










22年10月来自NYU和Meta的论文“Holo-Dex: Teaching Dexterity with Immersive Mixed Reality”。
教学机器人的一个基本挑战,是提供有效的界面让人类老师向机器人展示有用的技能。这一挑战在灵巧操作中更加严峻,因为教授高维、接触丰富的行为通常需要隐秘(esoteric)的遥控工具。这项工作提出 HOLO-DEX,一个灵巧操作的框架,通过商用 VR 耳机将老师置于沉浸式混合现实中。耳机上的高保真手势估计器,用于遥控机器人并收集各种通用灵巧任务的演示。根据这些演示,用强大的特征学习结合非参数模仿来训练灵巧技能。对六种常见灵巧任务(包括手中旋转、旋转和开瓶)的实验表明,HOLO-DEX 既可以收集高质量的演示数据,又可以在数小时内训练技能。实验中训练的技能可以在训练中未见过目标上表现出泛化能力。
如何为机器人收集训练数据?一种选择是通过自监督数据收集策略在机器人上收集数据。虽然这会产生稳健的行为 [15, 16, 17, 18],但即使对于相对简单的操作任务,它们也常常需要数千小时的大量现实世界交互 [19]。另一种选择是在模拟数据上进行训练,然后转移到真实机器人 (Sim2Real)。这使得学习复杂的机器人行为的速度比机器人学习快几个数量级 [20, 21]。然而,设置模拟机器人环境和指定模拟器参数通常需要广泛的领域专业知识 [22, 23]。第三种更实用的数据收集方法,是请人类教师提供演示 [24, 25]。然后可以训练机器人快速模仿演示的数据。这种模仿方法最近在各种具有挑战性的灵巧操作问题中显示出希望 [26, 27, 28]。然而,这些研究大多存在一个根本性的局限性——收集灵巧机器人的高质量演示数据非常困难!它们要么需要昂贵的手套 [29],要么需要大量标定 [27],要么受到单目遮挡 [28]。
由于其高维动作空间,使用灵巧的多指机器人手学习复杂技能一直是一项长期挑战 [54,55,56,57]。基于模型的 RL 和控制方法已在旋转物体和手部操作等任务上取得了显著成功 [58,59]。同样,无模型 RL 方法表明 Sim2Real 可以实现令人印象深刻的技能,例如手中魔方旋转和 Rubik 魔方的面旋转 [20,21]。然而,这两种学习方法都需要手工设计奖励函数以及系统识别 [58] 或特定于任务的训练程序 [21]。再加上训练时间长(通常需要数周 [20,21]),使灵巧操作难以扩展到一般任务。
为了解决先前基于学习的方法样本效率低的问题,一些研究开始研究模仿学习 [60, 61]。在这里,只需进行少量演示,就可以在几个小时内训练模拟策略。最近,这种基于模仿的方法在真实的机器人手上取得了成功 [28]。
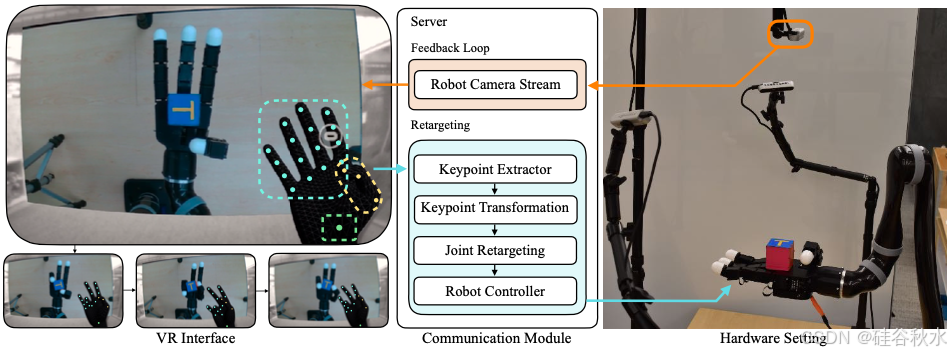
HOLO-DEX 通过改进教学过程并展示其在各种手部操作任务中的实用性,进一步推进模仿学习。HOLO-DEX 分为两个阶段。在第一阶段,人类教师使用虚拟现实 (VR) 耳机向机器人提供演示。此阶段包括创建一个用于教学的虚拟世界、估计教师的手势、将教师的手势重定位到机器人手上并最终控制机器人手。在第一阶段收集了一些演示后,HOLO-DEX 的第二阶段将学习视觉策略来解决演示的任务。如图所示:HOLO-DEX (a) 将人类教师置于沉浸式混合现实世界中来收集高质量的演示数据,然后 (b) 从少数这些演示中学习视觉策略来解决灵巧的操作任务。

用 Meta Quest 2 VR 耳机将人类教师置于虚拟世界中。耳机以 1832 × 1920 的分辨率和 72 Hz 的刷新率将人类置于虚拟环境中。这款耳机的基本版本价格实惠,为 399 美元,重量相对较轻,为 503 克。这些功能让老师可以舒适地操作。重要的是,Quest 2 的 API 接口允许创建自定义混合现实世界,在 VR 中可视化机器人系统以及诊断面板。虚拟场景的示例如下所述。
如图所示HOLO-DEX 远程操作模块概述。在 VR 界面中给定手部姿势,控制器将关键点数据传输到机器人的服务器,该服务器将人手关键点转换并重新定位到 Allegro Hand 机械手。然后将远程操作手的视觉反馈提供给 VR 耳机进行实时反馈。
如图所示三项任务的演示收集过程。对于每项任务,第一行显示用户在 VR 耳机内的视角,第二行显示相应的机械手配置。

由于 Quest 2 使用 4 个单色摄像头,其手势估计器 [48] 比单摄像头估计器 [64] 更加稳健。由于摄像头是内部标定的,因此不需要以前的多摄像头遥操作框架 [27] 所需的专门标定程序。由于手势估计器集成在设备中,它可以以 72Hz 的频率传输实时手势。灵巧遥操作的一个重大挑战是获得高精度和高频率的手势。HOLO-DEX 使用商用级 VR 耳机大大简化了这个问题。
老师的手势需要重新定位到机械手上。首先计算老师手上的各个关节角度。有了这些关节角度,一种简单的重定位方法是直接命令机器人关节到相应的角度。
在 HOLO-DEX 第一阶段收集数据后,进入第二阶段,基于这些数据训练视觉策略。采用模仿最近邻 (INN) 算法进行学习。在先前的工作中,INN 证明可以在 Allegro 手上产生基于状态的灵巧策略 [28]。HOLO-DEX 更进一步,证明这些视觉策略可以推广到各种灵巧操作任务中的新目标。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









