通过简单的数学驱动路由策略最大化预期输出质量。Rzero 是评估其他路由系统有效性的基本基准;只有当路由器的性能优于 Rzero 时,它才被视为重要。
鉴于比较框架对路由器结构的不可知性,路由系统可以在 c-q 平面上产生一组可能具有非确定性和非参数的各种点,从而使直接比较变得复杂。利用前面描述的方法,有能力将这些不同的点压缩为一个简化的函数(具体来说,是一个非递减凸包),然后将此表示提炼为一个封装系统特征的单一指标。
路由系统通常会在成本-质量(c-q)平面上生成多个点,这使得比较底层系统变得困难。但是,该框架允许将这些非参数点转换为更简单的函数,具体来说是一个非递减凸包,可以用单个数值来表征。
在预测方法中,考虑两种不同的路由系统(例如 KNN 和基于 MLP 的路由器),Rθ以及 Rλ。为了比较它们的有效性,从 Θ、Λ 中采样来参数化它们以生成一组点:Rθ1、…、Rθk 和 Rλ1、…、Rλk。然后,为这两个组构建一个非递减凸包,Rθ 和 Rλ 定义在共享域 [cmin,cmax] 上。
数据集 ROUTERBENCH,包含广泛的任务,比如常识推理、基于知识的语言理解、对话、数学、编码和检索增强生成 (RAG)。ROUTERBENCH 利用现有数据集构建,这些数据集在评估领先的 LLM 时被广泛认可和使用,例如 GPT-4、Gemini (Team et al., 2023) 和 Claude (Anthropic, 2023)。这种方法确保 ROUTERBENCH 能够代表主流 LLM 性能评估相关的各种挑战和要求。
具体来说,KNN 路由器识别训练集 Dtrain 中的 k 个最近样本并选择 LLMi 来获得估计性能得分ij ,从而展示该子集内的最佳性能。对于 MLP 路由器,训练一组 MLP 模型来预测性能。
非预测路由器从一系列大语言模型 (LLM) 中生成答案,评估这些答案,并根据评估结果做出路由决策。从 (Chen et al., 2023; Wang et al., 2023) 中汲取灵感,引入一个级联路由器,它由总成本参数 T 和一系列 m 个 LLM 组成,记为 LLMj : text → text,按计算成本和预期准确度从低到高排序。其操作的一个关键组成部分是评分函数 g : text → [0, 1] 与阈值 t(“判断”)配对。收到请求后,它首先由 LLM1 处理。如果 g(o1)>t,则选择输出 o1,并且该过程终止;否则,如果累积成本仍然小于总成本 T,则路由器继续执行序列中的下一个 LLM,如果不是,则返回当前输出。尽管在生产环境中为特定任务开发有效的评分函数 g 存在挑战,但这里路由器拥有对最终得分的完美了解,使其能够始终如一地选择最具成本效益的模型,从而产生令人满意的响应(类似于预言机)。为了更准确地模拟现实世界的性能,引入了一个错误参数 ε ∈ [0, 1]。
非预测路由器的一个变型是过度生成和重新排序,它从 LLM 生成所有潜在结果,评估每个结果,并输出由指定奖励函数确定的最佳结果。由于成本高昂,其实际应用受到限制。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









