










24年8月来自哥伦比亚大学的论文“Large Language Model Agent in Financial Trading: A Survey”。
交易是一项竞争激烈的任务,需要策略、知识和心理毅力的结合。随着大语言模型 (LLM) 的成功,将 LLM 智体的智能应用于这一竞争领域,并了解它们是否能胜过专业交易员,这工作具有吸引力。本综述全面回顾当前使用 LLM 作为金融交易智体的研究。总结了智体中使用的通用架构、数据输入和 LLM 交易智体在回测中的表现以及这些研究中提出的挑战。
大语言模型 (LLM) 的最新进展彻底改变了自然语言处理的研究,并在为自主智体提供动力方面展现出巨大的潜力 [46]。LLM 智体已应用于各个领域,例如医疗保健 [32] 和教育 [59]。此外,金融领域也对 LLM 应用进行了大量探索 [23, 26]。开发由 LLM 驱动的智体以用于金融市场交易的趋势,正在兴起。专业交易员需要处理来自各种来源的大量信息并快速做出决策。因此,LLM 非常适合这一角色,因为它们能够快速处理大量信息并生成有见地的摘要。
在设计基于 LLM 智体时,架构是一个至关重要的方面,它通常由智体的目标决定。一般来说,交易智体的主要目标是通过特定时期内的交易决策来优化回报。此外,其他与风险相关的指标对于评估智体绩效也至关重要,虽然有基于 LLM 智体专为各种金融任务而设计,例如总结金融新闻 [1] 或充当财务顾问 [21],但重点关注旨在实现投资回报的交易智体,因为这构成了该领域研究的大部分。
架构大致可分为两类:LLM 作为交易者和 LLM 作为 Alpha 挖掘者。LLM 交易者智体利用 LLM 直接生成交易决策(即买入、持有、卖出)。另一方面,Alpha 挖掘智体利用 LLM 作为有效工具来产生高质量的 alpha 因子,随后将其集成到下游交易系统中。如图显示了这些架构的层次结构和发展情况。
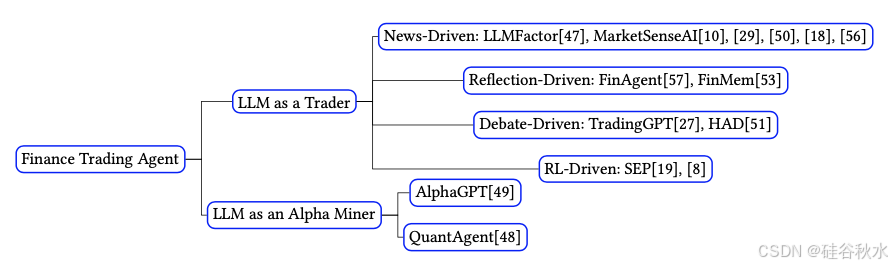
LLM 交易智体的架构侧重于利用 LLM 直接做出交易决策。这些系统旨在分析大量外部数据,例如新闻、财务报告、股票价格,并从这些数据中提炼信息以生成买入或卖出信号。 LLM 作为交易智体的子类,包括新闻驱动、反思驱动、辩论驱动和强化学习 (RL) 驱动的智体。
新闻驱动架构,是最基本的类型,其中个股新闻和宏观经济更新被整合到提示上下文中。然后指示 LLM 预测下一个交易期的股价走势。现有研究 [29, 50] 评估了闭源 LLM(例如 GPT3.5/4)和开源 LLM(例如 Qwen[3]、Baichuan[52] 等)在金融情绪分析中的表现。他们还根据这些情绪分数对简单的长做空策略进行了回测,证明了使用这种策略进行交易的有效性。此外,[18, 56] 研究了专门针对金融相关数据集进行微调的 LLM(FinGPT、OPT 等)的性能,并通过将 LLM 与领域特定知识相结合证明了进一步的改进。
反思驱动的架构,其中反思[38] 使用 LLM 总结基于提取的记忆构建。它是从原始记忆和观察中逐步聚合的高级知识和见解。这种反思用于做出交易决策。FinMem [53] 引入了具有分层记忆和特征的交易智体。原始输入(例如每日新闻和财务报告)被汇总到记忆中。当新的观察结果出现时,相关记忆将被检索并与这些观察结果相结合以产生反思。记忆和反思都存储在分层的记忆桶中。在交易阶段,决策模块将检索和利用这些记忆和反思来生成最终的交易决策。检索方法考虑了信息的时效性、相关性和重要性。
辩论驱动架构,其中LLM 之间的辩论是一种增强推理和事实有效性的有效方法。这种方法也被 LLM 金融智体广泛采用。[51] 提出了一个异构辩论框架,其中具有不同角色的 LLM 智体(即情绪智体、巧语智体、依属智体等)相互辩论,从而提高了新闻情绪分类性能。TradingGPT[27] 提出了一种与 FinMem[53] 类似的架构,但增加了一个步骤,即智体之间就彼此的行为和反思进行辩论,从而提高了反思的鲁棒性。
RL驱动架构,其中强化学习方法(例如 RLHF [37] 和 RLAIF [22])已被证明能够有效地将 LLM 输出与预期行为保持一致。然而,一个挑战是如何高效、系统地获得高质量的反馈。在金融交易中,回溯测试是一种经济有效的方法来生成有关交易决策的高质量反馈,并且直观地可以作为强化学习中的奖励来源。SEP [19] 提议在交易智体中利用带有记忆和反思模块的强化学习。这种方法利用从金融市场历史中得出的一系列正确和不正确的预测来完善 LLM 在现实世界市场的预测。
另一个重要类别涉及使用 LLM 作为 Alpha 挖掘的智体,其中 LLM 生成 alpha 因子而不是直接做出交易决策。QuantAgent [48] 展示了这种方法,它利用 LLM 的能力通过内循环-外循环架构生成 alpha 因子。在内循环中,笔者智体从人类交易员那里获取一般想法并生成脚本作为其实现。判断智体提供反馈以改进脚本。在外循环中,提交的代码在现实世界市场中进行测试,交易结果用于增强判断智体。事实证明,这种方法使智体能够以合理的效率逐步接近最佳行为。在后续研究中,AlphaGPT[49] 提出了一种用于 alpha 挖掘的人机循环框架。该方法在类似的架构和实验环境中实例化了一个 alpha 挖掘智体。这两项研究都证明了 LLM 驱动的 alpha 挖掘智体系统的有效性和效率,这尤其有价值,因为 alpha 挖掘是一项资源密集型工作。
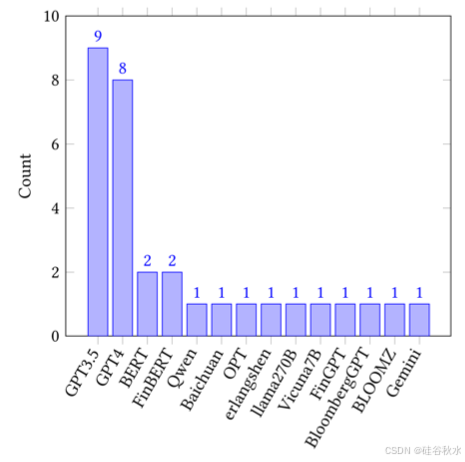
最后,为了研究不同 LLM 模型的使用情况,绘制 LLM 模型的直方图,如图 所示,提供频谱概览。值得注意的是,OpenAI 的模型(尤其是 GPT-3.5 和 GPT-4)因其出色的总体性能而占据研究使用主导地位。此外,开源模型选择呈现长尾分布,满足了更灵活和更专业的开发需求。值得注意的是,GPT3.5 的使用频率甚至高于 GPT4,表明人们更偏爱其成本效益和更低的延迟。
LLM 驱动的交易智体严重依赖各种数据源来生成交易信号。各种智体使用的多种数据类型,将其分为四大类:
数值数据:包括数字或统计数据,例如股票价格和交易量。
文本数据:基于文本的信息,例如股票新闻、财务报告。
视觉数据:包括与金融市场相关的图表和图像。
模拟数据:包括来自模拟股票市场和新闻事件的数据。
LLM 通过分析市场新闻或财务报表等文本数据来生成简单的交易信号,例如“买入”、“持有”、“卖出”。在 FinMem[53] 和 FinAgent[57] 中,信号直接用于特定股票的交易行为。然而,在管理包含多只股票的投资组合时,一种常见的方法是使用基于排名的策略。这些策略需要数字分数来对股票进行排名,并根据这些分数的大小分配资金。在 FinLlama[20] 中,标准普尔 500 指数中的所有股票都由 LLM 排名,前 35% 被分配为多头仓位,后 35% 被分配为空头仓位。[18, 29] 采用了类似的方法,其中长做空策略在回测中表现出优于多头和空头策略。另一方面,[50] 将多头仓位分配给总体新闻情绪正面的股票,将空头仓位分配给情绪负面的股票,而不考虑情绪分数的大小。这种方法没有充分利用信号,导致在他们的实验中观察到多空策略的表现比只做多策略更差。在 [56] 中,股票根据其信号排名进行分组,排名靠前的股票组与其他股票相比表现出最佳回报。
在执行交易策略时,股票通常要么相等加权,要么基于市值大小。在 [18] 和 [29] 中,按市值加权的投资组合回报略高于等权投资组合。推测由于新闻报道的偏见,大盘股公司的文本信号质量优于小盘股公司。
为了评估 LLM 驱动智体的性能,大多数工作都使用真实市场数据进行回测。对于在单一股票投资组合上评估的智体,选择可访问新闻数据量最大的股票进行测试。例如,TSLA、AMZN、MSFT、COIN、NFLX、GOOGL、META、PYPL 等股票被选中在 [53]、[57] 和 [60] 中进行交易。对于管理多股票投资组合的智体,通常选择指数成分股,例如来自 SP500[45] 和 CSI300[5] 的股票。
大多数基于智体的模型仅在股票市场上进行回测。在使用真实市场数据进行回测的 14 篇论文中,9 篇关注美国股市,5 篇关注中国市场。只有 FinAgent [57] 将其回测扩展到加密货币市场,特别是交易 ETH [4]。
虽然 LLM 智体在回测期间表现出色,但短暂且单一的回测期可能会降低结果的可信度。
参考文献
[8] Y Ding, S Jia, T Ma, and et al. 2023. Integrating Stock Features and Global Information via Large Lan- guage Models for Enhanced Stock Return Prediction. arXiv:2310.05627
[29] A Lopez-Lira and Y Tang. 2023. Can ChatGPT Forecast Stock Price Movements? Return Predictability and Large Language Models. arXiv:2304.07619
[53] Y Yu, H Li, Z Chen and et al. 2023. FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design. arXiv:2311.13743
[57] W Zhang, L Zhao, H Xia, and et al. 2024. A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist. arXiv:2402.18485


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









